类神经网络训练不起来怎么办
书接上回,为什么Optimization会失败呢?
Local Minima 和 Saddle Point
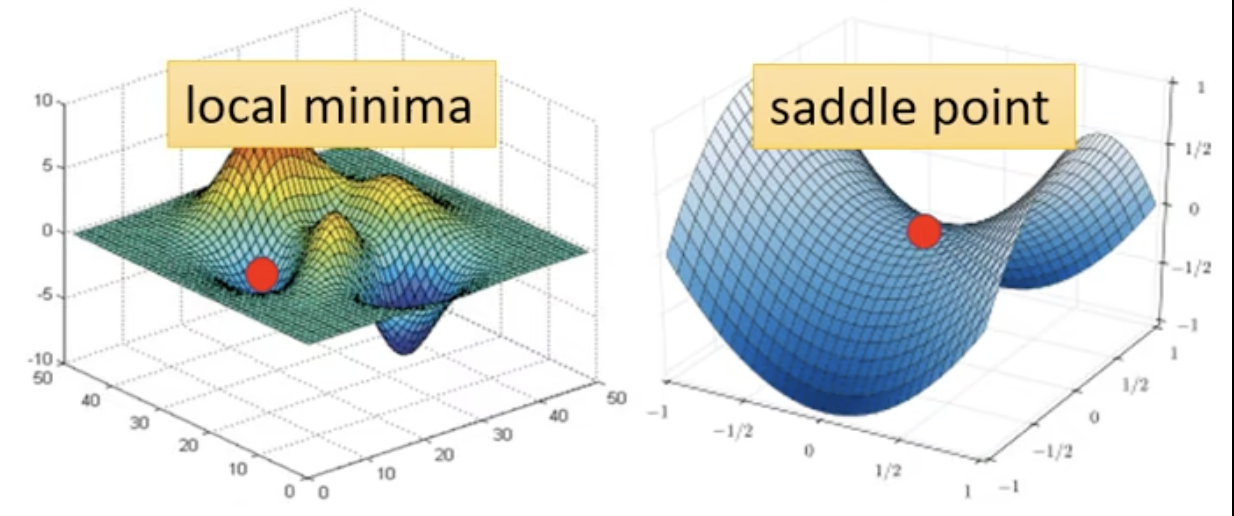
微分为0的点统称为critical point,那么怎么知道一个点是局部最小值还是鞍点呢?
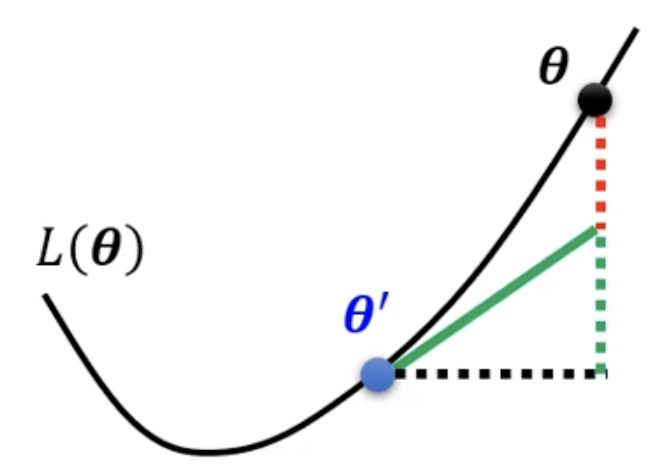
$L(\theta)$ around $\theta = \theta’$ can be approximated below:
\[L(\theta) \approx L(\theta') + (\theta - \theta')^T g + \frac{1}{2} (\theta - \theta')^T H (\theta - \theta')\]Gradient $g$ is a vector:
\[g = \nabla L(\theta')\] \[g_i = \frac{\partial L(\theta')}{\partial \theta_i}\]Hessian $H$ is a matrix:
\[H_{ij} = \frac{\partial^2}{\partial \theta_i \partial \theta_j} L(\theta')\]在critical point:$(\theta - \theta’)^T g$ 为0,我们可以根据$\frac{1}{2} (\theta - \theta’)^T H (\theta - \theta’)$这一项判断函数在这里长什么样
方便起见,我们把$(\theta - \theta’)$用$v$表示,
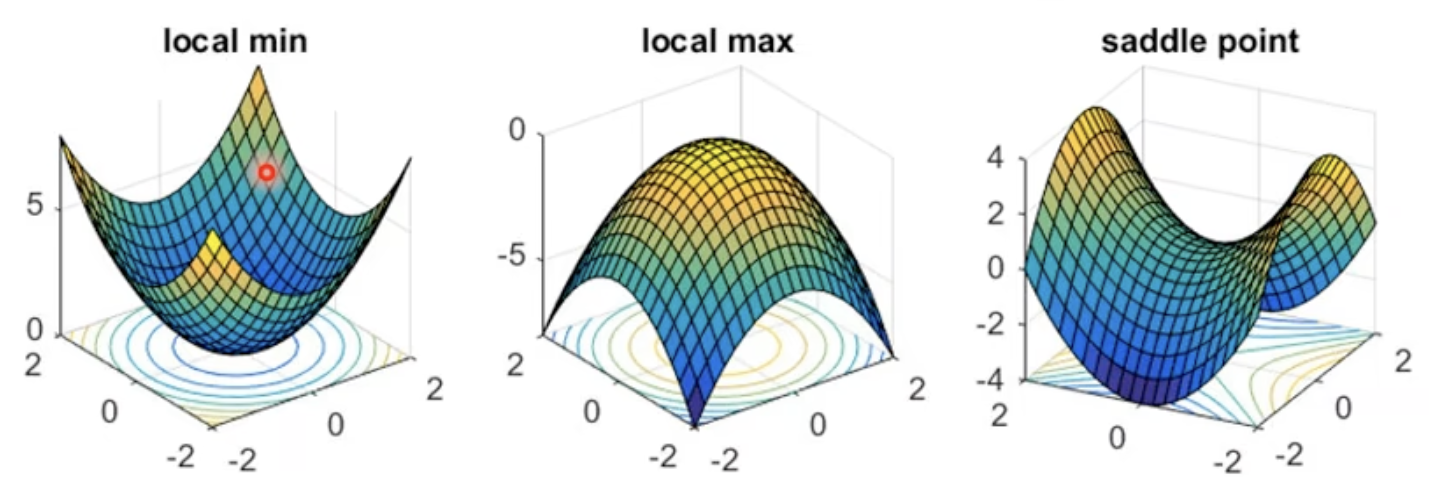
如果对于任意的$v$,都有$v^THv>0$,说明在$\theta’$附近,有$L(\theta)>L(\theta’)$ — Local minima — H是positive definite = 所有特征值都是正数
如果对于任意的$v$,都有$v^THv<0$,说明在$\theta’$附近,有$L(\theta)<L(\theta’)$ — Local maxima — H是negative definite = 所有特征值都是负数
如果有时$v^THv>0$,有时$v^THv<0$ — Saddle point 鞍点 — 特征值有正有负
$H$也许可以告诉我们参数可以改进的方向!
在鞍点,假设$u$是$H$的特征向量,$\lambda$是$u$的特征值,那么:
\[u^THu=u^T(\lambda u)=\lambda\lVert u \rVert^2\]代入二阶近似: \(L(\theta' + u) \approx L(\theta') + \frac{1}{2} u^T H u= L(\theta') + \frac{1}{2} \lambda \|u\|^2\)
说明,只要找出$\lambda<0$,让$\theta=\theta’+\epsilon u$,就可以让Loss变小
Error surface(误差曲面 / 损失曲面):是模型参数空间中的一个多维曲面,它描述了每组参数对应的 Loss 或 Error 值,梯度下降就是沿着 error surface 下降的过程
在n维空间里的local minima,在n+1维(或者更高维度)会不会只是一个saddle point了呢?
Batch 和 Momentum
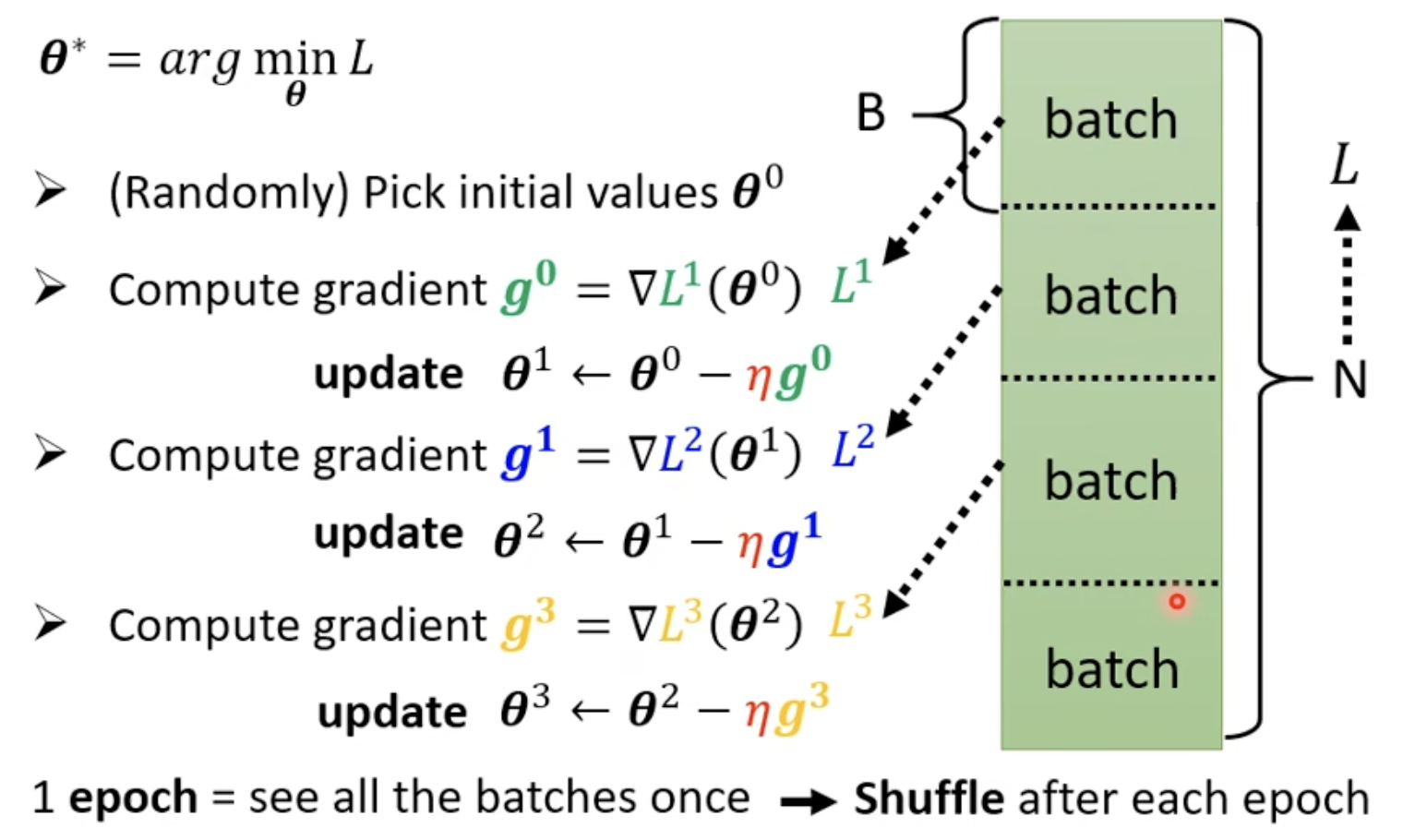
Shuffle:每一个epoch划分的batch都不一样