类神经网络训练不起来怎么办
书接上回,为什么Optimization会失败呢?
Local Minima 和 Saddle Point
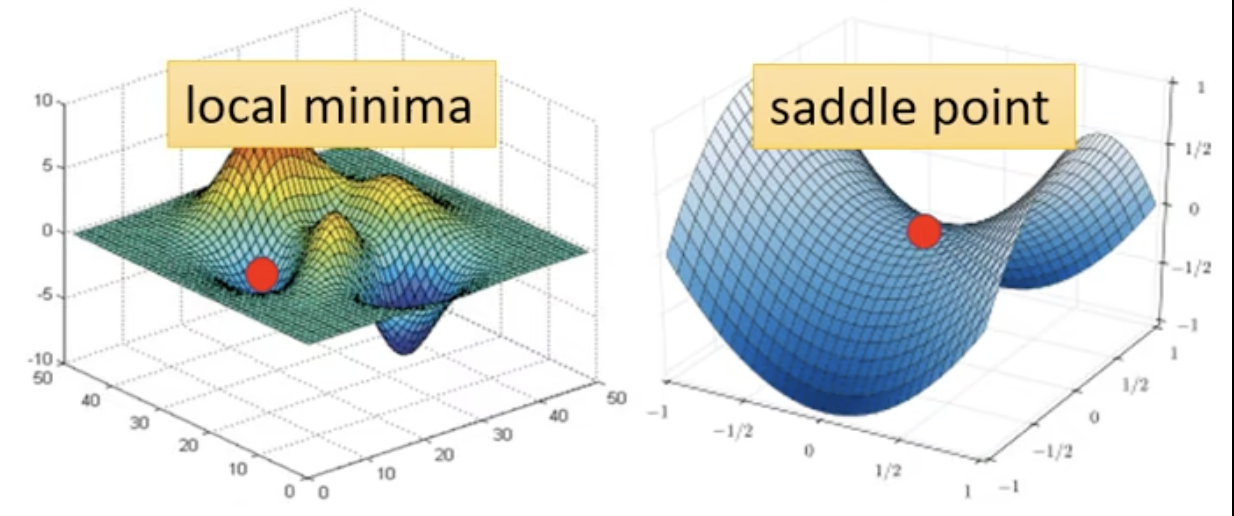
微分为0的点统称为critical point,那么怎么知道一个点是局部最小值还是鞍点呢?
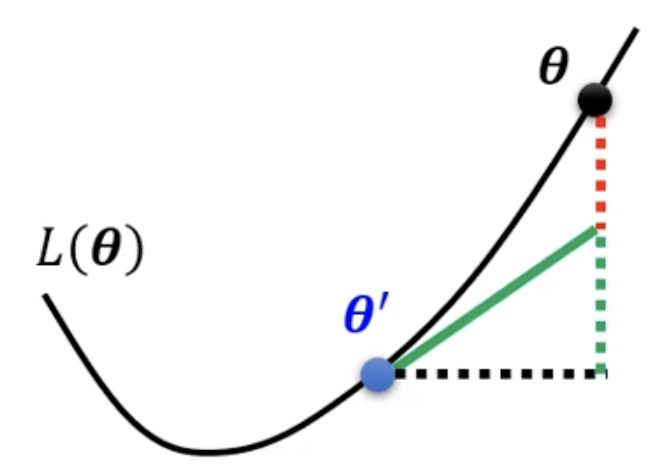
$L(\theta)$ around $\theta = \theta’$ can be approximated below:
\[L(\theta) \approx L(\theta') + (\theta - \theta')^T g + \frac{1}{2} (\theta - \theta')^T H (\theta - \theta')\]Gradient $g$ is a vector:
\[g = \nabla L(\theta')\] \[g_i = \frac{\partial L(\theta')}{\partial \theta_i}\]Hessian $H$ is a matrix:
\[H_{ij} = \frac{\partial^2}{\partial \theta_i \partial \theta_j} L(\theta')\]在critical point:$(\theta - \theta’)^T g$ 为0,我们可以根据$\frac{1}{2} (\theta - \theta’)^T H (\theta - \theta’)$这一项判断函数在这里长什么样
方便起见,我们把$(\theta - \theta’)$用$v$表示,
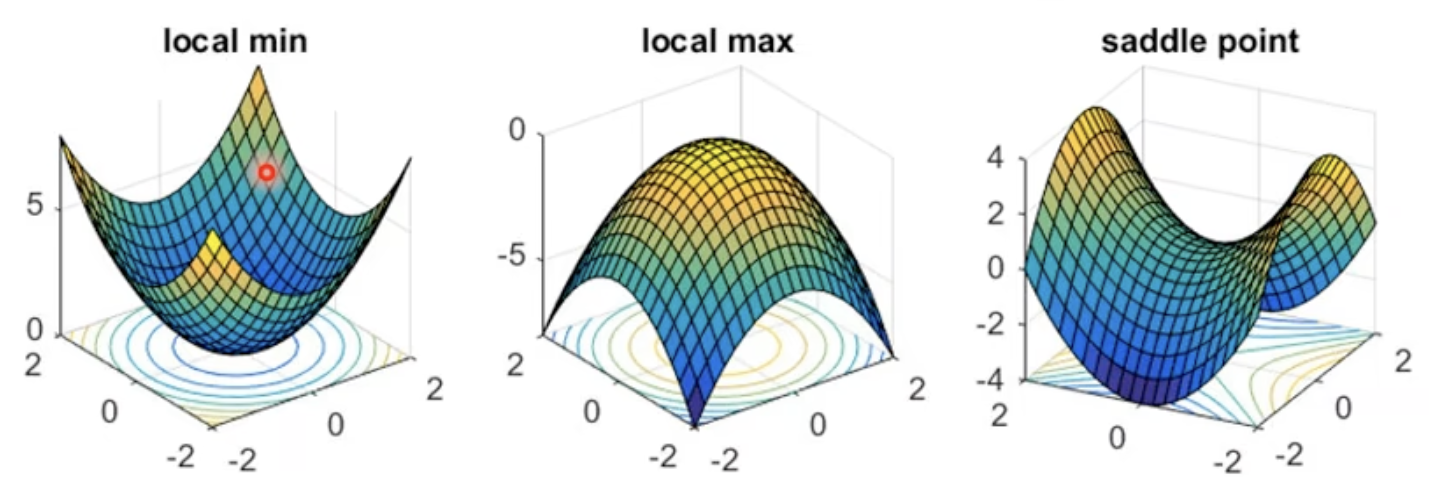
如果对于任意的$v$,都有$v^THv>0$,说明在$\theta’$附近,有$L(\theta)>L(\theta’)$ — Local minima — H是positive definite = 所有特征值都是正数
如果对于任意的$v$,都有$v^THv<0$,说明在$\theta’$附近,有$L(\theta)<L(\theta’)$ — Local maxima — H是negative definite = 所有特征值都是负数
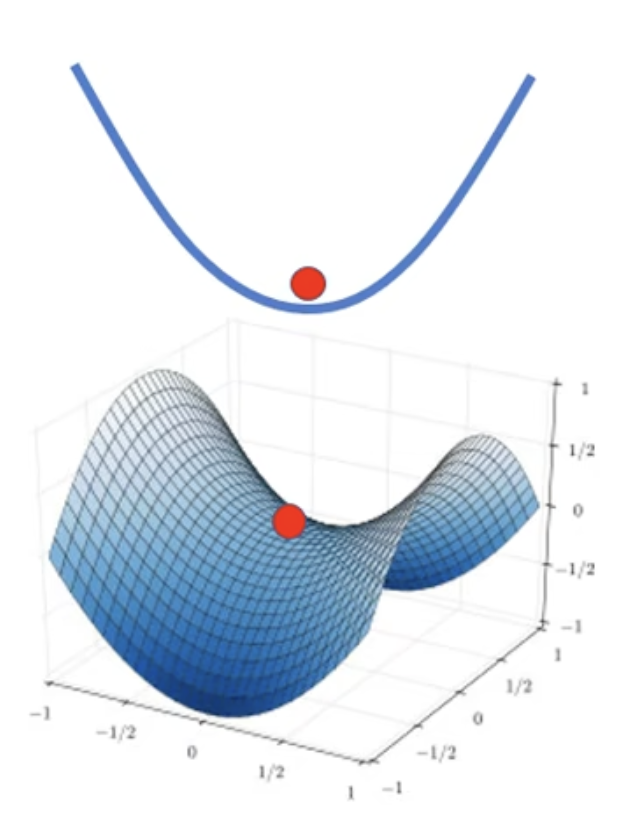
如果有时$v^THv>0$,有时$v^THv<0$ — Saddle point 鞍点 — 特征值有正有负
$H$也许可以告诉我们参数可以改进的方向!
在鞍点,假设$u$是$H$的特征向量,$\lambda$是$u$的特征值,那么:
\[u^THu=u^T(\lambda u)=\lambda\lVert u \rVert^2\]代入二阶近似: \(L(\theta' + u) \approx L(\theta') + \frac{1}{2} u^T H u= L(\theta') + \frac{1}{2} \lambda \|u\|^2\)
说明,只要找出$\lambda<0$,让$\theta=\theta’+\epsilon u$,就可以让Loss变小
Error surface(误差曲面 / 损失曲面):是模型参数空间中的一个多维曲面,它描述了每组参数对应的 Loss 或 Error 值,梯度下降就是沿着 error surface 下降的过程
在n维空间里的local minima,在n+1维(或者更高维度)会不会只是一个saddle point了呢?
Batch 和 Momentum
Batch
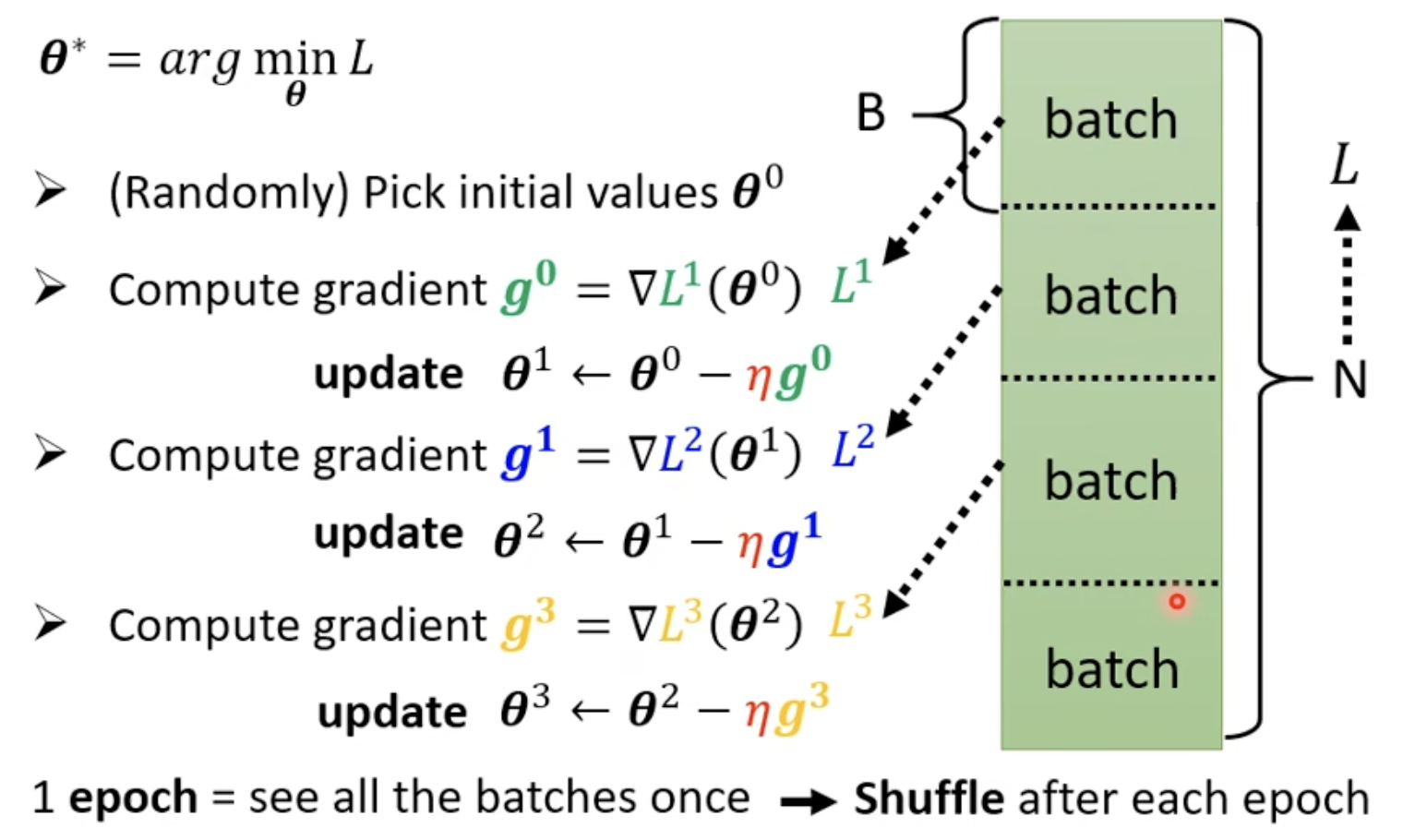
Shuffle:每一个epoch划分的batch都不一样
考虑到平行运算,batch size较大的epoch花的时间可能更短!GPU 有大量并行计算单元,一个 batch 内的样本可以同时处理。在 batch 不超过 GPU 容量前,增大 batch size 的时间代价几乎为零。超过后受显存和调度瓶颈,时间才开始上升。
关于 GPU 并行:增大 batch size 在 GPU 上几乎不增加每次更新的时间(并行计算),但超过一定上限后受显存和通信瓶颈限制,代价才显著上升。所以 “小 batch 每次更新更快” 这个优势在 GPU 上并不成立——真正的优势是更多更新次数和更好的泛化。

“更新次数多”意味着模型参数在一个 epoch 内被调整了更多次,等于在同样看完一遍数据的前提下,得到了更多次“练习机会”。
这也是为什么小 batch 训练虽然每次梯度估计不准,但总信息利用效率可能更高。

mini-batch 的梯度是真实梯度的无偏估计(期望值相同),但每次有随机误差。这个误差恰恰让优化轨迹带有随机性,能跳出某些局部结构
为什么噪声帮助优化?
从三个角度理解“噪声对优化有益”:
角度一:逃离鞍点 鞍点处真实梯度为零,但 mini-batch 梯度不为零(每个 batch 对应略不同的 loss 面)。这个随机扰动自然地推离鞍点,无需任何额外操作。
角度二:逃离 sharp local minima full batch 精确地计算梯度,一旦落入某个局部最小值就被精确地困住了。mini-batch 由于每次 loss 面略有不同,对某个 batch 而言的最小值对下一个 batch 不是,有机会爬出来。
角度三:更多更新 = 更多探索机会小 batch 在一个 epoch 内更新 $N/b $ 次,而大 batch 只更新 1 次。即使每次更新方向不那么准确,更多的探索本身就提高了找到好区域的概率。


总结:
| 小batch | 大batch | |
|---|---|---|
| 每次更新速度 | 更快(样本少) | 更慢(但GPU并行抵消) |
| 每个 epoch 更新次数 | 多(N/b 次) | 少(1 次) |
| 每个epoch耗费时间 | 多 | 少 |
| 梯度估计 | 嘈杂(噪声大) | 稳定(精确) |
| 优化 & 泛化 | 更好(找 flat min) | 更差(困于 sharp min) |
Momentum
物理世界里,一个球滚下山,遇到小坑不会停住——惯性让它越过去。Momentum 把这个物理直觉引入梯度下降。
普通 GD:每一步只看当前梯度。 \(\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - \eta \mathbf{g}_t\) 
Momentum GD:每一步的移动 = 上一步的移动方向 + 当前梯度的修正。
\[\mathbf{m}_{t+1} = \lambda \mathbf{m}_t - \eta \mathbf{g}_t\]展开 $\mathbf{m} $ 就会发现它是所有历史梯度的 指数加权移动平均:
\[\mathbf{m}_t = -\eta(\mathbf{g}_{t-1} + \lambda \mathbf{g}_{t-2} + \lambda^2 \mathbf{g}_{t-3} + \cdots)\]越久远的梯度权重越低(乘以更多次 $\lambda < 1 $)——这就是“记忆有衰减的历史”

总结:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Step 3: Optimization (Gradient Descent)
梯度变小 → 三种原因
├── 平坦区域(plateau)
├── 鞍点(saddle point)← 高维中最常见
└── 局部最小值(local minima)← 高维中其实很稀少
↓ 如何判断?
Hessian 矩阵的特征值
↓ 如何应对?
├── Mini-batch:噪声 + 更多更新次数 + flat minima
└── Momentum:历史梯度加权求和,提供惯性
↓ 两者结合
SGD with Momentum(实际工程的基础)
↓ 进一步
Adam = Momentum + 自适应 learning rate
Adaptive Learning Rate
训练停滞不等于遇到 critical point——真正的原因更多是 learning rate 设置不对。
一个凸函数(理论上最好优化的情形,只有一个全局最小值)用固定 $\eta $,常常要么震荡发散,要么 10 万步还没走到。问题不在 loss 曲面的形状, 在于 $\eta $ 本身。

我们一开始是这样更新参数的:
\[\theta_i^{t+1} \leftarrow \theta_i^t - {\eta} g_i^t\]一个参数的更新变成:
\[\theta_i^{t+1} \leftarrow \theta_i^t - \frac{\eta}{\sigma_i^t} g_i^t\]$\sigma_i^t $ 是 每个参数、每个时间步独立计算的——它除掉了 $\eta $,相当于给每个参数一个自适应的有效步长。现在问题变成:$\sigma_i^t $ 怎么算?
Adagrad — 用全历史梯度的 RMS
\[\sigma_i^t = \sqrt{\frac{1}{t+1} \sum_{\tau=0}^{t} (g_i^\tau)^2}\]这是历史上所有梯度的均方根(Root Mean Square)。

直觉:某个参数如果一直收到大梯度,说明这个方向的 loss 曲面很陡,需要小步走;如果一直收到小梯度,说明这个方向很平坦,需要大步走。$\sigma $ 积累了这个历史信息,自动校正步长。
代入更新公式看看发生了什么:
\[\frac{g_i^t}{\sigma_i^t} = \frac{g_i^t}{\sqrt{\frac{1}{t+1}\sum (g_i^\tau)^2}}\]- $g$ 大,$\sigma $ 也大 → $g/\sigma $ 被压缩 → 实际步长变小
- $g$ 小,$\sigma $ 也小 → $g/\sigma $ 被放大 → 实际步长变大
注意:$g/\sigma $ 这个比值消掉了梯度的绝对大小,只保留了 相对信息。换句话说,Adagrad 在某种程度上只考虑梯度的方向,而不是幅度。
Adagrad 的致命问题:$\sigma_i^t $ 是累积求和, 只增不减。随着训练进行,$\sigma $ 越来越大,有效步长 $\eta/\sigma $ 越来越趋近于零,训练后期会 完全停滞。
RMSProp — 用指数加权移动平均
\[\sigma_i^t = \sqrt{\alpha (\sigma_i^{t-1})^2 + (1-\alpha)(g_i^t)^2}, \quad 0 < \alpha < 1\]把累积平均换成指数加权移动平均(EWMA)。$\alpha $ 通常取 0.9 或 0.99,也可以根据“我认为现在的g有多重要”自行设置。
与 Adagrad 的区别:
| Adagrad | RMSProp | |
|---|---|---|
| 对历史的记忆 | 均等权重,永远记得 | 指数衰减,近期更重要 |
| $\sigma $ 的趋势 | 只增不减 | 可增可减 |
| 训练后期 | 步长 → 0,停滞 | 可自适应调整,不停滞 |
展开 RMSProp 的递推,可以看到每一步的梯度贡献是:
\[\sigma^2 \approx (1-\alpha)\left[g_t^2 + \alpha g_{t-1}^2 + \alpha^2 g_{t-2}^2 + \cdots\right]\]越久远的梯度权重以 $\alpha^k $ 指数衰减——这正是“对近期更敏感”的来源。
关键能力:当 loss 曲面的陡峭程度随位置变化时,RMSProp 可以动态响应。到了新的区域,历史梯度的影响逐渐消退,$\sigma $ 会重新适应当前地形。
Adam — RMSProp + Momentum
ref:ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION

Adam 同时维护两个量:
\[m_t = \beta_1 m_{t-1} + (1-\beta_1) g_t \quad \text{(一阶矩,momentum)}\]然后做偏差修正(bias correction):
\[\hat{m}_t = \frac{m_t}{1-\beta_1^t}, \quad \hat{v}_t = \frac{v_t}{1-\beta_2^t}\]最终更新:
\[\theta_t \leftarrow \theta_{t-1} - \frac{\alpha \hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon}\]为什么需要偏差修正? 初始 $m_0 = v_0 = 0 $,训练开始时 $m_t $ 和 $v_t $ 被 0 初始值严重压低,会低估真实的一阶和二阶矩。除以 $(1-\beta^t) $ 在 $t $ 小时放大修正、$t $ 大时趋近于 1 自动消失——这是一个精巧的工程补丁。
默认超参数:$\beta_1 = 0.9 $,$\beta_2 = 0.999 $,$\epsilon = 10^{-8} $。实践中几乎不需要调。
Learning Rate Scheduling:在时间维度上也自适应

即使有了自适应的 $\sigma $,全局 $\eta $ 还可以随训练进度调整:
\[\theta_i^{t+1} \leftarrow \theta_i^t - \frac{\eta^t}{\sigma_i^t} g_i^t\]
Learning Rate Decay:$\eta^t $ 随时间单调递减(指数、余弦、step 等)。直觉:训练初期需要大步探索,后期接近收敛,需要小步精调。
Warm Up:先增后减。训练最开始时,$\sigma_i^t $ 只基于极少量样本估计,方差很大,这时候 $\eta/\sigma $ 反而是不可信的。先用小 $\eta $ 让 $\sigma $ 积累足够的统计量,再放大 $\eta $ 开始正式训练。ResNet 和 Transformer 的原始论文都用了 warm up。【但还是更像一个黑科技】
整体框架总结
\[\theta_i^{t+1} \leftarrow \theta_i^t - \frac{\eta^t}{\sigma_i^t} m_i^t\]三个组件分工清晰:
- $m_i^t $(momentum): 决定方向——用历史梯度的加权和平滑方向,减少震荡
- $\sigma_i^t $(RMSProp): 决定步长大小——对每个参数独立缩放,陡峭的方向自动走小步
- $\eta^t $(scheduling): 决定全局节奏——训练初期探索,后期精调
Classification as Regression?
最朴素的想法:把类别编码成数字(class 1=1, class 2=2, class 3=3),然后用回归预测这个数字。
这有两个根本问题。第一,数字编码隐含了顺序关系——class 2 在 class 1 和 class 3 “之间”,但类别之间没有这种距离概念。第二,回归的输出是任意实数,而类别需要的是离散决策。
正确做法:用 one-hot vector 表示类别,让网络输出一个向量,每个维度对应一个类别的“得分”。
Class as One-hot Vector

这些绿色的 1 表示偏置项(bias)。
具体来说,每个加法节点(灰色的
\[r_i = \sum_j w_{ij} x_j + b_i\]+)做的事情是:其中那个 $b_i $ 就是偏置。但在图里,为了把偏置也统一画成”输入乘以权重”的形式,把它表示成一个 恒为 1 的输入节点,乘以一个可学习的权重 $b_i $。
所以绿色的 1 本质上是一个固定值为 1 的虚拟输入,它对应的权重就是偏置参数,会在训练中被梯度下降更新。这样做的好处是形式统一——偏置和普通权重在数学上可以用同一套矩阵运算来表达:
\[\mathbf{r} = W\mathbf{x} + \mathbf{b} \quad \Leftrightarrow \quad \mathbf{r} = [W \mid \mathbf{b}] \begin{bmatrix} \mathbf{x} \\ 1 \end{bmatrix}\]图里有两层这样的结构:右边的绿色 1 是隐藏层的偏置,左边的绿色 1 是输出层的偏置。
Soft-max
问题的起点
网络输出的 logits $y_1, y_2, y_3 $ 是任意实数,可正可负,可以很大。我们需要把它们转换成 概率,满足两个条件:每个值在 $(0,1) $ 之间,且所有值加起来等于 1。
朴素想法:直接除以总和,$y_i’ = y_i / \sum_j y_j $。问题:如果有负数,这个做法没有意义(分母可能为零,且负数没有概率意义)。
关键操作:先对每个 $y_i $ 取指数 $e^{y_i} $,把任意实数映射到正数,再归一化:
\[y_i' = \frac{e^{y_i}}{\sum_j e^{y_j}}\]这就是 Softmax。
为什么用 $e^x $ 而不是其他正函数?
取指数有三个好处:
一是指数函数处处可微,梯度下降可以工作;
二是指数放大了差距——较大的 $y_i $ 对应的 $e^{y_i} $ 会远大于较小的,使最大值的概率向 1 靠近,这符合“赢者通吃”的分类直觉;
三是与最大似然估计有深刻的数学联系

Softmax 的性质
$y_i’ $ 满足:每个值严格在 $(0,1) $ 之间(指数函数永远为正,且有限),且 $\sum_i y_i’ = 1 $(归一化的定义)。
“Soft-max”这个名字来自于它是 argmax 的可微近似:当某个 $y_i $ 远大于其他时,$y_i’ $ 趋近于 1,其余趋近于 0,这就是 argmax;但整个函数是光滑的,可以求梯度。
二分类时 Sigmoid = Softmax,严格证明
这是一个重要的等价关系。
Softmax 用于两个类别,logits 为 $y_1, y_2 $:
\[y_1' = \frac{e^{y_1}}{e^{y_1} + e^{y_2}}\]分子分母同除以 $e^{y_1} $:
\[y_1' = \frac{1}{1 + e^{y_2 - y_1}} = \frac{1}{1 + e^{-(y_1 - y_2)}}\]令 $z = y_1 - y_2 $(两个 logit 的差值),得到:
\[\boxed{y_1' = \frac{1}{1 + e^{-z}} = \sigma(z)}\]这正是 Sigmoid 函数,其中输入是两个 logit 之差。
物理意义:二分类时,我们不需要分别建模 $y_1 $ 和 $y_2 $,只需要建模它们的差 $z = y_1 - y_2 $。这个差决定了倾向哪个类别,通过 Sigmoid 压缩到 $(0,1) $ 就是类别 1 的概率。这就是为什么二分类只需要网络输出一个标量,接 Sigmoid 即可。
Sigmoid 是 Softmax 在 $N=2 $ 时的特例,两者本质上做同一件事。
Loss:为什么用 Cross-entropy 而不用 MSE?
两种 Loss 的定义
对于一个样本,label 为 one-hot 向量 $\hat{y} $,网络输出概率 $y’ $:
\[e_{\text{MSE}} = \sum_i (\hat{y}_i - y_i')^2\]由于 $\hat{y} $ 是 one-hot,cross-entropy 化简为:若真实类别是 $k $,则 $e_{\text{CE}} = -\ln y_k’ $,即只关心正确类别的概率的对数。
\[e_\text{cross-entropy} = -\sum_i \hat{y}_i \ln y'_i\]Cross-entropy 为何胜出:从梯度的角度

考虑这样一个情况:网络输出 $y_3 = -1000 $(对类别 3 极度自信地排除),正确答案是 class 1。
- softmax 之后:$y_1’ \approx 1 $,$y_2’ \approx 0 $,$y_3’ \approx 0 $
- MSE loss:$(\hat{y}_1 - y_1’)^2 + (\hat{y}_2 - y_2’)^2 + (\hat{y}_3 - y_3’)^2 \approx 0 $, loss 已经很小
看起来很好?但问题在于:这个点其实还在错误位置($y_3 = -1000 $ 是不正常的极端值,说明训练过程出了问题),但 MSE 的梯度也很小, 梯度下降不知道要修正,训练卡死。
Cross-entropy loss:$-\ln y_1’ $。如果 $y_1’ $ 还不够接近 1,loss 就会有明显的梯度,推动训练继续改进。
Cross-entropy 与最大似然的等价性
这不只是一个工程选择,有深刻的统计理由。
把网络的输出 $y_i’ $ 理解为概率模型 $P(\text{class}=i \rvert x) $,对训练集做最大似然估计:
\[\max_\theta \prod_n P(\hat{y}^{(n)} | x^{(n)}) = \max_\theta \sum_n \ln P(\hat{y}^{(n)} | x^{(n)}) = \max_\theta \sum_n \ln y_{\hat{k}}^{(n)'}\]其中 $\hat{k} $ 是第 $n $ 个样本的正确类别。最大化这个等价于最小化:
\[-\sum_n \ln y_{\hat{k}}^{(n)'} = \sum_n e_{\text{CE}}^{(n)}\]最小化 cross-entropy = 最大似然估计。这赋予了 cross-entropy 坚实的概率论基础,而 MSE 用于分类没有类似的概率解释。
总结:
1
2
3
4
5
6
7
8
9
10
11
Classification 问题
↓
输出层:softmax(多分类)/ sigmoid(二分类,即softmax特例)
↓ 为什么等价?
sigmoid(z) = softmax 取 N=2 时,z = y1 - y2
↓
Loss:cross-entropy 而非 MSE
原因1:MSE 在分类的 loss 曲面上有大片梯度=0的平坦区域
原因2:cross-entropy = 最大似然估计,有概率论保证
↓
优化:gradient descent
Batch Normalization
想法:直接“把山铲平”
为什么需要 Normalization?
考虑一个只有两个输入特征的网络:$y = w_1 x_1 + w_2 x_2 + b$。现在假设 $x_1$ 的值域是 $[1, 2]$,而 $x_2$ 的值域是 $[100, 200]$。
追踪一个小的参数扰动 $\Delta w_2$:
\[\Delta y = \Delta w_2 \cdot x_2\]因为 $x_2$ 很大(量级 100),即使 $\Delta w_2$ 很小,$\Delta y$ 也会很大,进而 $\Delta e$ 很大,$\Delta L$ 很大。反过来,同样大小的 $\Delta w_1$ 乘以小的 $x_1$,对 $L$ 几乎没有影响。
结果是什么? Loss 曲面在 $w_1$ 方向非常平坦,在 $w_2$ 方向非常陡峭——就是之前讲过的那种”狭长椭圆”形状。用同一个 $\eta $ 无法同时适应两个方向,优化非常困难。
解决方案的直觉:如果把所有特征缩放到同一量级,$w_1$ 和 $w_2$ 对 Loss 的影响就会相近,loss 曲面变成接近圆形的等高线,梯度下降可以直接走向最优。
Feature Normalization(第 4 页)
最简单的处理是在输入层做 normalization。对第 $i$ 个特征维度,计算训练集上的均值 $m_i$ 和标准差 $\sigma_i$,然后:
\[\tilde{x}_i^r = \frac{x_i^r - m_i}{\sigma_i}\]处理后每个维度均值为 0、方差为 1,所有特征回到同一量级。
但这只够吗? 对于深层网络,不够。
深层网络的新问题(第 5 页)
做了输入层归一化之后,第一层的 $\tilde{x}$ 是归一化的。但经过第一层变换 $z^1 = W^1 \tilde{x}$,再经过 Sigmoid,得到 $a^1$。这个 $a^1$ 的分布不再受控——它可能在某些维度上范围很大,在另一些维度上范围很小。
把 $a^1$ 当作第二层的输入时,同样的问题又出现了:不同维度的尺度不同,每一层都面临”狭长椭圆”的问题。
这就是为什么需要在每一层之后都做 normalization。
Batch Normalization 的机制(第 6-8 页)
BN 的操作插入在线性变换 $z = Wx$ 之后、激活函数之前。
第一步:在 batch 内计算统计量
对一个 batch 中的 $N$ 个样本,计算这一层每个神经元在 batch 内的均值和标准差:
\[\mu = \frac{1}{N}\sum_{i=1}^{N} z^i, \qquad \sigma = \sqrt{\frac{1}{N}\sum_{i=1}^{N}(z^i - \mu)^2}\]第二步:标准化
\[\tilde{z}^i = \frac{z^i - \mu}{\sigma}\]现在 $\tilde{z}$ 在 batch 内均值为 0、方差为 1。
第三步:可学习的缩放和平移(第 8 页)
直接把所有 $\tilde{z}$ 强制压到均值 0 方差 1 是有问题的——这限制了网络的表达能力,可能破坏前一层学到的有用分布。所以引入两个可学习参数 $\gamma$ 和 $\beta$:
\[\hat{z}^i = \gamma \odot \tilde{z}^i + \beta\]$\gamma$ 和 $\beta$ 也由梯度下降学习,让网络自己决定”归一化到什么程度”。如果网络学到 $\gamma = \sigma_{\text{original}}, \beta = \mu_{\text{original}}$,就相当于撤销了 normalization——网络有这个自由度。这里有一个反直觉但极其重要的细节:$\mu$ 和 $\sigma$ 是从整个 batch 计算出来的,所以 $\tilde{z}^i$ 不只取决于 $z^i$ 自己,还取决于 batch 中其他所有样本的 $z$。这意味着反向传播时,梯度会通过 $\mu$ 和 $\sigma$ 在样本之间流动——batch 内的 $N$ 个样本在计算图上是相互耦合的。这就是 PPT 第 7 页说”This is a large network”的含义。
测试时怎么办?(第 9 页)
训练时有 batch,可以现算 $\mu$ 和 $\sigma$。测试时通常单样本推理,没有 batch。
解决方案:在训练过程中,对每个 batch 的 $\mu^t$ 做指数加权移动平均,积累出一个全局估计 $\bar{\mu}$:
\[\bar{\mu} \leftarrow p\bar{\mu} + (1-p)\mu^t\]$\bar{\sigma}$ 同理。测试时直接用 $\bar{\mu}$ 和 $\bar{\sigma}$ 代替 batch 统计量。
工程细节:PyTorch 里
model.train()使用 batch 统计量,model.eval()自动切换为使用积累的移动平均统计量。忘记调用model.eval()是一个常见 bug。
BN 真正为什么有效?(第 11-12 页)
原始论文提出的解释是Internal Covariate Shift:网络的每一层参数更新后,下一层的输入分布会随之改变,导致每一层都在追踪一个移动的目标,训练不稳定。BN 通过固定每层输入的分布解决了这个问题。
但 2018 年的论文(arxiv 1805.11604)用实验推翻了这个解释——即使强行引入 ICS,BN 仍然有效;并且有 BN 的网络在 ICS 指标上并不比没有 BN 的更低。
实验和理论分析支持的真正原因:BN 改变了 loss 曲面的形状,使其更光滑、更接近各向同性(等高线更圆)。这让梯度下降可以用更大的学习率、更少的步数收敛,也更不容易卡在 sharp minima 里。
这是一个很好的例子:工程上有效的方法,其理论解释可以是错的,就像青霉素在知道真正机制之前就已经在用了。
完整框架连接
1
2
3
4
5
6
7
8
9
10
11
12
Feature Normalization(输入层)
↓ 解决了输入特征尺度不一的问题
↓ 但深层网络每一层都有尺度问题
Batch Normalization(每一层之后)
↓ 步骤:z → normalize with batch mu/sigma → scale/shift with gamma, beta
↓ gamma 和 beta 是可学习参数,保留表达自由度
↓ 训练用 batch 统计量,测试用移动平均
↓ 本质效果:平滑 loss landscape,允许更大学习率
↓ 原始解释(ICS)已被证伪,真正原因是改变曲面形状
其他变体(Layer Norm, Instance Norm, Group Norm…)
↓ 对"在哪些维度上做归一化"的不同选择
↓ Layer Norm 在 NLP/Transformer 中取代 BN
| Batch Norm | Layer Norm | |
|---|---|---|
| 归一化维度 | 跨 batch 内的样本 | 跨单个样本内的特征 |
| 对 batch size 的依赖 | 高(小 batch 统计不稳定) | 无 |
| 适用场景 | CV(CNN) | NLP(RNN, Transformer) |
| 测试时需要特殊处理 | 是(移动平均) | 否 |