中间代码生成
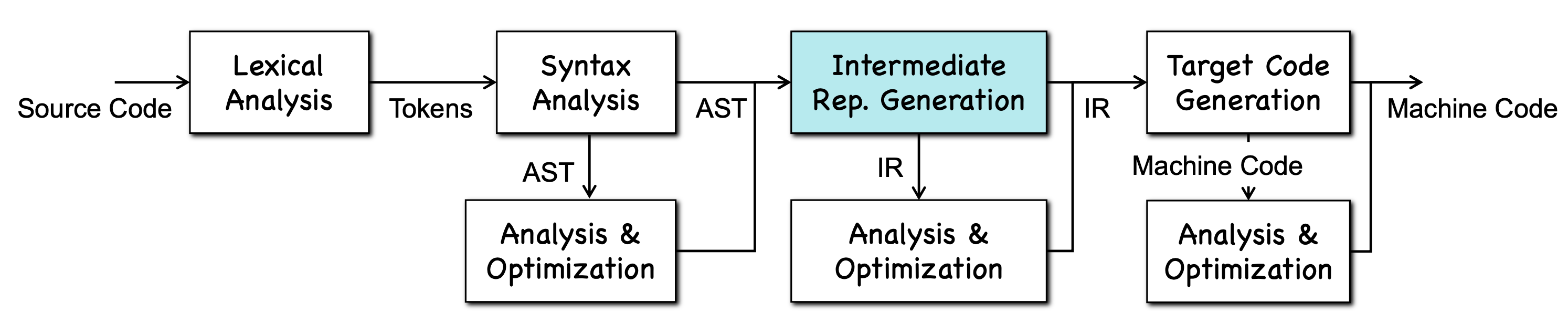
中间代码表示
中间表示(Intermediate Representation, IR):编译器在前端与后端之间使用的、与具体源语言和目标机器都相对独立的程序表示形式,用于承载程序语义、驱动优化,并作为目标代码生成的输入
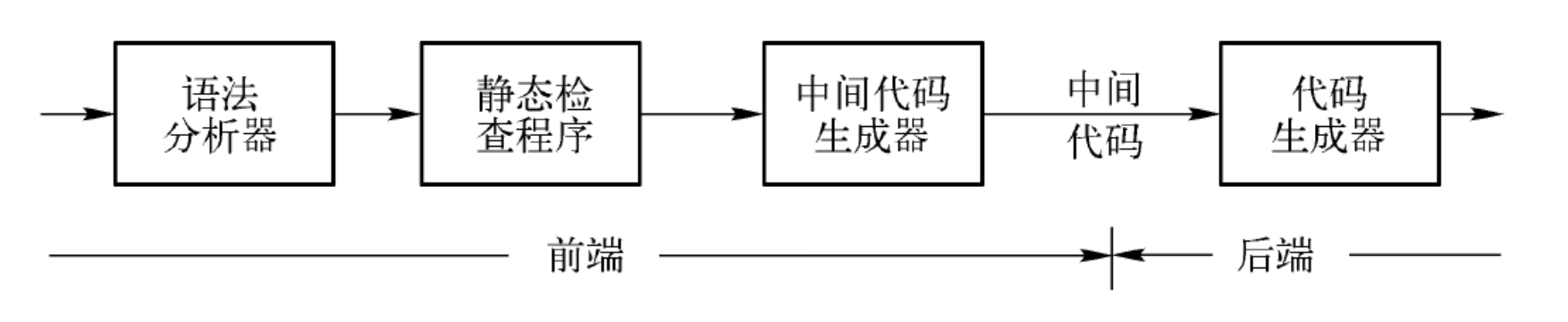
前端对源程序进行分析并产生中间表示,后端在此基础上生成目标代码
为什么需要IR?
- 解耦与可移植性:同一前端可面向多个后端;同一后端可复用多个前端
- 优化平台:大多数中端优化都在IR层进行(如常量传播、死代码删除、循环优化)
- 简化实现:比AST更接近机器,比汇编更抽象,便于规则化生成与分析
- 跨语言统一:多语言编译到统一IR,复用优化与后端(如LLVM IR)
常见IR范式与代表
- 树形IR:抽象语法树(AST)、语法树-语义注释
- 适合“早期”高层变换,不适合低层优化
- 三地址码(TAC):x = y op z;if x goto L;param x;call f, n;return x
- 表示方式:四元式(op, arg1, arg2, result)、三元式(op, arg1, arg2)
- SSA(静态单赋值)形态的IR:在TAC基础上引入Φ函数
- 优化友好:简化数据流问题,如活跃性、可用表达式、冗余消除
- 堆栈式IR:操作数隐含在栈上(如JVM字节码)
- 简单、紧凑,但数据依赖不显式,部分优化不便
- LLVM IR/Sea-of-Nodes 等工业IR
三地址码
三地址码是一种常见的中间表示形式,它将源程序转换为一系列简单的指令,每条指令最多涉及三个“地址”(操作数或结果),典型格式为:
\[result \space=\space arg1\space\space op\space\space arg2\]静态单赋值
静态单赋值形式(Static Single Assignment,SSA)是编译器设计中用于优化的中间表示形式,其核心规则要求每个变量仅被赋值一次,通过添加下标区分变量不同版本
使用SSA可以很容易地发现一些可优化项,如死代码优化、常量传播等
SSA中的所有赋值都是针对不同名的变量,对于同一个变量在不同路径中定值的情况,可以使用φ函数来合并不同的定值,如:
1
2
3
4
5
if (flag)
x = -1;
else
x = 1;
y = x*a
改写为:
1
2
3
4
5
6
if (flag)
x1 = -1;
else
x2 = 1;
x3=φ(x1,x2);
y = x3*a
φ 函数
- 数学意义:一个“多路选择器”(类似 switch)
- 语义:在控制流合流点,根据 控制路径 决定选哪个值
- $x_{n+1} = \phi(x_1, x_2, \dots, x_n)$
- φ 不是 CPU 指令,而是编译器 IR 的“抽象伪指令”。在生成汇编代码时,必须把它消除(φ-elimination)
代码层实现策略
- 插入并行赋值(idealized semantics):在 IR 层面,可以把 φ 看作所有赋值同时发生
- 寄存器重命名 / 移动指令:在真实机器代码生成时,常见做法是在合流点前,插入 move 指令,保证合流点有正确的版本

类型和声明
类型检查
静态:编译期完成(C、Java 强类型系统)
动态:运行期完成(Python、JavaScript)
声明
如何管理局部变量名的存储布局?
变量的类型可以确定变量需要的内存 — 可变大小的数据结构只需要考虑指针
| 变量类型 | 内存大小是否固定 | 存储位置 | 例子 |
|---|---|---|---|
| 基本类型 | 是(编译时已知) | 栈(通常) | int, double, bool |
| 可变大小数据结构 | 否 | 堆上数据 + 栈上指针 | string, slice, array |
函数的局部变量总是分配在连续的区间
因此给每个变量分配一个相对于这个区间开始处的相对地址
变量的类型信息保存在符号表中
如何计算类型和宽度的SDT?
综合属性:type, width
1
2
3
E → E1 + E2
E.type = 类型合并(E1.type, E2.type)
E.width = 根据E.type查表
举个🌰,考虑:
\[\begin{array}{r@{\;}l@{\qquad}l} T & \to B & \{ t = B.\text{type};\ w = B.\text{width}; \} \\ & & \{ T.\text{type} = C.\text{type};\ T.\text{width} = C.\text{width} \} \\[6pt] B & \to \text{int} & \{ B.\text{type} = \text{integer};\ B.\text{width} = 4; \} \\[4pt] B & \to \text{float} & \{ B.\text{type} = \text{float};\ B.\text{width} = 8; \} \\[6pt] C & \to \varepsilon & \{ C.\text{type} = t;\ C.\text{width} = w; \} \\[6pt] C & \to [\ \text{num}\ ]\ C_1 & \{ C.\text{type} = \text{array}(\text{num}.\text{value}, C_1.\text{type}); \\ & & \qquad C.\text{width} = \text{num}.\text{value} \times C_1.\text{width}; \} \end{array}\]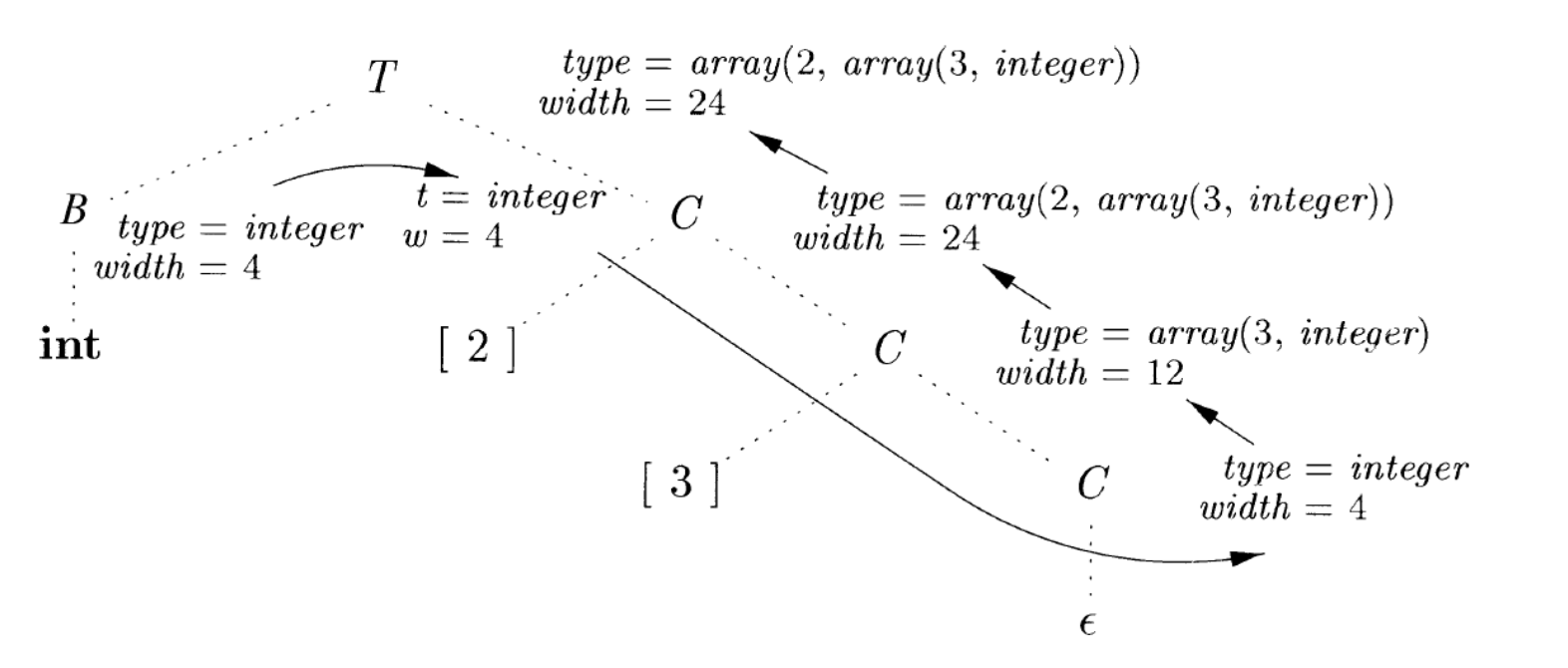
除了确定类型和类型宽度,还有什么语义需要处理?
符号表中的位置!
- 在处理一个过程/函数时,局部变量应该放到单独的符号表中去,这些变量的内存布局独立
- 相对地址从0开始
- 假设变量的放置和声明的顺序相同
- SDT的处理方法:变量offset记录当前可用的相对地址,每“分配”一个变量,offset的值增加相应的值
- top.put(id.lexeme, T.type, offset):在当前符号表(位于栈顶)中创建符号表条目,记录标识符的类型,偏移量
可以把offset看作D的继承属性
- D.offset表示D中第一个变量的相对地址
- P→ {D.offset =0} D
- D → T id; {D1.offset = D.offset + T.width;} D1
如何处理记录字段?
如何处理表达式
将表达式翻译成三地址指令序列
表达式的SDD:
- 属性code表示代码
- addr表示存放表达式结果的地址(临时变量)
- new Temp()可以生成一个临时变量
- gen(…)生成一个指令

必考:翻译if-else和while
fy:期末考试考for
需要将语句的翻译和布尔表达式的翻译结合在一起
布尔表达式是被用作语句中改变控制流的条件表达式,通常用来
- 改变控制流。布尔表达式的值由程序到达的某个位置隐含地指出。
- 计算逻辑值。可以使用带有逻辑运算符的三地址指令进行求值。
布尔表达式的使用意图要根据其语法上下文确定
- 跟在关键字if后面的表达式用来改变控制流
- 一个赋值语句右部的表达式用来计算一个逻辑值
- 可以使用两个不同的非终结符号或其它方法来区分这两种使用
短路求值:
完整笔记
📖 阅读指南
知识依赖链(建议按此顺序阅读):
1
2
3
4
5
6
词法分析 → 语法分析(CFG/SDT/SDD)
└─ 理解属性文法(综合属性 / 继承属性)
└─ 本章:中间代码生成
├─ 4.1 IR 的形式与设计
├─ 4.2 类型系统与声明处理
└─ 4.3 控制流翻译(核心难点)
阅读重点提示:
- 4.1 节建立 IR 全局视野,SSA 的 φ 函数是难点
- 4.2 节聚焦 SDT 实现,关注 offset 计算和数组地址推导
- 4.3 节的回填(Backpatching)是本章最核心技术,务必手推一遍例题
4.1 中间代码表示
4.1.1 IR 的动机与设计权衡
问题动机:为什么不直接从 AST 生成机器码?
假设有 M 种源语言、N 种目标架构。若直接翻译,需要写 M × N 个编译器后端。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
直接翻译(无 IR):
C → x86
C → ARM
C → RISC-V
Java → x86
Java → ARM
... (M × N 个翻译器)
引入 IR 后:
C ─┐
Java ─┼─→ [IR] ─┬─→ x86
Rust ─┘ ├─→ ARM
└─→ RISC-V
(M 个前端 + N 个后端,共 M + N)
关键洞察:IR 是编译器工程中的”分离关注点”思想——前端负责理解语言,后端负责理解机器,中间层承担优化。LLVM 的成功很大程度上源于其设计优良的中层 IR。
IR 的三大作用:
- 解耦与可移植性:同一前端(如 Clang)面向多个后端(x86/ARM/WASM)
- 优化平台:常量传播、死代码删除、循环变换等大量优化在 IR 层实现
- 简化后端实现:IR 比 AST 更接近机器,比汇编更抽象,翻译代价小
IR 的抽象层次
| 层次 | 特点 | 代表形式 |
|---|---|---|
| 高层 IR | 接近源语言,循环/函数/对象等结构显式保留 | AST、注释语义树 |
| 中层 IR | 平衡可分析性与机器距离 | 三地址码(TAC)、SSA |
| 低层 IR | 接近机器,显式寄存器、栈帧、条件跳转 | LLVM IR 最终阶段、RTL(GCC) |
IR 设计的 5 个维度(权衡轴)
| 维度 | 选项 A | 选项 B | 影响 |
|---|---|---|---|
| 控制流 | 结构化(for/while 保留) | 显式标签 + 跳转(基本块图) | 优化分析难度 |
| 数据表示 | 三地址临时变量 | 栈操作数(JVM 风格) | 数据流是否显式 |
| 内存访问 | 显式 load/store | 隐式求值 | 别名分析能力 |
| 类型信息 | 强类型 IR(LLVM IR) | 弱类型/无类型 | 跨语言统一度 |
| 可分析性 | 易于构建 CFG/DFG | 紧凑但难分析 | 优化深度 |
常见 IR 范式对比
| IR 类型 | 核心思想 | 优点 | 缺点 | 代表 |
|---|---|---|---|---|
| 树形 IR(AST) | 保留源语言结构 | 高层变换方便 | 难做低层优化 | GCC GENERIC |
| 三地址码(TAC) | 线性指令序列,≤3个操作数 | 主流、易生成机器码 | 不显式标记 def-use | 龙书主线 |
| SSA | TAC + 每变量只写一次 | 优化极友好 | 构建代价、φ消除 | LLVM IR、GCC GIMPLE |
| 堆栈式 IR | 操作数隐式在栈中 | 紧凑(字节码小) | def-use 不显式 | JVM 字节码 |
| Sea-of-Nodes | 控制流/数据流统一图 | 极强的优化能力 | 实现极复杂 | V8 Turbofan、Java HotSpot C2 |
4.1.2 抽象语法树(AST)
核心思想
AST 是源代码的结构化抽象,保留语义上的必要结构,删除纯粹的语法噪声(括号、分号、关键字等符号)。
1
2
3
4
5
6
7
8
9
10
11
12
13
源代码:
for (i = 0; i <= 10; i++) sum = sum + i;
AST(示意):
ForStatement
/ | \
Init Cond Update
i=0 i <= 10 i++
\
Body
sum = sum + i
/ \
sum i
AST 与分析树(Parse Tree)的区别:
- 分析树:忠实反映文法的推导过程,含大量中间节点(如
expr → term → factor) - AST:压缩语义无关中间节点,只保留运算符和操作数
AST 是三地址码生成的直接输入,编译器对 AST 做后序遍历(Post-order traversal)即可生成线性代码。
4.1.3 三地址码与四元式
问题动机
AST 是树状结构,难以直接映射到线性机器指令序列。我们需要一种”线性化”表示:既保留运算的语义结构,又接近汇编的顺序执行模型。
三地址码(Three-Address Code, TAC)
定义:每条指令最多含三个”地址”(两个操作数 + 一个结果):
1
result = arg1 op arg2
“地址”可以是:
- 源程序中声明的变量(
a,b,sum) - 编译器生成的临时变量(
t1,t2, …) - 常量(
42,3.14) - 标签/标号(
L1,L2)
为什么叫”三地址”:模拟三操作数 RISC 指令(
ADD R1, R2, R3),比树形 IR 更线性,但比汇编保留更多语义信息。
TAC 指令类型全览
| 类型 | 格式 | 具体示例 |
|---|---|---|
| 算术/逻辑运算 | x = y op z | t1 = a + b |
| 一元运算 | x = op y | x = -y, x = !flag |
| 赋值/拷贝 | x = y | sum = 0 |
| 无条件跳转 | goto L | goto L1 |
| 条件跳转 | if x relop y goto L | if t1 <= 10 goto L1 |
| 函数参数 | param x | param sum |
| 函数调用 | call f, n / y = call f, n | call printf, 1 |
| 返回 | return y | return t3 |
| 数组读取 | x = y[i] | t2 = a[t1] |
| 数组写入 | x[i] = y | a[t1] = t2 |
| 指针读取 | x = *p | t3 = *ptr |
| 指针写入 | *p = x | *ptr = val |
| 取地址 | x = &y | p = &a |
具体示例:x = (a+b) * (c-d) + e
TAC 序列(用临时变量记录中间结果):
1
2
3
4
5
t1 = a + b
t2 = c - d
t3 = t1 * t2
t4 = t3 + e
x = t4
三种表示方式的工程对比
TAC 是一个抽象概念,实际编译器有三种常见的数据结构实现:
① 四元式(Quadruple)
1
2
3
4
5
6
(op, arg1, arg2, result)
(+, a, b, t1 )
(-, c, d, t2 )
(*, t1, t2, t3 )
(+, t3, e, t4 )
(=, t4, _, x )
- 引用方式:按名字引用(result 字段存变量名)
- 优化移动代价:低(移动一条指令不影响其他指令的引用)
- 特殊字段处理:
param不使用 arg2 和 result;条件跳转目标放 result 字段
② 三元式(Triple)
1
2
3
4
5
6
位置 (op, arg1, arg2)
(0) (+, a, b )
(1) (-, c, d )
(2) (*, (0), (1) ) ← 引用前面三元式的"位置"
(3) (+, (2), e )
(4) (=, x, (3) )
- 引用方式:按位置编号引用(没有 result 字段,结果隐含在位置中)
- 优化移动代价:高(删除/移动任一三元式,所有引用它的编号全部失效)
- 工程问题:不适合做代码移动(code motion)优化
③ 间接三元式(Indirect Triple)
1
2
3
4
5
6
三元式表(固定): 执行顺序列表(可操作):
(0) (+, a, b) [指向(0)]
(1) (-, c, d) [指向(1)]
(2) (*, (0), (1)) [指向(2)]
(3) (+, (2), e) [指向(3)]
(4) (=, x, (3)) [指向(4)]
- 引用方式:通过指针列表间接引用
- 优化移动代价:低(优化时只修改列表中的指针顺序,三元式本身不变)
- 工程折中:用额外的列表开销换取优化灵活性
工程现实:现代编译器(GCC、LLVM)几乎全部使用四元式或其变体(加上 SSA)。三元式因为优化代价高已基本被淘汰。
| 方案 | 引用方式 | 优化代价 | 实用性 |
|---|---|---|---|
| 四元式 | 按名字 | 低 | ✅ 最常用 |
| 三元式 | 按位置 | 高 | ❌ 优化困难 |
| 间接三元式 | 按指针 | 低 | ⚠️ 实现复杂 |
4.1.4 静态单赋值(SSA)
问题动机:普通 TAC 的分析难题
考虑以下代码片段:
1
2
3
x = 1;
x = 2;
y = x + 1; // 此处 x 的值是什么?
在普通 TAC 中,x 被赋值了两次。要知道 y = x + 1 中 x 的值,需要做数据流分析(Reaching Definitions Analysis),代价较高。
如果代码经过分支合流,情况更复杂:
1
2
3
if (cond) x = 1;
else x = 2;
y = x + 1; // x 来自哪个赋值?
核心思想
SSA(Static Single Assignment)规则:每个变量在整个程序中只被赋值一次,用下标区分同一变量的不同版本。
1
2
3
4
普通 TAC: SSA 版本:
x = 1 x_1 = 1
x = 2 x_2 = 2
y = x + 1 y_1 = x_2 + 1
关键洞察:SSA 中,每个”使用”对应唯一的”定义”,数据流信息被直接编码进变量名,无需单独做数据流分析。
φ 函数(Phi Function)——合流点的多路选择器
问题:带分支时,合流点处的变量版本不唯一,如何在 SSA 中表示?
1
2
3
4
if (cond) x = 1; if (cond) x_1 = 1;
else x = 2; → else x_2 = 2;
y = x + 1; x_3 = φ(x_1, x_2); // 引入 φ 函数!
y_1 = x_3 + 1;
φ 函数的本质:在控制流合流点处,根据实际执行路径(来自哪个前驱基本块)选择正确的变量版本。
1
2
形式: x_n = φ(x_1, x_2, ..., x_k)
含义: 如果控制流从前驱块 i 到达此处,则选 x_i
⚠️ 常见误区:φ 函数不是真实的 CPU 指令,是 IR 层的”抽象伪指令”。生成汇编时必须消除(φ-elimination)。
φ 函数在循环中的作用(以 factorial 为例)
1
2
3
4
5
6
int result = 1;
int n = input;
while (n > 0) {
result = result * n;
n = n - 1;
}
SSA 转换(含基本块结构):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Entry Block:
result_0 = 1
n_0 = input
Header Block (循环头):
result_1 = φ(result_0, result_2) ← 合并 Entry 和 Body 的来源
n_1 = φ(n_0, n_2)
if n_1 > 0 goto Body else goto Exit
Body Block:
result_2 = result_1 * n_1
n_2 = n_1 - 1
goto Header
Exit Block:
return result_1
φ 函数捕获的信息:
result_1 = φ(result_0, result_2):第一次进入循环用初始值result_0,后续迭代用上一轮更新的result_2- 这正是迭代变量的语义——无需额外数据流分析,φ 函数已显式表达
φ 函数的实现:如何消除?
目标:将 φ 函数翻译为真实机器指令。
策略:并行赋值 → 串行 move 指令
1
2
3
4
x_3 = φ(x_1, x_2)
↓
在从 Block_A 跳向合流点的边末尾插入: move x_3, x_1
在从 Block_B 跳向合流点的边末尾插入: move x_3, x_2
工程实现(LLVM):
- 阶段
InsertCopiesForPHIs:为每个 φ 在其前驱基本块末尾生成 move 指令 - 阶段
Register Allocation + Coalescing:通过寄存器合并(coalescing)消除冗余 move - 理论理想:所有 φ 用 move 消除;工程妥协:寄存器压力大时部分 move 保留
GCC 中的 SSA:使用 GIMPLE 形式的 SSA,最终在 RTL(Register Transfer Language)阶段做 φ 展开。
为什么工业编译器都使用 SSA?
| 优化 | 无 SSA(普通 TAC) | 有 SSA |
|---|---|---|
| 常量传播 | 需 Reaching Definitions | 直接查唯一定义点 |
| 死代码删除 | 需 Live Variable Analysis | 无使用者的定义即为死代码 |
| 寄存器分配 | 需构建干涉图 | SSA 形式的干涉图更稀疏 |
| 全局值编号(GVN) | 复杂 | 直接基于 SSA 名字做哈希 |
历史背景:SSA 形式由 Cytron 等人在 1991 年正式提出并推广。LLVM IR、GCC GIMPLE、Java HotSpot C2、Rustc MIR 均使用 SSA 或其变体。
4.2 类型和声明
4.2.1 类型表达式与类型等价
类型的作用(为什么编译器需要类型信息?)
类型信息贯穿整个中间代码生成过程,用途包括:
- 查错:在编译期发现类型不匹配(
int * string报错) - 确定内存布局:
int占 4 字节,double占 8 字节,struct需要对齐 - 数组地址计算:
a[i]的地址 = base_addr + i × element_size(需要元素类型的宽度) - 选择正确指令:整数加法 vs 浮点加法是不同机器指令
- 类型转换:
int + float需要先将 int 拓宽为 float
类型表达式(构造方式)
类型可以用类型表达式递归构造:
| 构造器 | 语法 | 示例 |
|---|---|---|
| 基本类型 | int, float, char, bool | int |
| 数组类型 | array(n, T) | array(3, int) 表示 int[3] |
| 函数类型 | T1 → T2 | int → float |
| 指针类型 | pointer(T) | pointer(int) 表示 int* |
| 记录类型 | record{f1:T1, f2:T2, ...} | record{x:int, y:float} |
| 类型别名 | typedef / 类型变量 | typedef int myint |
嵌套示例:int a[2][3] 的类型表达式:
1
2
array(2, array(3, int))
宽度 = 2 × (3 × 4) = 24 字节
类型等价:结构等价 vs 命名等价
结构等价(Structural Equivalence):两个类型表达式的树结构相同则等价。
1
2
3
typedef struct { int x; float y; } A;
typedef struct { int x; float y; } B;
// 结构等价:A 和 B 等价(树相同)
命名等价(Name Equivalence):两个类型必须由相同名字/声明引出才等价。
1
// 命名等价:A 和 B 不等价(不同声明)
工程现实:
- C 语言用结构等价(结构体逐字段比较)
- Pascal/Ada 倾向命名等价
- Java 对于对象类型用引用等价(类名相同才等价)
类型兼容与隐式转换(Coercion)
自动类型拓宽(widening coercion):
1
2
int i = 3;
float f = i + 1.5; // i 自动转换为 float
编译器在遇到 int op float 时,生成类型转换代码,再使用浮点指令。
4.2.2 声明的 SDT 实现
核心问题:如何在编译期间处理声明?
变量声明需要解决三个子问题:
- 确定类型:类型表达式是什么?宽度是多少?
- 分配内存:在局部帧中的相对偏移地址(offset)是多少?
- 登记符号表:让后续表达式能查到变量信息
① 局部变量的存储布局
1
2
3
4
5
6
7
8
9
10
11
12
13
函数帧内存布局(抽象模型):
高地址
┌──────────────┐
│ 变量 d (8B) │ offset = 12
├──────────────┤
│ 变量 c (4B) │ offset = 8
├──────────────┤
│ 变量 b (4B) │ offset = 4
├──────────────┤
│ 变量 a (4B) │ offset = 0 ← 帧基址
└──────────────┘
低地址
- 每声明一个变量:
offset += width(T) - 变量的绝对地址 = 帧基址(运行时确定)+ offset(编译期确定)
② 计算类型和宽度的 SDT
以 int[2][3] 的类型推导为例:
文法:
1
2
3
4
D → T id ; D | ε
T → B C | record '{' D '}'
B → int | float
C → '[' num ']' C | ε
属性:
T.type(综合):类型表达式T.width(综合):字节宽度- 全局变量
t、w传递 B 的类型和宽度给 C 的产生式
推导过程(int[2][3]):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
步骤 1:B → int
t = int, w = 4
步骤 2:C → '[' 3 ']' C₁
C₁ = ε → type = t = int, width = w = 4
C.type = array(3, int)
C.width = 3 × 4 = 12
步骤 3:C → '[' 2 ']' C₀ (外层 C)
C.type = array(2, array(3, int))
C.width = 2 × 12 = 24
步骤 4:T.type = array(2, array(3, int))
T.width = 24
③ 符号表位置管理
处理函数/过程声明时:
创建新的局部符号表,
offset从 0 开始每声明一个变量 id : T:
1
top.put(id.lexeme, T.type, offset)offset = offset + T.width
函数结束时弹出局部符号表,恢复外层
offset
⚠️ 反直觉点:
offset是编译期计算的相对偏移,不是运行时的绝对地址。运行时通过帧指针(frame pointer)加偏移访问变量。
④ 记录(struct)字段的处理
1
T → record '{' D '}'
处理流程:
1
2
3
4
5
遇到 record → 压栈(保存当前符号表和 offset)
处理字段声明 D → 每个字段放入新的局部符号表
遇到 '}' → 弹栈,构造 record 类型表达式:
T.type = record(top) // top 是刚才构建的字段符号表
T.width = offset // 结构体总大小
⑤ 表达式的 SDD 翻译
属性定义:
E.addr:存放表达式结果的临时变量(或变量名)E.code:计算表达式所需的三地址指令序列
关键辅助操作:
new Temp():生成新的临时变量(t1,t2, …)gen(instr):生成一条三地址指令,追加到当前代码序列top.get(id.lexeme):从符号表栈中查找变量信息(从栈顶向下)
示例:a + b * c 的翻译
| 产生式 | 动作 |
|---|---|
E → id | E.addr = top.get(id.lexeme); E.code = "" |
E → E₁ * E₂ | E.addr = new Temp(); gen(E.addr "=" E₁.addr "*" E₂.addr) |
E → E₁ + E₂ | E.addr = new Temp(); gen(E.addr "=" E₁.addr "+" E₂.addr) |
生成结果:
1
2
t1 = b * c
t2 = a + t1
⑥ 数组引用的地址计算
核心问题:多维数组 a[i][j] 的元素地址如何计算?
数学推导(行主序,row-major order):
设 a 是 int[r₁][r₂](r₁行,r₂列,元素宽度 w):
1
a[i][j] 的地址 = base(a) + (i × r₂ + j) × w
编译期分离:
- 编译期已知:r₂(列数)、w(元素宽度)
- 运行期才知:i、j 的具体值
生成的三地址码(c + a[i][j],a 为 2×3 int 数组,w=4):
1
2
3
4
5
t1 = i * 3 // 行偏移(r₂ = 3)
t2 = t1 + j // 线性下标
t3 = t2 * 4 // 字节偏移(w = 4)
t4 = a[t3] // 访问元素(a 为基址)
t5 = c + t4
l-value vs r-value:
a[i][j]在赋值左端是 l-value(表示地址),在右端是 r-value(表示值)。编译器需要根据上下文选择生成a[t3](r-value)还是存入a[t3] = ...(l-value)。
4.2.3 类型检查与类型转换
类型系统(Type System)
类型系统 = 给程序各成分赋予类型 + 用规则约束合法性的逻辑体系。
两种类型推断模式:
| 模式 | 方向 | 说明 | 代表语言 |
|---|---|---|---|
| 类型综合(Type Synthesis) | 由子式 → 整体 | f: s→t 且 x: s → f(x): t | C, Java |
| 类型推导(Type Inference) | 由用途 → 类型 | 看使用方式推出变量类型 | ML, Haskell, Rust |
类型转换的三地址码生成
场景:x * i,其中 x: float,i: int
问题:float 和 int 使用不同二进制表示,乘法也是不同指令(fmul vs imul)。
处理步骤:
- 检测到类型不匹配:
float * int - 调用
Widen(i, int, float)生成转换指令 - 生成浮点乘法
生成的三地址码:
1
2
t1 = (float) i // widening:int → float
t2 = x fmul t1 // 浮点乘法
widening vs narrowing
1
2
3
4
5
类型拓宽层次(C 语言算术转换规则,越往右范围越大):
byte → short → int → long → float → double
widening(拓宽,隐式):int → float // 编译器自动插入
narrowing(窄化,显式):double → int // 需要程序员写 (int)
Max(t1, t2) 函数:求两类型在拓宽层次中的最小公共祖先(即”统一类型”):
1
2
Max(int, float) = float
Max(int, int) = int
Widen(a, from, to) 函数:生成将变量 a 从 from 类型转换到 to 类型的代码:
1
2
3
4
5
if from == to: return a (无需转换)
elif from == int and to == float:
t = new Temp()
gen(t "= (float)" a)
return t
4.3 控制流语句翻译
4.3.1 布尔表达式的翻译
布尔表达式的两种使用场景
布尔表达式在程序中有两种截然不同的使用意图,翻译方式完全不同:
| 场景 | 典型代码 | 翻译目标 |
|---|---|---|
| 改变控制流 | if (a < b) ... | 跳转到不同代码位置 |
| 计算逻辑值 | `x = (a < b) |
核心洞察:用于控制流时,布尔值是隐含在跳转方向中的,不需要显式存储 0 或 1。这是”跳转代码”翻译法的基本思想。
短路求值(Short-Circuit Evaluation)
定义:在确定表达式结果后,不再计算剩余子表达式:
B1 || B2:B1 为真 → 整体为真,不求 B2B1 && B2:B1 为假 → 整体为假,不求 B2
生成的跳转代码结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
B1 || B2:
[B1 的代码]
if B1 is true → goto B.true
[B2 的代码]
if B2 is true → goto B.true
goto B.false
B1 && B2:
[B1 的代码]
if B1 is false → goto B.false
[B2 的代码]
if B2 is true → goto B.true
goto B.false
SDT 属性设计
继承属性(从外部传入,告知跳转目标):
B.true:布尔表达式为真时应跳往的标号B.false:布尔表达式为假时应跳往的标号S.next:语句 S 执行结束后的下一条指令标号
综合属性:
B.code、S.code:翻译生成的三地址码序列
控制流语句的翻译规则
if-else 的翻译:
1
2
3
4
5
6
7
8
9
10
S → if (B) S1 else S2
B.true = newlabel() // 创建 S1 入口标号
B.false = newlabel() // 创建 S2 入口标号
S1.next = S.next
S2.next = S.next
S.code = B.code
+ label(B.true) + S1.code + gen(goto S.next)
+ label(B.false) + S2.code
ASCII 流程图:
1
2
3
4
5
6
7
[B 的代码]
/ \
true false
↓ ↓
[S1 的代码] [S2 的代码]
\ /
→ S.next
while 的翻译:
1
2
3
4
5
6
7
8
S → while (B) S1
begin = newlabel() // 循环头标号
B.true = newlabel() // 循环体入口
B.false = S.next // 循环出口
S.code = label(begin) + B.code
+ label(B.true) + S1.code + gen(goto begin)
ASCII 流程图:
1
2
3
4
5
6
7
begin:
[B 的代码]
/ \
true false
↓ ↓
[S1 的代码] S.next
└──────→ begin(goto)
避免冗余 goto:fall 标号
问题:某些情况下 B 为真时下一条就是目标指令,不需要生成 goto。
解决方案:引入特殊标号 fall,表示”穿越”(fall-through),即顺序执行不跳转:
1
if B.true == fall: 不生成跳转,直接顺序执行
4.3.2 回填(Backpatching)技术
核心问题:前向引用(Forward Reference)
在单遍(one-pass)翻译中,生成跳转指令时,跳转目标地址尚未知道:
1
2
3
4
5
6
7
8
9
10
翻译 if ((x<y) && (y<z)) S 时:
Step 1:生成 x<y 的比较跳转
"if x >= y goto ???" ← 目标在哪?S 还没翻译!
Step 2:生成 y<z 的比较跳转
"if y >= z goto ???" ← 目标同上
Step 3:翻译 S,这时才知道 S 的入口地址
Step 4:回头填充 Step 1、2 中的 "???"
为什么不两遍扫描?两遍翻译可以解决前向引用,但 one-pass 翻译效率更高,更适合流式编译。回填是 one-pass 翻译的工程妥协。
回填的基本思路
- 生成带占位符
_的不完整跳转指令:goto _ - 用列表记录所有”等待填充”的指令位置
- 当目标地址确定时,回溯并填充所有占位符
三个辅助函数
| 函数 | 作用 | 说明 |
|---|---|---|
makelist(i) | 创建只含位置 i 的列表 | 通常在生成一条待填跳转指令后调用 |
merge(p1, p2) | 合并两个待回填列表 | 两组指令都跳向同一目标时使用 |
backpatch(p, i) | 将标号 i 填入列表 p 中所有指令的目标字段 | 目标地址确定时调用 |
布尔表达式的回填属性
| 属性 | 含义 |
|---|---|
B.truelist | 所有”B 为真时需要跳转”的指令位置列表 |
B.falselist | 所有”B 为假时需要跳转”的指令位置列表 |
注意:不再是”标号的字符串”,而是”指令的编号(位置)”。
布尔运算的回填翻译规则
① 关系表达式 B → E1 rel E2
1
2
3
4
5
6
动作:
生成指令 nextquad: "if E1 rel E2 goto _" (truelist 候选)
生成指令 nextquad+1: "goto _" (falselist 候选)
B.truelist = makelist(nextquad)
B.falselist = makelist(nextquad + 1)
nextquad += 2
② 逻辑与 B → B1 && M B2
(M 是辅助非终结符,记录 B2 代码的开始位置)
1
2
3
4
5
6
M.instr = nextquad // 记录 B2 代码的第一条指令位置
动作(规约时):
backpatch(B1.truelist, M.instr) // B1 为真 → 跳入 B2
B.truelist = B2.truelist
B.falselist = merge(B1.falselist, B2.falselist)
③ 逻辑或 B → B1 || M B2
1
2
3
4
动作(规约时):
backpatch(B1.falselist, M.instr) // B1 为假 → 跳入 B2
B.falselist = B2.falselist
B.truelist = merge(B1.truelist, B2.truelist)
控制转移语句的回填
语句的新属性:
| 属性 | 含义 |
|---|---|
S.nextlist | 所有”S 执行完需要跳出”的指令位置列表 |
辅助非终结符 M(记位置,替代显式 label):
1
2
M → ε
动作:M.instr = nextquad // 记录下一条要生成指令的位置
辅助非终结符 N(生成 goto 坯):
1
2
3
4
5
N → ε
动作:
生成指令 nextquad: "goto _"
N.nextlist = makelist(nextquad)
nextquad += 1
if-else 的回填规则:
1
2
3
4
5
6
7
S → if ( B ) M₁ S₁ N else M₂ S₂
动作:
backpatch(B.truelist, M₁.instr) // B 真 → S₁ 入口
backpatch(B.falselist, M₂.instr) // B 假 → S₂ 入口
S.nextlist = merge(S₁.nextlist, N.nextlist, S₂.nextlist)
// N.nextlist 是 S₁ 结束后跳过 S₂ 的 goto _
while 的回填规则:
1
2
3
4
5
6
7
S → while ( M₁ B ) M₂ S₁
动作:
backpatch(S₁.nextlist, M₁.instr) // 循环体结束 → 跳回循环头
backpatch(B.truelist, M₂.instr) // B 真 → 进入循环体
S.nextlist = B.falselist // B 假 → 循环出口(待上层回填)
生成 "goto M₁.instr" // 循环体末尾的回跳
完整示例:if ((x<y) && (y<z) || (x==z)) a=1; else a=2;
初始状态:nextquad = 1
| 步骤 | quad | 指令 | 说明 |
|---|---|---|---|
| 翻译 x<y | 1 | if x < y goto _ | B₁.truelist = {1} |
| 2 | goto _ | B₁.falselist = {2} | |
| 翻译 y<z(M₁.instr=3) | 3 | if y < z goto _ | B₂.truelist = {3} |
| 4 | goto _ | B₂.falselist = {4} | |
| 规约 B₁&&B₂ | backpatch({1}, 3) → quad1: if x<y goto 3 | B.false = {2,4} | |
| B.truelist = {3} | |||
| 翻译 x==z(M₂.instr=5) | 5 | if x == z goto _ | B₃.truelist = {5} |
| 6 | goto _ | B₃.falselist = {6} | |
| 规约 (B₁&&B₂)||B₃ | backpatch({2,4}, 5) | B.false = {6} | |
| B.truelist = merge({3},{5}) = {3,5} | |||
| N.nextlist(S₁跳出口) | 7 | goto _ | N.nextlist = {7} |
| M₁.instr = 8,翻译 a=1 | 8 | a = 1 | S₁.nextlist = {} |
| backpatch(B.truelist, 8) | quad3: if y<z goto 8;quad5: if x==z goto 8 | ||
| M₂.instr = 9,翻译 a=2 | 9 | a = 2 | S₂.nextlist = {} |
| backpatch(B.falselist, 9) | quad6: goto 9 | ||
| S.nextlist = merge({7},{}) = {7} | quad7 待上层回填(跳到 if 之后的代码) |
最终三地址码(10 条):
1
2
3
4
5
6
7
8
9
1: if x < y goto 3
2: goto 5
3: if y < z goto 8
4: goto 5
5: if x == z goto 8
6: goto 9
7: goto _ ← 待上层 backpatch(S.next)
8: a = 1
9: a = 2
关键观察:
||的 false 目标(quad2)→ 被 backpatch 到 5(第二个操作数开头)&&的 true 目标(quad1)→ 被 backpatch 到 3(第二个操作数开头)- 最终 true 跳转({3,5})→ 被 backpatch 到 8(then 分支开头)
do-while 示例:do { a=a+1; } while (a<10 && b>0);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
M.instr = 1(循环体起点)
1: t1 = a + 1
2: a = t1
(B1: a<10)
3: if a < 10 goto _ B1.truelist = {3}
4: goto _ B1.falselist = {4}
(M₂.instr = 5)
(B2: b>0)
5: if b > 0 goto _ B2.truelist = {5}
6: goto _ B2.falselist = {6}
规约 B1 && B2:
backpatch({3}, 5) → quad3: if a < 10 goto 5
B.truelist = {5}
B.falselist = {4, 6}
规约 do S while B:
backpatch(B.truelist, M.instr) → quad5: if b > 0 goto 1
S.nextlist = B.falselist = {4, 6}(待上层填为循环出口 7)
最终六条三地址码:
1
2
3
4
5
6
1: t1 = a + 1
2: a = t1
3: if a < 10 goto 5
4: goto 7 ← backpatched(S.next = 7)
5: if b > 0 goto 1
6: goto 7 ← backpatched(S.next = 7)
循环出口为 7。
非回填方案 vs 回填方案对比
| 非回填(继承标号) | 回填(位置列表) |
|---|---|
B.true = newlabel() | B.truelist = makelist(nextquad) |
gen("goto B1.false") | gen("goto _") → 加入 falselist |
label(X) 处生成标号 | M.instr = nextquad 记录位置 |
| 依赖完整符号表 | 只依赖指令编号,更轻量 |
回填的工程价值:不需要提前分配标号字符串,只用整数编号跟踪,在单遍翻译(尤其是流式输出汇编)中更高效。
4.3.3 Break / Continue 的处理
问题:跨层跳转目标在哪里?
break 和 continue 是跨层跳转:
break:跳出最近的外围循环(到循环之后的第一条指令)continue:跳到最近的外围循环的判断条件(循环头)
它们在语法上是独立语句,但跳转目标依赖外围循环——在处理 break 时,外围循环的出口地址尚未确定。
break 的实现
方法:利用已有的回填机制:
1
2
3
遇到 break 语句:
1. 生成指令 nextquad: "goto _"
2. 将该指令位置加入 外围语句 S 的 S.nextlist 中
当外围循环确定出口地址时,backpatch(S.nextlist, exit_addr) 会同时填充 break 产生的 goto _。
跟踪外围循环的方法:
- 符号表标记:在符号表中设置
break条目,指向当前最近的外围循环语句 - 指针传递:直接传递外围语句的
nextlist指针,将break生成的指令直接追加进去
ASCII 示意:
1
2
3
4
5
6
while (cond) {
...
if (x) break; ← 生成 "goto _",位置加入 while 的 nextlist
...
}
← backpatch(while.nextlist, here) 时,break 的跳转也被填充
continue 的实现
与 break 类似,但跳往循环头(条件判断处):
- 生成
goto _ - 将位置加入辅助变量 M 所记录的循环头位置,或直接生成
goto M.instr(若循环头已知)
嵌套循环:
break/continue应跳出/继续最近的外围循环,实现上通过栈来跟踪嵌套层次,栈顶始终是当前最近的循环的 nextlist 和 continue 目标。
附录
常见误区对照表
| 误区 | 正确理解 |
|---|---|
| “IR 就是汇编的简化版” | IR 比汇编更抽象(不涉及具体寄存器/指令集),且可用于多个后端 |
| “三元式不用 result 字段,所以更高效” | 三元式用位置引用,优化代价高,实际上现代编译器不用 |
| “φ 函数是一种条件赋值指令” | φ 不是 CPU 指令,是 IR 的伪指令,必须在生成汇编前消除 |
| “结构等价比命名等价更严格” | 相反:结构等价更宽松(只看形状),命名等价更严格(必须同一声明) |
| “offset 是变量的绝对内存地址” | offset 是相对帧基址的偏移量,绝对地址在运行时由帧指针加偏移得到 |
| “回填是两遍扫描的技术” | 回填正是为了避免两遍扫描——在单遍中处理前向引用 |
| “truelist/falselist 存储的是标号字符串” | 存储的是指令的位置编号(整数),不是字符串标号 |
| “break 生成的 goto 需要特殊处理” | break 生成的 goto _ 直接并入外围循环的 nextlist,与普通回填无异 |
关键概念速查表
| 概念 | 一句话定义 | 所在章节 |
|---|---|---|
| IR | 前端与后端之间与语言/机器都独立的程序表示 | 4.1.1 |
| TAC | 每条指令最多三个地址的线性中间代码 | 4.1.3 |
| 四元式 | TAC 的实现:(op, arg1, arg2, result) | 4.1.3 |
| 三元式 | TAC 的实现:(op, arg1, arg2),按位置引用结果 | 4.1.3 |
| 间接三元式 | 三元式 + 指针列表,优化时只操作列表 | 4.1.3 |
| SSA | 每个变量只赋值一次,用下标区分版本 | 4.1.4 |
| φ 函数 | 合流点处的多路选择器,选择不同前驱带来的变量版本 | 4.1.4 |
| 类型表达式 | 递归构造类型的表达式,如 array(3, int) | 4.2.1 |
| 结构等价 | 两类型的树结构相同则等价 | 4.2.1 |
| 命名等价 | 两类型必须来自相同声明才等价 | 4.2.1 |
| offset | 变量在函数帧中的相对偏移量(编译期确定) | 4.2.2 |
| 类型综合 | 由子表达式类型推出整体类型 | 4.2.3 |
| widening | 编译器自动插入的隐式类型拓宽(如 int→float) | 4.2.3 |
| 短路求值 | `&&/ | |
| B.true / B.false | 布尔表达式为真/假时的跳转目标标号(继承属性) | 4.3.1 |
| fall(穿越) | 特殊标号,表示不生成跳转,直接顺序执行 | 4.3.1 |
| 回填 | 先生成带占位符的跳转,后在目标确定时填充 | 4.3.2 |
| truelist / falselist | 记录布尔表达式中待回填的跳转指令位置列表 | 4.3.2 |
| M(辅助非终结符) | 记录下一条指令位置(M.instr = nextquad) | 4.3.2 |
| N(辅助非终结符) | 生成 goto _ 指令坯,N.nextlist 含此位置 | 4.3.2 |
| nextlist | 语句执行完后所有待跳转指令的位置列表 | 4.3.2 |
本章知识依赖图(ASCII 树)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
前置知识
├── 词法分析(token 流)
├── 语法分析(CFG、推导)
└── 属性文法(SDT / SDD)
├── 综合属性(自底向上传递)
└── 继承属性(自顶向下传递)
本章内容
├── 4.1 IR 表示
│ ├── AST(源语言结构保留)
│ ├── TAC(线性化,三地址)
│ │ ├── 四元式(最常用)
│ │ ├── 三元式(按位置,优化代价高)
│ │ └── 间接三元式(指针列表,优化友好)
│ └── SSA(TAC + φ函数)
│ ├── 每变量唯一定义
│ └── φ函数(合流点多路选择)
│
├── 4.2 类型与声明
│ ├── 类型表达式(递归构造)
│ ├── 类型等价(结构 vs 命名)
│ ├── 声明 SDT(offset 管理,符号表压栈)
│ ├── 数组地址计算(行主序公式)
│ └── 类型转换(widening / narrowing)
│
└── 4.3 控制流翻译
├── 布尔表达式(双重角色)
├── 短路求值 → 跳转代码
├── true/false 标号(继承属性)
├── 前向引用问题
└── 回填(Backpatching)
├── makelist / merge / backpatch
├── truelist / falselist
├── M(记位置)/ N(生成 goto 坯)
├── nextlist(语句跳出列表)
└── break/continue → 并入外围 nextlist