多处理器编程
REVIEW
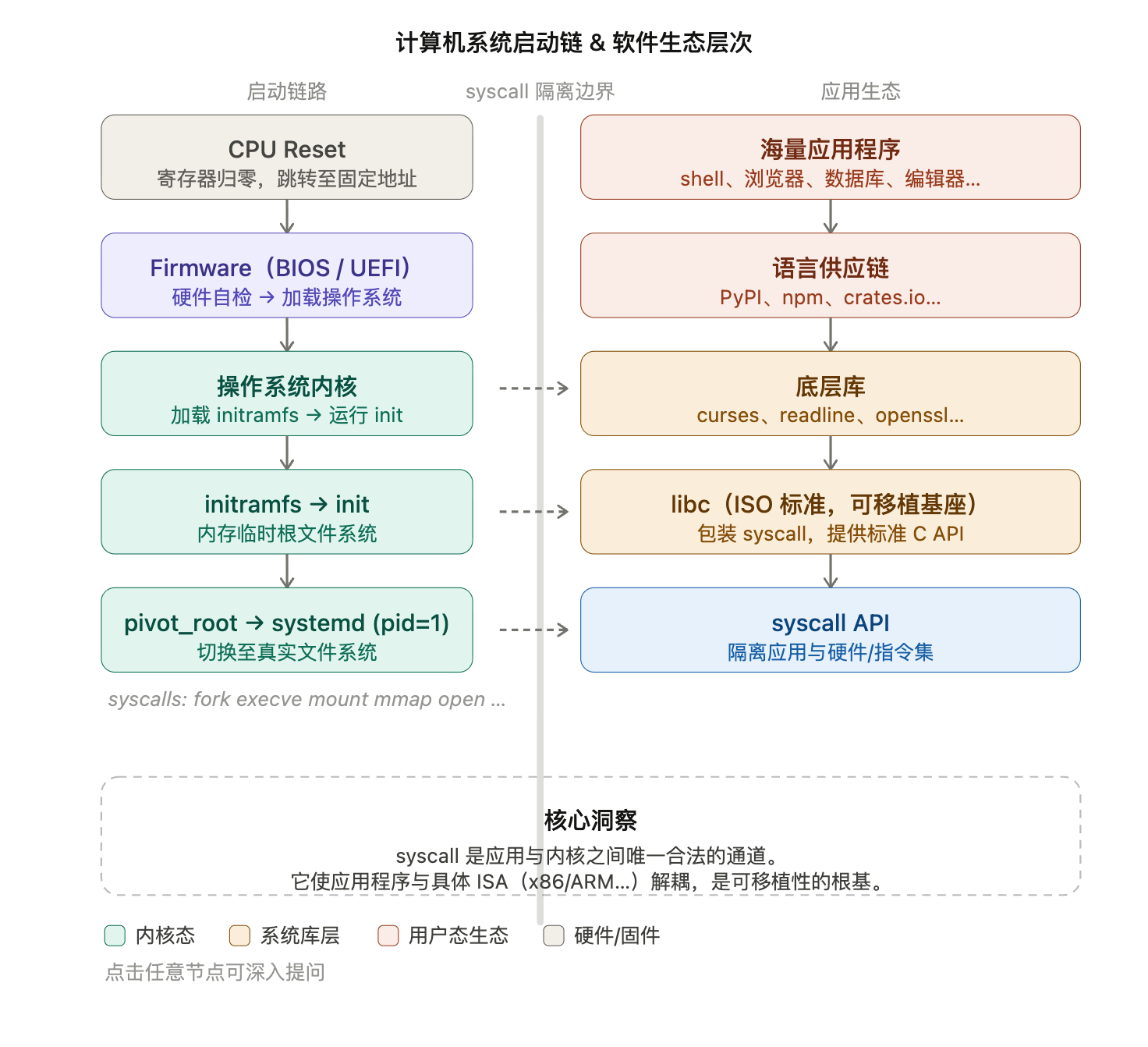
问题动机:从零开始的系统
一台刚上电的计算机,什么软件都没运行。谁来决定第一条指令是什么?谁来把操作系统加载进内存? 这就是启动链(boot chain)要解决的问题。
关键约束:CPU 上电后不知道”系统在哪”,只知道跳转到一个固定的物理地址,剩下的事交给那里的代码。
启动链(Boot Chain)
整个过程是一条接力棒,每一级负责把下一级加载进来并移交控制权。
1. CPU Reset — 硬件初始状态
- 所有寄存器归零(或置为规定初值),PC 指向固定的物理地址(如 x86 上的
0xFFFFFFF0)。 - 此时内存里只有固件(Firmware),没有任何 OS。
2. Firmware(BIOS / UEFI)— 硬件的“管家”
- 做上电自检(POST):检测 CPU、内存、外设是否正常。
- 确定启动设备(磁盘、USB、网络…),从中读取操作系统引导程序。
- 把控制权移交给 OS bootloader(如 GRUB)。
工程备注:UEFI 相比 BIOS 更现代,支持 GPT 分区、安全启动(Secure Boot)等,本质仍是完成同一件事。
3. OS 内核加载 — initramfs → init
- OS 内核被加载进内存后,需要挂载根文件系统才能继续运行。
- 问题:驱动程序(如磁盘驱动)存在文件系统里,但读文件系统又需要驱动 —— 鸡蛋问题。
- 解法:内核解压一个内存中的临时文件系统
initramfs(Initial RAM Filesystem),里面包含最小化的驱动和init程序,用来完成早期初始化。
4. pivot_root → systemd(pid=1)— 接管用户空间
init程序加载真正的磁盘驱动,挂载真实根文件系统。- 调用
pivot_root切换根目录,抛弃 initramfs,把根指向真实文件系统。 - 然后执行真正的
init,现代 Linux 上通常是 systemd(pid=1)。 - 从此,所有进程都是 systemd 的后代,OS 持续提供 syscall:
fork、execve、mount、mmap、open……
syscall:应用与硬件之间的唯一接口
核心洞察:应用程序永远不能直接操作硬件,它只能通过 syscall 向内核“请求服务”。
| 如果没有 syscall 隔离 | 有了 syscall 隔离 |
|---|---|
| 应用程序直接写硬件寄存器 | 应用程序调用 write(fd, buf, n) |
| 换一块网卡/磁盘就要重写应用 | 驱动细节完全封装在内核里 |
| 任何 bug 都能破坏整个系统 | 用户态崩溃不影响内核 |
| 无法移植到不同 CPU 架构 | x86/ARM 上同一份代码可运行 |
这就是为什么 syscall API 被称为“指令集无关”的:同一个 C 程序在 x86 和 ARM 上的二进制不同,但源码行为相同。
基于 OS API 的软件生态(分层结构)
从 syscall 往上,是一个层层叠加的生态:
1
2
3
4
5
6
7
8
9
10
11
海量应用程序(shell、浏览器、数据库…)
↑
语言供应链(PyPI / npm / crates.io…)
↑
底层库(curses / readline / openssl…)
↑
libc — 可移植的标准 C 基座(ISO 标准)
↑
syscall API ← 隔离边界
↑
OS 内核
- libc 是关键的”翻译层”:把平台无关的
printf、malloc等标准函数,翻译成具体的 syscall。它是 POSIX/ISO 标准,让同一份源码跨平台编译。 - 底层库(如
readline)在 libc 之上封装更高级的功能(行编辑、历史记录),供语言运行时或应用直接使用。 - 语言供应链(npm、PyPI)则是更高层的模块化复用机制,与具体 OS 几乎无关,只依赖语言运行时的抽象。
###
| 概念 | 本节关联 |
|---|---|
| 链接与加载 | OS 用 execve 触发加载器,把 ELF 文件映射进地址空间 |
| 进程模型 | fork 是 systemd 繁殖进程树的基础 syscall |
| 虚拟内存 | mmap 是 OS 为进程提供虚拟地址空间的手段 |
| 文件系统 | mount 允许把任意文件系统挂载到目录树上 |
| 可移植性 | libc + syscall 共同构成跨架构可移植的基础 |
共享内存的并发编程:动机
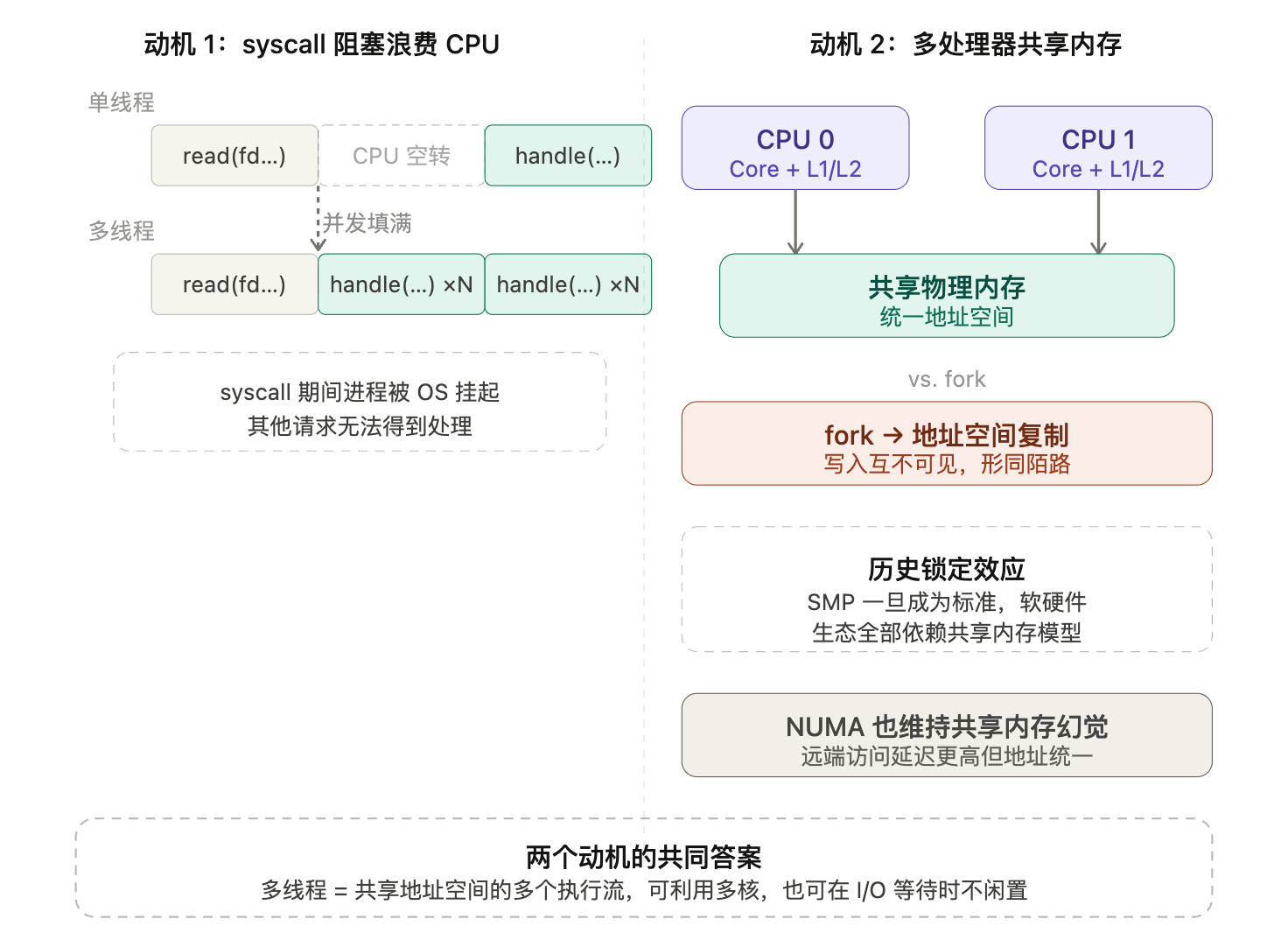
核心问题
为什么要引入“多个执行流共享内存”这种复杂的编程模型?
两个独立但相互呼应的动机共同驱动了这一需求。
动机 1:syscall 可能执行很长时间
问题所在
1
2
3
4
5
6
7
void http_server(int fd) {
while (1) {
buf = alloc_buf();
nread = read(fd, buf, 1024); // ← 这里可能阻塞几毫秒到几秒
handle_request(buf, nread); // ← 在此之前什么都做不了
}
}
read(fd, ...) 是一个 syscall。当数据尚未到达时,OS 会把这个进程挂起(放入等待队列),CPU 去执行别的进程。等数据来了再唤醒它。
结果:整个 http_server 在等待期间完全停摆,无法并发处理其他请求。
朴素解法为何不够
- 多进程(
fork):可以解决并发,但进程间内存隔离,通信成本高。 - 单进程事件循环(
select/epoll):可以避免阻塞,但编程模型复杂,且无法利用多核。
关键思路
如果能有“多个执行流共享同一地址空间”,则:在一个执行流等待 read 时,另一个执行流可以继续执行 handle_request,CPU 不闲置。
这是并发的 I/O 利用率动机:不让 CPU 在 syscall 等待期间空转。
动机 2:多处理器系统天然是共享内存的
硬件现实
现代服务器通常有多颗 CPU(每颗多个 core),它们通过总线/互联网络访问同一块物理内存。这是 SMP(Symmetric Multiprocessing)的基本设计。
- 这意味着:如果两个线程运行在不同 core 上,它们可以直接读写同一个变量,通信代价极低(相比进程间通信)。
fork 的局限
fork 之后,子进程得到的是父进程地址空间的完整副本(Copy-on-Write)。之后两个进程的内存写操作互相不可见——“形同陌路”。
要让两个 fork 出来的进程通信,必须借助 pipe、socket、共享内存段等 IPC 机制,绕了一大圈。
先有鸡先有蛋:历史锁定效应
这里有一个深刻的系统设计规律:
- 早期设计了 SMP → 操作系统内核、编译器、语言运行时全都假设共享内存 → 软件生态繁荣 → 换掉 SMP 的代价无穷大。
- 即便后来出现了 NUMA(Non-Uniform Memory Access,不同 socket 的内存访问延迟不同),硬件和 OS 依然要维持统一共享内存的幻象,否则现有的所有软件都要重写。
这是工程史上典型的“路径依赖”:一个早期的架构决定,因为与上层系统深度耦合,即便后来发现它有代价,也再也下不了车。
###
| 动机 1(I/O) | 动机 2(多核) | |
|---|---|---|
| 问题 | syscall 让 CPU 空转 | 多核算力用不上 |
| 单进程解法 | 无法利用多核 | 进程间通信太重 |
| 共同答案 | 多线程:共享地址空间的多个执行流 |
线程(thread)正是为了同时解决这两个问题而生的:同一进程的多个线程共享内存,可以在不同 core 上并行运行,也可以在某个线程阻塞时让其他线程继续工作。
代价:共享内存意味着竞态条件(race condition)、数据竞争(data race),这正是后续课程要解决的核心问题。
共享内存并发 = 把”程序的确定性”这个我们赖以生存的假设打破了。
线程
1. 起点:什么是线程?
1.1 问题动机
单线程程序的执行模型很干净:一个 PC(程序计数器)+ 一个栈 + 一份内存,CPU 不断从 PC 取指令、执行、更新状态。
但现实需求是:
- 我想让程序的多个部分逻辑上同时推进(比如一边渲染 UI 一边下载文件)
- 我想利用多核 CPU 真正加速
最朴素的想法:开多个进程。但进程之间内存隔离,通信代价高。我们想要更轻的东西。
1.2 线程的本质定义
线程 = 独立的执行流 + 独立的栈 + 共享的全局内存(堆 + 全局变量 + 代码段)
为什么栈必须独立?因为执行流的本质就是“PC 在栈上推进函数调用”。如果两个执行流共享栈,函数调用帧就会互相覆盖,根本无法独立推进。
为什么其他东西可以共享?因为这正是线程“轻”的来源——共享地址空间意味着创建快、通信快(直接读写共享变量)。
关键洞察:“程序是独立执行的,但内存是共享的”——这一句话同时定义了线程的优势(高效通信)和所有麻烦的根源(下面所有问题都来自”共享”二字)。
1.3 状态机视角
把整个多线程程序看成一个状态机:
- 状态 = 所有线程的 PC + 所有线程的栈 + 共享内存
- 迁移 = 选择某个线程,执行它的下一条指令
这个视角后面会反复使用,因为它能精确刻画”非确定性”从何而来。
2. 并发 vs 并行
| 维度 | 并发 (Concurrency) | 并行 (Parallelism) |
|---|---|---|
| 含义 | 逻辑上同时执行 | 物理上同时执行 |
| 是否需要多核 | 不需要 | 需要 |
| 实现方式 | OS 调度轮转 | 多个 CPU 核心同时取指 |
| 关心的问题 | 程序结构、正确性 | 性能、加速比 |
关键点:并行是并发的一种实现方式,不是对立概念。一个并发程序在单核上是”轮流执行”,在多核上才变成真正的并行。
对应到状态机模型:
- 并发模型:每一步从所有线程中选一个,执行它的一条语句
- 并行模型:每一步多个线程同时各执行一条语句
常见误解:以为“我写了多线程程序就一定用上了多核”。实际上还要看 OS 调度、线程数量、以及程序里有没有锁导致串行化。
3. 最小线程 API:spawn 与 join
1
2
spawn(fn); // 创建线程,入口为 fn(int tid),立即开始执行
join(); // 等待所有线程结束(main 返回时默认 join)
这是把 pthread 简化到极致的版本——只够用来理解原理,没有任何实用性。真实 pthread 还有线程属性、取消、分离、TLS、信号处理……
一个实证”共享内存”的小程序
1
2
3
4
5
6
7
8
9
int x = 0, y = 0;
void inc_x() { while (1) { x++; sleep(1); } }
void inc_y() { while (1) { y++; sleep(2); } }
int main() {
spawn(inc_x);
spawn(inc_y);
while (1) { printf("x=%d, y=%d\n", x, y); }
}
主线程能看到 x 和 y 在变——这就证明了三个线程访问的是同一份 x、y,即共享内存。
4. 核心问题:确定性的崩塌
这是整份笔记最重要的一节。
4.1 什么是“确定性”
数学的确定性:函数 $f: X \to Y$,相同输入产生唯一输出。
程序的确定性:可以把程序看作状态迁移函数 $s’ = f(s)$。给定相同的初始状态,程序总是产生相同的指令序列和最终状态。
确定性为什么重要? 它是我们能“理解”和“调试”程序的基础——bug 是 reproducible 的,所以可以定位。这也是函数式编程吸引人的根本原因(SICP)。
4.2 单线程程序“几乎”是确定的
严格来说,单线程程序的不确定性来自外部:
- 初始状态:
argv、envp、auxv、ASLR - 系统调用:
getpid()、read()、时间相关调用 - 极少数指令:
rdrand(硬件随机)、rdtsc(时间戳)
但程序内部的计算——所有内存读写、算术指令——是完全确定的。给定相同输入,结果一致。
4.3 共享内存并发打破了一切
关键事实:线程执行的相对速度没有任何保证。
这意味着什么?回到状态机模型:每一步“选哪个线程执行”是任意的。一个 load 指令可能:
- 读到自己之前的 store
- 读到另一个线程刚写入的值
- 读到另一个线程即将覆盖的值
结果:相同的程序、相同的输入,不同次运行可能产生不同结果。确定性没了,可复现性没了,调试地狱开始了。
这就是多线程编程困难的根本原因。不是 API 复杂,不是概念抽象,而是非确定性让人类的”顺序推理”直觉彻底失效。
5. 案例一:支付系统的竞态条件
1
2
3
4
5
6
7
8
9
unsigned int balance = 100;
int T_alipay_withdraw(int amount) {
if (balance >= amount) { // (1) 检查
balance -= amount; // (2) 扣款
return SUCCESS;
}
return FAIL;
}
两个线程同时取 ¥100,余额只有 ¥100,会发生什么?
问题不在代码逻辑,而在 (1) 和 (2) 之间存在时间窗口。可能的执行交错:
1
2
3
4
5
线程A: 检查 balance >= 100 ✓
线程B: 检查 balance >= 100 ✓ ← 此时 A 还没扣!
线程A: balance -= 100 → balance = 0
线程B: balance -= 100 → balance = -100
↑ unsigned 下溢成天文数字!
这就是 Mt. Gox 损失 650,000 BTC 的类型(按当时算约 $280 亿)。
核心洞察:这种 bug 单线程测试永远测不出来。它依赖特定的指令交错,而这种交错可能 100 万次只出现 1 次——但对手会专门构造请求触发它。
6. 案例二:连 1+1 都不会算了
1
2
3
4
5
6
7
8
9
10
11
12
13
#define N 100000000
long sum = 0;
void T_sum() {
for (int i = 0; i < N; i++) sum++;
}
int main() {
spawn(T_sum);
spawn(T_sum);
join();
printf("sum = %ld\n", sum); // 期望 2*N,实际呢?
}
直觉上 sum 应该是 $2N$。实际跑出来通常远小于 $2N$。
为什么?因为 sum++ 不是一条指令,而是三条:
1
2
3
load r, [sum] // 把 sum 读到寄存器
add r, 1
store [sum], r // 写回
经典的丢失更新交错:
1
2
3
4
5
6
线程A: load r=5
线程B: load r=5 ← A 还没写回
线程A: add → r=6
线程A: store sum=6
线程B: add → r=6
线程B: store sum=6 ← A 的更新被覆盖!本应是 7
关键概念:这种“看起来是一步、实际是多步”的操作叫非原子操作。x++、x += y、甚至某些架构下的 64 位整数读写,都不是原子的。
思考:三个线程并发跑 T_sum(每个循环 3 次),sum 最小可能是多少?
假设 load/store 单行原子。每个线程做 3 轮 load → +1 → store。
1
2
3
4
5
6
7
8
9
10
11
12
A1.load → 0
B1.load → 0 (B 也提前 load)
A1.store → 1
A2.load → 1; A2.store → 2
B1.store → 1 (B 覆盖回 1)
A3.load → 1 (A 记住 1!)
B2.load → 1; B2.store → 2
B3.load → 2; B3.store → 3
C1.load → 3; ... C 完成 ... C3.store → 6 或类似
A3.store → 2 (A 用 1+1=2 覆盖)
最终 sum = 2 ✓
如果 9 次操作完全不重叠,sum = 9。让两个线程先完成全部,最后一个线程用很早 load 的值覆盖,即最后一次load到1, store 写入 2,sum 最小可以是 2。
7. 解药:互斥 (Mutex)
笔记最后提到 mutex_lock / mutex_unlock。它们的核心作用:
把一段代码标记为临界区,保证任意时刻最多一个线程在临界区内。这就把非原子操作“打包”成了逻辑上的原子操作。
1
2
3
4
5
6
7
8
mutex_t lk;
void T_sum() {
for (int i = 0; i < N; i++) {
mutex_lock(&lk);
sum++; // 现在整个 ++ 是原子的
mutex_unlock(&lk);
}
}
但这只是开始,会带来新问题:
- 性能:锁让并发退化成串行,可能比单线程还慢
- 死锁:多个锁的获取顺序错了会互相等待
- 公平性:某些线程可能长期拿不到锁
##
| 层面 | 收获 |
|---|---|
| 理论 | 共享内存并发的本质是状态机的非确定性迁移 |
| 抽象 | 线程 = 独立执行流 + 共享地址空间 |
| 陷阱 | 非原子操作 + 任意交错 = 难以复现的 bug |
| 工具 | 互斥锁是最基本的同步原语,但有代价 |
| 思维转变 | 从”按顺序读代码”升级到”考虑所有可能的交错” |
几个值得记住的“反直觉”事实
- 多线程程序未必用上了多核——取决于 OS 调度和锁竞争
- 每个线程有独立的栈,但栈的大小有限(通常几 MB),递归过深会栈溢出
x++不是原子的——这是新手最常踩的坑- bug 的不可复现性本身就是症状——意味着你写出了竞态条件
- 加锁只能恢复正确性,不能恢复确定性——多次运行结果可能仍不同(线程调度顺序不同),但每次都是正确的
简单关键命令:
info threads— 查看所有线程thread N— 切换到线程 Nset scheduler-locking on— 单步时锁住其他线程,方便复现break ... thread N— 只在某个线程触发的断点
“虽然把数学视角砍掉了,但状态机视角在理解并发程序时还是很有用。”
传统的“霍尔逻辑”(前置条件 → 语句 → 后置条件)这种顺序推理框架,在并发下会失效——因为任意位置都可能被其他线程“插一脚”修改共享状态。状态机 + 所有可能的交错(即“调度树”),是我们能形式化分析并发程序的最底层模型。后面学到的内存模型(happens-before、acquire/release)、模型检查(如 TLA+),本质上都是在这个状态机模型上做近似和约束。
内存一致性模型(为什么我自认为的状态机模型在真实硬件上还不够准确——CPU 会重排你的指令)
9. 一个看起来无害的例子
1
while (!flag);
直观语义:“等,直到另一个线程把 flag 设成 1,我就继续。”
这是一种最朴素的“自己造同步原语”的尝试——程序员希望用一个普通变量充当线程间的信号。
问题:这段代码在单线程语义下完全合法,编译器和 CPU 都把它当顺序程序优化。它们不知道也不在乎你的“线程间约定”。
关键洞察:你脑子里的“flag 表示同步”是约定,但编译器看到的是代码。它只对代码本身做等价变换,不理解你的意图。
10. 编译器在做什么:顺序语义下的”合法”破坏
10.1 案例 A:循环里的 flag 永远不会被读
1
while (!flag);
编译器视角的“合法推理”:
- 这是单线程程序(编译器假设)
- 循环体是空的,循环条件
!flag在循环内没有任何东西能改变 flag - 所以
flag的值在整个循环过程中不变 - 优化:把 load 提到循环外,只读一次
1
2
3
// 编译器优化后等价于:
register int t = flag;
while (!t); // 如果 t=0,死循环;如果 t≠0,跳过
结果:如果第一次读到 flag=0,永远死循环——即使另一个线程后来把 flag 设成 1,这段代码也看不到了。
10.2 案例 B:sum++ 在优化下的诡异结果
回到求和例子:
1
2
3
void T_sum() {
for (int i = 0; i < N; i++) sum++;
}
不开优化时,sum++ 老老实实展开成 load → +1 → store,在每次循环都访问内存。两个线程并发跑,丢失更新,sum < 2N——这是我们预期的。
但开了优化呢?
| 优化级别 | 实测结果 | 编译器做了什么 |
|---|---|---|
-O0 | 远小于 2N | load/store 每次都执行,但非原子 |
-O1 | 恰好 N | 把 sum 提到寄存器:reg = sum; for(...) reg++; sum = reg; |
-O2 | 恰好 2N | 进一步识别出循环本质是 sum += N,直接计算,恰好等于2N |
-O1 为什么正好是 N? 编译器把循环优化成:
1
2
3
long reg = sum; // 进入循环前 load 一次
for (int i = 0; i < N; i++) reg++;
sum = reg; // 循环结束后 store 一次
两个线程都 reg = 0,各自加到 N,然后几乎同时写回。最后一个写的覆盖前一个,sum = N。
-O2 为什么是 2N? 编译器进一步识别“循环本质是加 N”,直接生成:
1
sum += N; // 编译成 add 指令
在 x86 上,add [sum], N 是一条指令——而 x86 保证对齐 word 的单条 read-modify-write 指令在单核内是不可分的(虽然不是真原子,但在很多调度下表现得像原子)。所以两个线程各 +N,得到 2N。
11. 控制编译器的两种武器
方法 1:编译器屏障(compiler barrier)
1
while (!flag) { asm volatile ("" ::: "memory"); }
作用:告诉编译器“在这一点,假设所有内存都可能被改了,不要跨越这点做任何缓存/重排”。
机制拆解:
asm volatile:嵌入一段汇编,且这段汇编本身不可被优化掉"":空汇编,不生成任何机器指令::: "memory":clobber list 告诉编译器“这条指令可能会破坏所有内存”,编译器必须把所有缓存在寄存器里的变量丢弃,下次重新 load
注意:这只阻止编译器的优化,不阻止 CPU 的运行时重排。
方法 2:volatile 关键字
1
2
volatile int flag;
while (!flag);
作用:标记这个变量的每次 load/store 都必须真实发生,不能优化掉。
volatile 的真正含义:
- ✅ 每次访问都生成实际的 load/store 指令
- ✅ 不会把多次访问合并成一次
- ✅ 不会把访问顺序与其他 volatile 访问交换
- ❌ 不保证原子性
- ❌ 不阻止 CPU 重排
- ❌ 不能用作线程同步(在 C/C++ 中。Java 的 volatile 语义不同!)
常见误解:很多人以为 volatile 是“线程安全”的关键字。在 C/C++ 中根本不是。volatile 的设计初衷是处理“内存映射 I/O”——告诉编译器某个地址背后是硬件寄存器,每次读都可能不同。
操作系统课的态度
Don’t play with shared memory.
意思是:别自己用 volatile / 编译器屏障搞同步。这些都是知道自己在做什么的人才该碰的工具。正确做法是用封装好的同步原语:mutex、condition variable、atomic。这些原语的实现者已经替你处理了编译器和 CPU 的所有“小动作”。
12. 两层“编译”:问题不止在编译器
12.1 .c → .s(编译器编译)
编译器做的事我们已经看过:
- 把变量缓存到寄存器
- 调换语句顺序(如果它认为等价)
- 删除“死代码”
- 把循环展开 / 强度削减
- 把多次访问合并
12.2 .s → CPU 内部状态(处理器“编译”)
关键事实:现代 CPU 本身也是一个编译器。
它内部维护一个“指令窗口”(reorder buffer),可能同时有几十甚至上百条指令在流水线里。它会:
- 乱序执行(out-of-order execution):先执行已经准备好操作数的指令
- 推测执行(speculative execution):猜测分支结果,提前执行
- store buffer:写操作先放到 store buffer,慢慢刷到 cache
- 读到 store buffer 的”未来”值(store-to-load forwarding)
CPU 这么做的前提假设:单线程下结果不变。它做的所有重排都保证“如果只有一个线程在跑,结果和顺序执行一样”。
问题:这个假设和编译器一模一样——它们都不知道有别的线程在看。
关键洞察:处理器和编译器在“为单线程优化”这件事上是共谋。它们都假设你的程序是顺序的,都认为可以自由重排“等价”操作。一旦你引入共享内存并发,它们俩都成了你的对手。
13. 宽松内存模型(Relaxed Memory Model)
13.1 为什么会出现
一切为了性能。
- Cache 是必需的:内存比 CPU 慢两个数量级。每条 load/store 都直接打内存,CPU 大部分时间在等。
- 每个 CPU 核有自己的 L1 cache:A 核的 store 不会立刻被 B 核看到,要先经过 cache coherence 协议同步。
- Store buffer 是必需的:写内存比读内存还慢。CPU 把 store 先扔到 store buffer,继续往下执行,过会儿再刷出去。
- Load 不等 store buffer:B 核 load 时,A 核的 store 可能还在 A 的 store buffer 里没出来。
结果:站在程序员角度,写出去的东西,别的线程不一定立刻看到;看到的东西,可能是别人早就改过的旧值。
13.2 经典的 Litmus Test
1
2
3
4
5
6
7
8
9
10
11
int x = 0, y = 0;
void T_1() {
x = 1; // Store(x, 1)
int t1 = y; // Load(y)
}
void T_2() {
y = 1; // Store(y, 1)
int t2 = x; // Load(x)
}
问题:执行完后,(t1, t2) 可能是哪些值?
按”顺序一致”(每次任选一个线程执行一条)模型,可能的结果:
| 交错 | t1 | t2 |
|---|---|---|
| T1 全跑完,T2 全跑完 | 0 | 1 |
| T2 全跑完,T1 全跑完 | 1 | 0 |
| 交错执行 | 1 | 1 |
不可能出现 (0, 0)——因为如果 t1=0,说明 T1 的 load(y) 在 T2 的 store(y) 之前;同理 t2=0 说明 T2 的 load(x) 在 T1 的 store(x) 之前。但 T1 是先 store(x) 再 load(y),T2 是先 store(y) 再 load(x),逻辑上推不出。
实际结果:在 x86 和 ARM 上都能观察到 (0, 0)!
为什么? 两种可能(取决于硬件):
- Store buffer:T1 的
x=1进了 T1 的 store buffer,T2 的 load(x) 直接打 cache,看到旧值 0。同理对称。 - 乱序执行:CPU 觉得 store 和 load 没有数据依赖(不同地址),可以先做 load 再做 store。
这就叫 store-load 重排。在大多数架构上都允许。
13.3 内存模型的强弱
不同硬件的“宽松程度”不同:
| 架构 | 内存模型 | 允许的重排 |
|---|---|---|
| 顺序一致(理论) | 最强 | 不允许任何重排 |
| x86/x86-64 | TSO(Total Store Order) | 仅允许 store-load 重排 |
| ARM/POWER | 弱内存模型 | 允许 load-load、load-store、store-store、store-load 几乎所有重排 |
| Alpha(历史) | 极弱 | 连有依赖的 load 都可能重排(恶名昭著) |
Intel 的决定为何被吐槽:
- x86 的 TSO 比 ARM 强很多
- “强”意味着硬件要做更多保证(store buffer 排空、cache 同步),性能开销大
- 但又“不够强”——还是允许 store-load 重排,程序员写跨线程代码时仍然要小心
- 两头不讨好:既没强到让程序员不用动脑子,又拖了性能后腿
Rosetta 2 的“作弊”:Apple 的 M1 在跑 x86 程序时,需要模拟 x86 的 TSO 内存模型。但 ARM 默认是弱模型——硬模拟会非常慢。Apple 在 M1 里加了一个特殊模式:执行 x86 翻译代码时,CPU 切换到 TSO 模式。这是硬件级别的支持,普通 ARM 芯片做不到。
13.4 怎么”逆向”出一个架构的内存模型
像上面这样的小测试程序就叫 litmus test(石蕊测试)。研究者写出大量这样的小程序,每个测试一种特定的重排可能性,跑成千上万次,统计哪些”理论上不可能”的结果实际出现了——出现的就说明硬件允许这种重排。
这是逆向工程内存模型的标准方法。Russ Cox 的 《Memory Models》 系列是这个领域最好的入门读物。
14. 一个统一的世界观
到这里我们应该重新理解多线程程序的执行模型。
14.1 SimpleC 并发模型只是一个幻想
我们最初的并发模型是“每次选一个线程,执行一条语句”。这个模型有两层假设都不成立:
- 语句是原子的:错。
sum++是三条指令;甚至 64 位写在 32 位机上也不是原子的。 - 指令按程序顺序执行:错。编译器和 CPU 都会重排。
14.2 真实的执行模型
真实的多线程程序执行可以这样描述:
- 每个线程的指令序列经过编译器重排(保持单线程语义)
- 这些指令再经过 CPU 重排(保持单线程语义)
- 不同线程的最终指令流以几乎任意的顺序交错
- 每次 load 读到的值,由内存模型规定的规则决定(不是简单的“最近一次 store 的值”)
14.3 这是一把递给程序员的刀
整个共享内存并发的故事可以总结为:性能和正确性之间的赤裸交易,刀柄交给了程序员。
| 机制 | 给程序员的”方便” | 程序员要付出的代价 |
|---|---|---|
| 共享内存多线程 | 通信高效 | 1+1 都算不对(lost update) |
| 宽松内存模型 | 性能起飞 | 1, 2, 3 都数不清(重排可见) |
malloc/free | 灵活控制内存 | Use After Free / Double Free |
open/close | 灵活控制资源 | 资源泄漏 / 文件句柄耗尽 |
这些都是“高效但危险”的接口设计哲学。它们假设程序员”知道自己在做什么”。
这恰恰是为什么 Rust、Go、Java 这些”现代”语言要把刀子没收:
- Rust 的 ownership:编译期消灭 Use After Free 和数据竞争
- Java 的
synchronized+ 内存模型规范:把内存模型从”硬件细节”上升为”语言保证”- Go 的 channel:鼓励”通过通信共享内存”而不是”通过共享内存通信”
15. 总结
15.1 反直觉事实
while(!flag);在优化下是死循环——不是 bug,是编译器“对的”- 优化级别越高,多线程程序结果可能“越正常”——这是巧合,不是修复
- volatile 在 C/C++ 中不能用作线程同步——它解决的是另一个问题
- x86 看似“很强”的内存模型,仍然允许 store-load 重排
- 加锁不只是为了互斥,还为了内存可见性(mutex 实现里包含内存屏障)
- CPU 是个编译器——它在运行时做的事和编译器在编译时做的事,本质相同
15.2 实用准则
- 不要自己造同步原语。用 mutex、condvar、atomic。
- 不要用普通变量做线程间信号。用
atomic_int或锁保护。 - 不要假设语句是原子的。即使是单个变量的读写。
- 不要假设 A 线程的写 B 线程立刻能看到。
- 如果你必须用 atomic / volatile / barrier,先读三遍 C++ memory model 文档,再读 Russ Cox 的文章。
15.3 留给下一步的问题
笔记到这里铺垫了一个完整的问题图景:
- 我们知道问题是什么(共享内存 + 编译器/CPU 重排 = 不确定性灾难)
- 我们知道朴素方案不行(自己用变量同步、volatile 都不靠谱)
下一步自然要问:正确的同步机制是什么?怎么实现?性能代价多大?
主线包括:
- 原子操作(atomic)和硬件支持(CAS、LL/SC)
- 内存屏障(memory fence)的硬件指令
- 互斥锁的实现(从忙等到操作系统调度)
- 条件变量、信号量等高级原语
- Lock-free / Wait-free 数据结构
- C++/Java 的 memory model 规范
一个值得反复回味的视角
“顺序”这个概念,在系统的不同层次有不同的含义。
- 程序员写的 C 代码:一种顺序
- 编译器生成的汇编:另一种顺序(按单线程等价重排)
- CPU 实际执行的指令:又一种顺序(按动态依赖重排)
- 不同 CPU 核观察到的内存事件:还是不同的顺序(按 cache 同步规则)
这些顺序在单线程下被强制等价,所以单线程程序员永远不需要意识到差异。但一旦多个执行流共享状态,所有这些层次的差异都会“泄漏”出来,砸到程序员脸上。
理解多处理器编程的本质,就是理解这些“顺序”的层次结构,以及在每一层用什么工具能强制对齐它们。这就是内存屏障、原子操作、锁的意义——它们都是在某个层次上重新建立“我以为的顺序”和“实际的顺序”之间的对应关系。