存储管理
两条主线:内存空间的分配与回收,内存空间的扩充!

内存管理相关概念
内存空间的分配与回收
操作系统作为系统资源的管理者,当然需要对内存进行管理,在管理内存的时候,需要管理什么呢?
- 操作系统负责内存空间的分配与回收
- 操作系统需要提供某种技术从逻辑上对内存空间进行扩充
- 操作系统需要提供地址转换功能(地址重定位),负责程序的逻辑地址与物理地址
- 绝对装入:编译时产生绝对地址 — 单道程序阶段,此时没有操作系统
- 可重定位装入:装入时将逻辑地址转换为物理地址 — 用于早期的多道批处理操作系统
- 动态运行时装入:运行时将逻辑地址转换为物理地址,需要设置重定位寄存器 — 用于现代操作系统
- 操作系统需要提供内存保护功能,保证各进程在各自存储空间内运行,互不干扰
- 进程只能访问属于自己的进程空间,不能访问属于操作系统或是其他进程的内存空间
- 方法:
- 设置一对上下限寄存器,存放进程的上下限地址,进程的指令想要访问某一地址时,CPU检查是否越界
- 采用重定位寄存器(又称基址寄存器)和界地址寄存器(又称限长寄存器)进行越界检查。重定位寄存器存放进程的起始物理地址,界地址寄存器存放进程的最大逻辑地址。如果逻辑地址大于界地址寄存器里存放的地址,就会抛出越界异常,否则会和重定位寄存器里的地址相加,然后访问该物理地址的存储单元
进程的内存映像
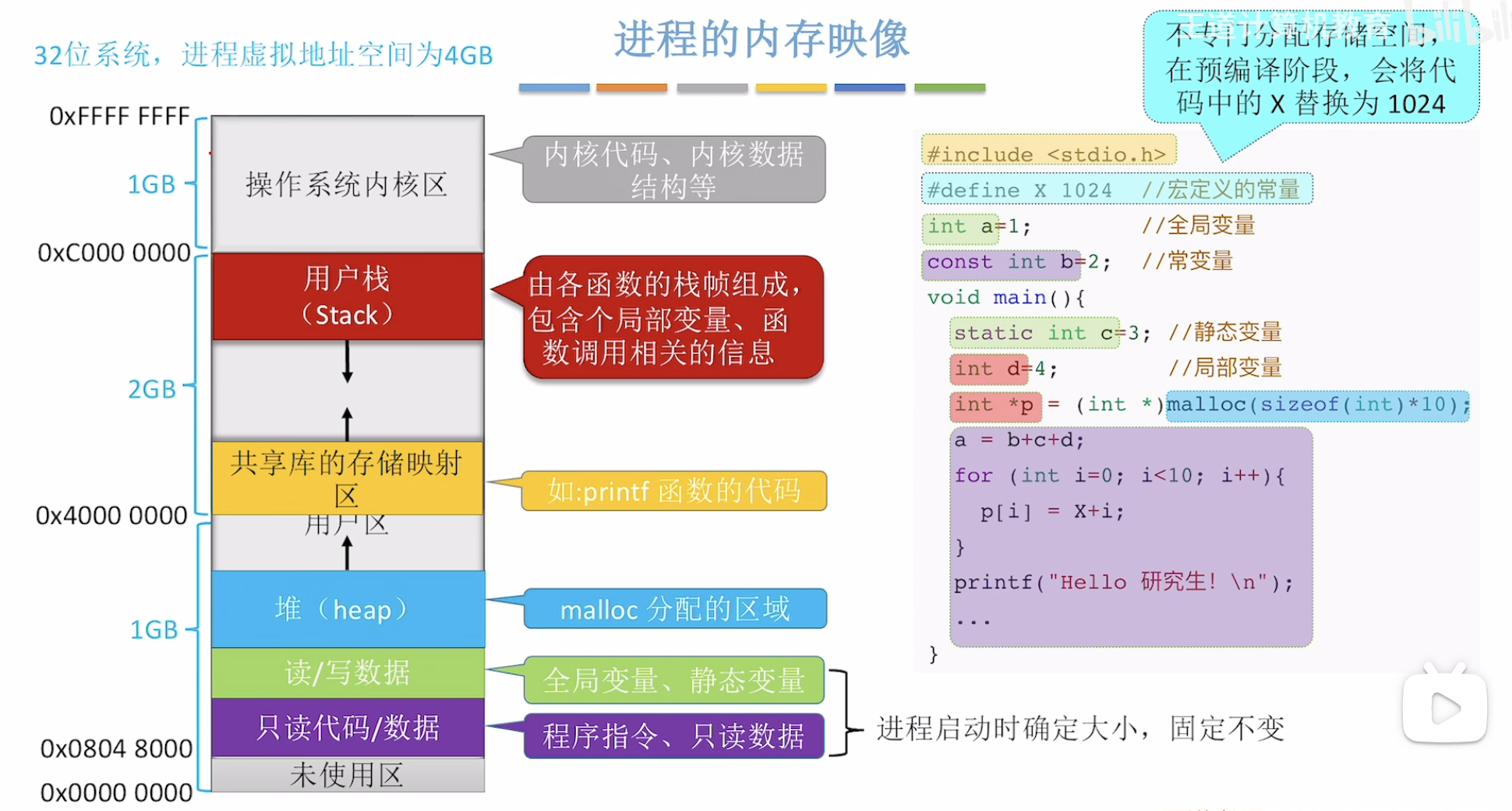
内存空间的扩充:覆盖与交换
覆盖
思想:将程序分为多个段(多个模块),常用的段常驻内存,不常用的段在需要时调入内存
内存中分为一个“固定区”和若干个“覆盖区”
需要常驻内存的段放在“固定区”中,调入后就不再调出(除非运行结束)
不常用的段放在“覆盖区”,需要用到时调入内存,用不到时调出内存
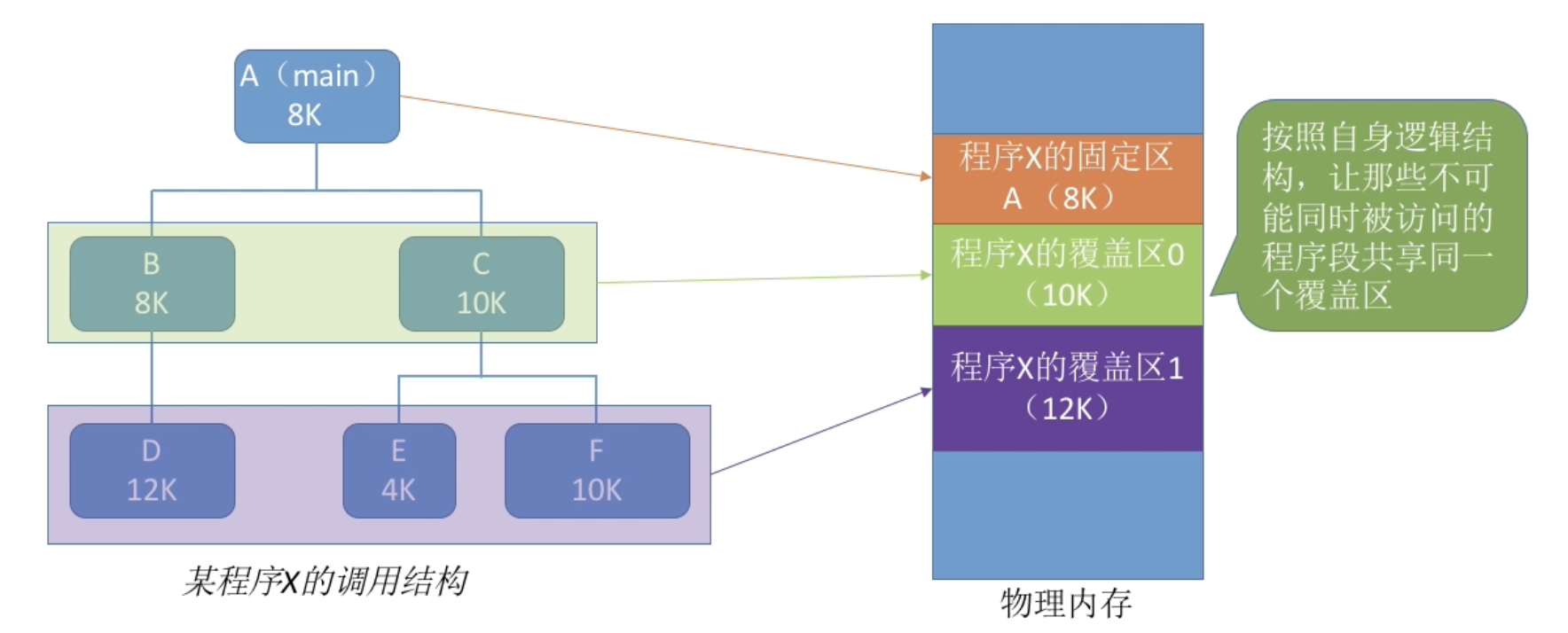
必须由程序员声明覆盖结构,操作系统完成自动覆盖。缺点:对用户不透明,增加了用户编程负担。覆盖技术只用于早期的操作系统中。
交换
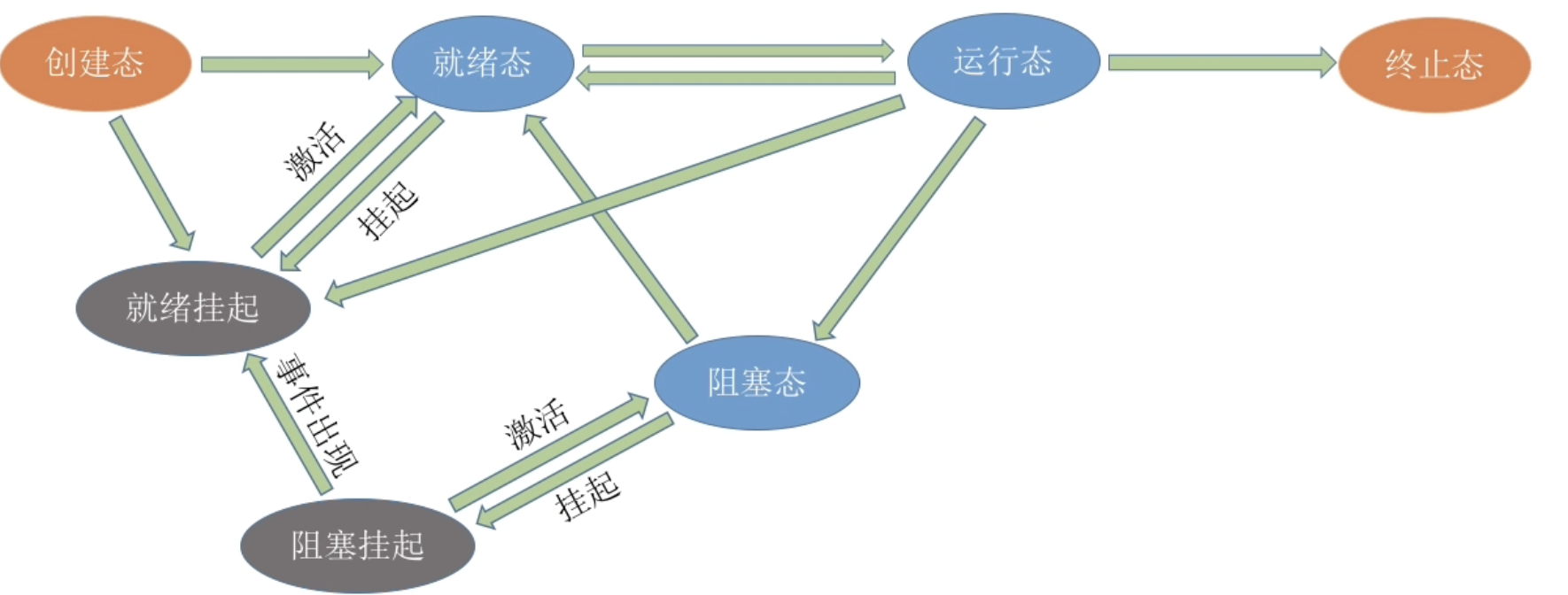
思想:当内存空间紧张时,系统将内存中某些进程暂时换出外存,把外存中某些已具备运行条件的进程换入内存(进程在内存与磁盘间动态调度)
暂时换出外存等待的进程状态为挂起状态(挂起态,suspend)
挂起态又可以进一步细分为就绪挂起、阻塞挂起两种状态
应该在外存(磁盘)的什么位置保存被换出的进程?
具有对换功能的操作系统中,通常把磁盘空间分为文件区和对换区两部分。文件区主要用于存放文件,主要追求存储空间的利用率,因此对文件区空间的管理采用离散分配方式;对换区空间只占磁盘空间的小部分,被换出的进程数据就存放在对换区。由于对换的速度直接影响到系统的整体速度,因此对换区空间的管理主要追求换入换出速度,因此通常对换区采用连续分配方式。总之,对换区的 I/O 速度比文件区的更快。
什么时候应该交换?
交换通常在有许多进程运行且内存吃紧时进行,而系统负荷降低时就暂停。例如:当发现许多进程在运行时经常发生缺页,说明内存紧张,此时可以换出一些进程;如果缺页率明显下降,就可以暂停换出。
应该换出哪些进程?
可优先换出阻塞进程,也可换出优先级低的进程。为了防止优先级低的进程在被调入内存后很快又被换出,有的系统还会考虑进程在内存的驻留时间等其他因素。
(PCB会常驻内存,不会被换出外存)
内存空间的分配与回收
连续分配管理方式
单一连续分配

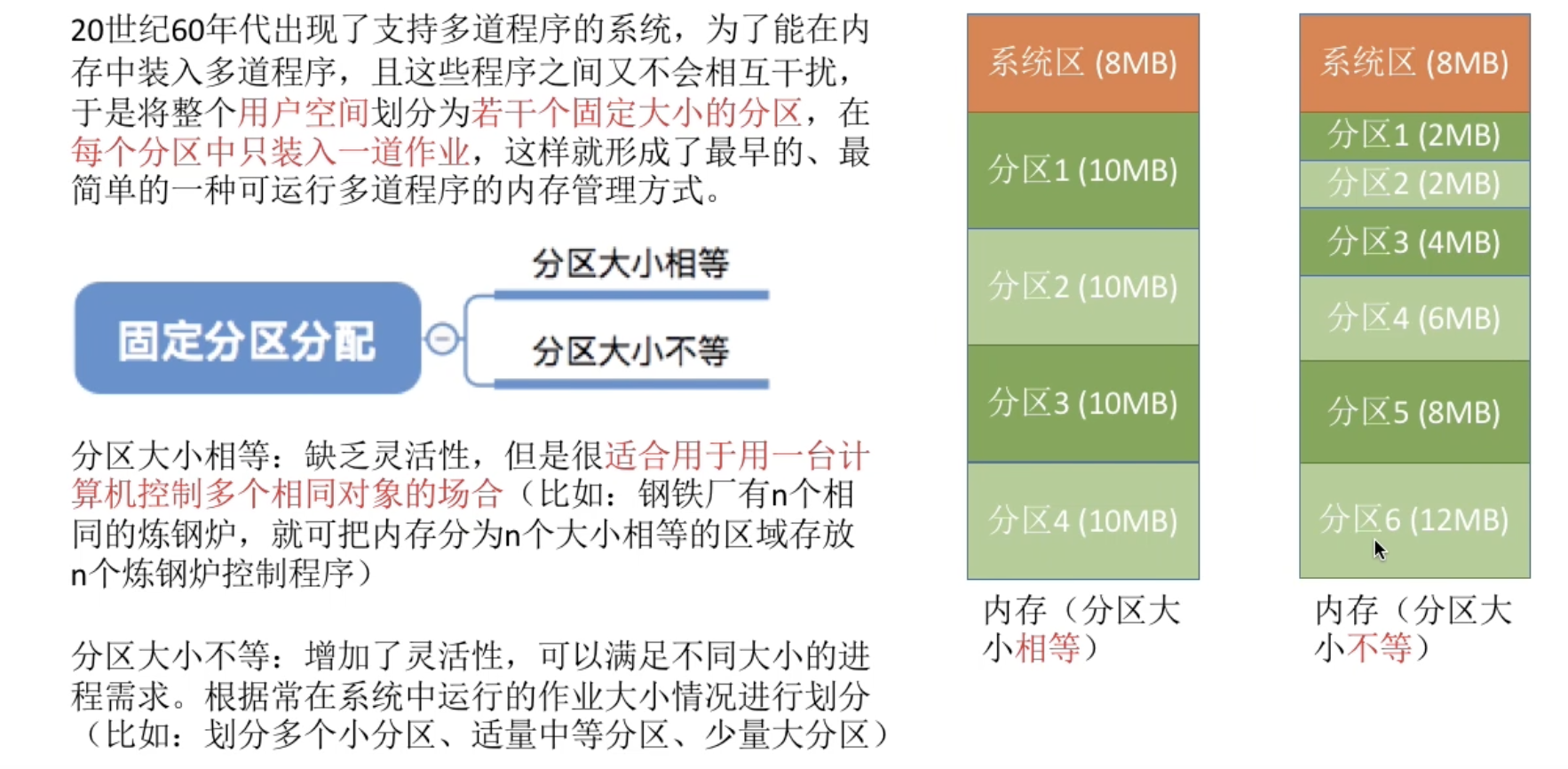
固定分区分配
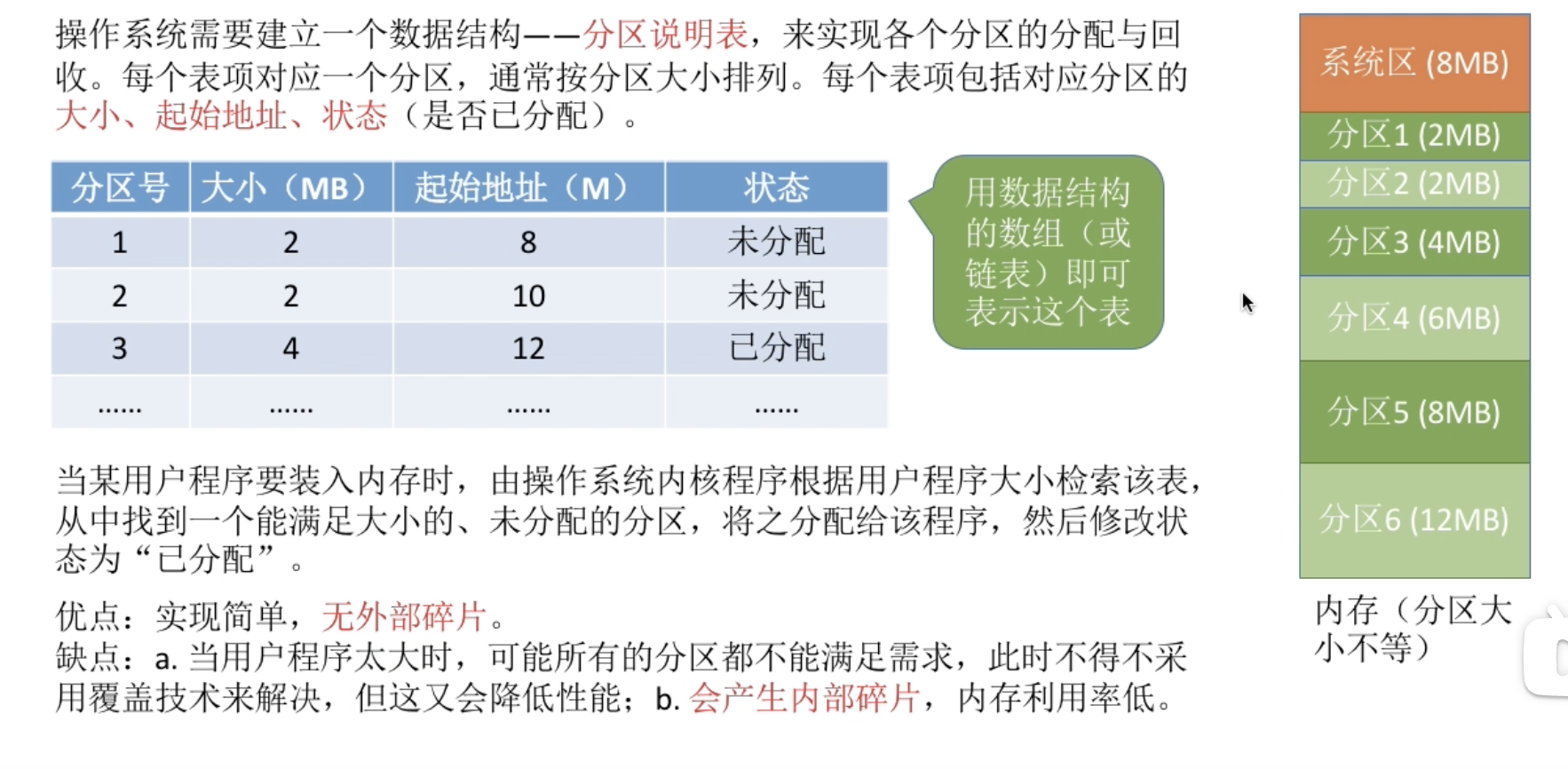
动态分区分配
动态分区分配又称为可变分区分配。这种分配方式不会预先划分内存分区,而是在进程装入内存时,根据进程的大小动态地建立分区,并使分区的大小正好适合进程的需要。因此,系统分区的大小和数目是可变的。(例如:假设某计算机内存大小为 64MB,系统区占 8MB,用户区共 56MB……)
系统使用什么样的数据结构记录内存的使用情况
空闲分区表:每个空闲分区对应一个表项,表项中包含分区号、分区大小、分区起始地址等信息
空闲分区链:每个分区的起始部分和末尾部分分别设置前向指针和后向指针。起始部分处还可以记录分区大小等信息
当有很多空闲分区都能满足需求时,应该选择哪个分区进行分配?
动态分区分配算法
如何进行分区的分配与回收操作?(以空闲分区表为例)
分配:直接修改分区大小和起始地址,如果分区大小会占满整个空闲分区,就直接从空闲分区表中删除
回收:改变分区大小和起始地址,或者合二/三为一,或者新增表项
动态分区分配没有内部碎片,但是有外部碎片。
- 内部碎片:分配给某进程的内存区域中,有些部分没有用上。
- 外部碎片:内存中的某些空闲分区由于太小而难以利用。
如果内存中空闲空间的总和本来可以满足某进程的要求,但由于进程需要的是一整块连续的内存空间,因此这些“碎片”不能满足进程的需求。可以通过紧凑(拼凑,Compaction)技术来解决外部碎片。【其实就是“挪位”】
—动态重定位!
动态分区分配算法
首次适应算法(First Fit)
- 算法思想:每次都从低地址开始查找,找到第一个能满足大小的空闲分区。
- 如何实现:空闲分区以地址递增的次序排列。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
最佳适应算法(Best Fit)
算法思想:由于动态分区分配是一种连续分配方式,为各进程分配的空间必须是连续的一整片区域。因此为了保证当“大进程”到来时能有连续的大片空间,可以尽可能多地留下大片的空闲区,即,优先使用更小的空闲区。
如何实现:空闲分区按容量递增次序链接。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
缺点:会留下来越来越多的、很小的、难以利用的内存块,从而产生很多的外部碎片
最坏适应算法(Worst Fit)
- 算法思想:为了解决最佳适应算法的问题——即留下太多难以利用的小碎片,可以在每次分配时优先使用最大的连续空闲区,这样分配后剩余的空闲区就不会太小,更方便使用。
- 如何实现:空闲分区按容量递减次序链接。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
缺点:后续如果有大进程到达,就容易没有内存分区可用了
邻近适应算法(Next Fit)
算法思想:首次适应算法每次都从链头开始查找,可能会导致低地址部分出现很多小的空闲分区,而每次分配查找时都要经过这些分区,增加了查找的开销。如果每次都从上次查找结束的位置开始检索,就能解决上述问题。
如何实现:空闲分区以地址递增的顺序排列(可排成一个循环链表)。每次分配内存时从上次查找结束的位置开始查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
非连续分配管理方式
基本分页存储管理









基本地址变换机构
系统中设置了一个页表寄存器(PTR),用于存放当前运行进程的页表在内存中的起始地址 F 和页表长度 M。当进程未执行时,这些信息保存在进程控制块(PCB)中;当进程被调度执行时,操作系统内核会将页表起始地址和页表长度从 PCB 加载到页表寄存器中。
注意,页面大小 L 是 2 的整数幂。逻辑地址 A 转换为物理地址 E 的过程,就是利用页表寄存器中的信息,结合逻辑地址中的页号和页内偏移量,通过页表查找对应的物理块号,最终计算出物理地址。

设页面大小为 $L$,逻辑地址 $ A $ 到物理地址 $ E $ 的变换过程如下: ①计算页号 $ P $ 和页内偏移量 $ W $(如果用十进制数手算,则 $ P=A/L $、$ W=A\%L $;但是在计算机实际运行时,逻辑地址结构是固定不变的,因此计算机硬件可以更快地得到二进制表示的页号、页内偏移量) ②比较页号 $ P $ 和页表长度 $ M $,若 $P \geq M$,则产生越界中断,否则继续执行。(注意:页号是从0开始的,而页表长度至少是1,因此 $ P=M $ 时也会越界) ③页表中页号对应的页表项地址 = 页表起始地址 + 页号 * 页表项长度,取出该页表项内容 $ b $,即为内存块号。(注意区分页表项长度、页表长度、页面大小的区别。页表长度指的是这个页表中总共有几个页表项,即总共有几个页;页表项长度指的是每个页表项占多大的存储空间;页面大小指的是一个页面占多大的存储空间) ④计算 $ E=b*L+W $,用得到的物理地址 $ E $ 去访存。(如果内存块号、页面偏移量是用二进制表示的,那么把二者拼接起来就是最终的物理地址了)

基本分段存储管理



段页式存储管理


内存空间的扩充

PPT整理,使用小猫神力展开领域!
存储管理基础
存储管理的主要模式
地址的概念
- 逻辑地址(相对地址):用户编程所使用的地址空间,从 0 开始编号
- 一维逻辑地址:单一地址
- 二维逻辑地址:
段号 : 段内地址
- 物理地址(绝对地址):程序执行时处理器实际使用的地址空间
段式程序设计
- 把一个程序设计成多个段:代码段、数据段、堆栈段等
- 用户可以自己应用段覆盖技术扩充内存空间使用量
- 段覆盖是程序设计技术,不是 OS 存储管理的功能
主存储器的复用
多道程序设计需要复用主存,有两种方式:
| 复用方式 | 划分方法 | 占用方式 |
|---|---|---|
| 按分区复用 | 主存划分为多个固定/可变尺寸的分区 | 一个程序/程序段占用一个分区 |
| 按页框复用 | 主存划分成多个固定大小的页框(page frame) | 一个程序/程序段占用多个页框 |
四种基本存储管理模式
| 模式 | 逻辑地址空间 | 主存分配方式 |
|---|---|---|
| 单连续存储管理 | 一维 | 一个固定分区或可变分区 |
| 页式存储管理 | 一维 | 多个主存页框 |
| 段式存储管理 | 二维(段式) | 多个可变分区 |
| 段页式存储管理 | 二维(段式) | 多个主存页框 |
关键理解:编译连接后的可执行程序,根据逻辑地址空间结构(一维 vs 二维),选择不同的存储管理方式映射到物理内存。四种方式都可以支持虚拟化和共享。
存储管理的功能
1. 地址转换(重定位)
将逻辑地址转换为绝对地址,有两种方式:
- 静态重定位:程序装入内存时进行地址转换,由装入程序执行,早期小型 OS 使用
- 动态重定位:CPU 执行程序时进行地址转换,依赖硬件地址转换机构,效率更高
2. 主存空间的分配与去配
- 分配:进程装入主存时,存储管理软件进行主存分配,并设置表格记录分配情况
- 去配:进程撤离或归还主存时,收回存储空间,调整主存分配表
3. 主存空间的共享
- 共享主存资源:多道程序设计中,多个程序同时驻留主存
- 共享主存区域:协作进程共享程序块或数据块
4. 存储保护
- 私有主存区:可读可写
- 公共区共享信息:根据授权
- 非本进程信息:不可读写
- 软硬件协同完成:CPU 检查访问权限,不允许则产生地址保护异常,由 OS 处理
5. 主存空间的扩充
| 技术 | 原理 | 实现方式 |
|---|---|---|
| 对换技术 | 把不运行的进程整体调出到磁盘 | 对换进程决定对换,硬件调入 |
| 虚拟技术 | 只调入进程的部分内容 | CPU 遇到不在主存的地址 → 虚拟地址异常 → OS 调入 → 重执指令 |
虚拟存储器的概念
提出背景
- 问题:主存容量有限,用户编程受限,多道程序设计道数受限
- 观察:程序执行具有局部性——顺序性、循环性(空间局部性)、某阶段集中执行(时间局部性)
- 结论:不必将进程全部装入主存,可以部分调入
基本思想
- 进程全部信息放在辅存中
- 执行时先将一部分装入主存
- 根据执行行为随用随调入
- 主存空间不足时,将暂时不用的信息调出到辅存
实现思路
- 建立并自动管理两个地址空间:
- (辅存) 虚拟地址空间:容纳进程装入
- (主存) 实际地址空间:承载进程执行
- 对用户透明,用户感知到一个容量大得多的主存空间
存储管理的硬件支撑
存储器层次结构
1
2
3
4
5
6
7
8
9
L0: 寄存器 ← 最快、最小、最贵
L1: L1 Cache (SRAM) ← 分指令缓存和数据缓存,32-256KB
L2: L2 Cache (SRAM) ← 512KB-8MB
L3: L3 Cache (SRAM) ← 多核共享
L4: 主存 (DRAM)
L5: SSD(本地固态硬盘)
L6: 本地硬盘
L7: 远程存储(分布式文件系统、Web服务器)
← 最慢、最大、最便宜
高速缓存 Cache
- 介于 CPU 和主存之间的高速小容量存储器(SRAM)
- 组成:高速存储器 + 联想存储器 + 地址转换部件 + 替换逻辑
- 联想存储器:按内容寻址(非按地址访问)
- 地址转换部件:命中时直接访问 Cache;未命中时从内存读入 Cache
- 替换部件:缓存满时按策略替换数据块
地址转换 / 存储保护的硬件支撑
- 基址寄存器 + 限长寄存器:定义允许访问的地址范围
- 逻辑地址 + 基址 = 物理地址
- 逻辑地址 > 限长 → 越界中断
核心要点:动态重定位、存储保护、虚拟存储器都必须有硬件支撑,否则在效率上没有实现价值。
单连续分区存储管理
单连续分区存储管理
每个进程占用一个物理上完全连续的存储空间。
1. 单用户连续分区
- 主存划分为系统区和用户区
- 设置栅栏寄存器界分两个区域
- 一般采用静态重定位
- 适用于单用户单任务 OS(如 DOS)
2. 固定分区
- 分区数量固定、大小固定
- 可用静态重定位,硬件实现代价低
- 主存分配表记录每个分区的起始地址、长度、占用标志
- 地址转换:下限寄存器 B + 上限寄存器,逻辑地址加上基址,超过上限则越界中断
3. 可变分区(详见 3.2.2)
可变分区存储管理
基本思想
- 按进程的实际内存需求动态划分分区
- 创建进程时查看是否有足够空闲空间:有则按需分割,无则等待
- 分区个数随机变化
主存分配表
使用链表维护:
- 已分配区表:记录每个已分配区的起址、长度、占用进程
- 未分配区表:记录每个空闲区的起址、长度
四种分配算法
| 算法 | 英文 | 策略 | 特点 |
|---|---|---|---|
| 最先适应 | First Fit | 从头开始找第一个够大的空闲区 | 简单快速,倾向于在低地址产生碎片 |
| 邻近适应 | Next Fit | 从上次分配位置开始找 | 分布更均匀 |
| 最优适应 | Best Fit | 找最小的够用空闲区 | 最容易产生外零头 |
| 最坏适应 | Worst Fit | 找最大的空闲区 | 避免小碎片,但大空闲区消耗快 |
内存回收
回收进程 X 的内存时,需要考虑与相邻空闲区的合并(上邻、下邻、上下都邻、上下都不邻四种情况)。
地址转换与存储保护
- 使用基址寄存器和限长寄存器
- 逻辑地址 < 限长 → 绝对地址 = 基址 + 逻辑地址
- 逻辑地址 ≥ 限长 → 越界中断
内存零头问题
| 类型 | 产生原因 |
|---|---|
| 内存内零头(内部碎片) | 固定分区方式,分配的分区大于实际需要 |
| 内存外零头(外部碎片) | 可变分区方式,产生小的不可用内存分区 |
- 任何适配算法都不能避免外零头
- 最优适配算法最容易产生外零头
移动技术(程序浮动技术)
- 目的:移动分区以消除外零头,合并出连续大空闲区
- 前提:需要动态重定位支撑
- 流程:请求分配 → 无足够大空闲区 → 检查空闲区总和是否够 → 移动现有分区 → 修改基址/限长 → 分配
页式存储管理
页式存储管理的基本原理
核心思想
- 主存划分为多个大小相等的页框(frame)
- 程序的逻辑地址自然分成等大小的页(page)
- 不同的页可以放在不同页框中,不需要连续
- 页表维系进程的主存完整性(页号 → 页框号的映射)
地址结构
1
2
逻辑地址:| 页号 | 单元号(页内偏移) |
物理地址:| 页框号 | 单元号(页内偏移) |
地址转换过程:通过页号查页表得到页框号,拼接单元号形成物理地址。
内存分配/去配
- 使用位示图记录主存页框分配情况(0=空闲,1=已分配)
- 建立进程页表维护逻辑完整性
页的共享
- 数据共享:不同进程可以用不同页号共享数据页
- 程序共享:不同进程必须使用相同页号共享代码页
- 原因:共享代码页中的
JMP <页内地址>指令,不同页号无法正确跳转 - 需要编译为位置无关代码(PIC):
gcc -fpic
- 原因:共享代码页中的
分页寻址计算示例
页面与页框大小为 1024 字节,指令 MOV 2100, 3100:
2100 = 1024 × 2 + 52→ 页号 2,偏移 52 → 查页表得页框号 6 → 物理地址 = 6 × 1024 + 52 = 61963100 = 1024 × 3 + 28→ 页号 3,偏移 28 → 查页表得页框号 8 → 物理地址 = 8 × 1024 + 28 = 8220
页式存储管理的地址转换
地址转换代价问题
- 页表放在主存 → 每次地址转换需要访问两次主存:
- 按页号读出页框号
- 按绝对地址进行读写
- 问题:存取速度降低一倍
- 解决:利用 Cache 存放部分页表 → 快表(TLB)
快表(TLB, Translation Lookaside Buffer)
- 专用高速存储器(联想存储器),按内容寻址
- 存放页表的一部分(热点页表项)
- 表项内容:页号 → 页框号
引入快表后的性能计算
例:主存访问 200ns,快表访问 40ns,命中率 90%
平均地址转换代价 = (200 + 40) × 90% + (200 + 200 + 40) × 10% = 260ns
比两次访存(400ns)下降了 35%
快表地址转换流程
- 按逻辑地址中的页号查快表
- 命中:由页框号和单元号直接形成绝对地址
- 未命中:查主存页表形成绝对地址,同时将该页登记到快表
- 快表满时,按策略淘汰一个旧登记项
多道程序环境
- 进程表登记每个进程的页表起始地址和长度
- 进程运行时,页表起始地址和长度送入页表控制寄存器
- 地址转换时先比较页号是否越界(页号 ≥ 页表长度 → 越界中断)
页式虚拟存储管理
程序局部性原理
这是虚拟存储器的理论基础(Denning, 1968):
- 时间局部性(temporal locality):最近访问的代码和数据,很快又被访问
- 空间局部性(spatial locality):某存储单元被使用,其相邻单元很快也被使用
局部性的来源:
- 程序大量顺序执行指令
- 循环结构——少量代码多次执行
- 过程调用深度有限,指令引用局限在少量过程中
- 数组等数据结构的连续引用
- 程序某些部分彼此互斥,不是每次都用到
抖动(Thrashing)
- 定义:页面刚被淘汰就又要调入,CPU 大部分时间用于交换页面而非执行指令
- 原因:分配给进程的页框数不够,或页面调度算法不当
基本思想
- 进程全部页面装入虚拟存储器(辅存)
- 执行时先把部分页面装入主存
- 根据执行行为动态调入不在主存的页
- 必要时调出暂时不用的页
- 请求页式:首次只装入进程第一页
扩充的页表项
1
| 标志位 | 主存块号 | 辅助存储器地址 |
标志位包括:
- 主存驻留标志:该页是否在主存中
- 写回标志(修改位):该页是否被修改过
- 保护标志:读/写/执行权限
- 引用标志:是否被访问过
- 可移动标志
地址转换流程(含缺页处理)
1
2
3
4
5
6
7
8
9
10
按逻辑地址查快表
├── 命中 → 形成绝对地址 → 继续执行
└── 未命中 → 查页表
├── 该页在主存 → 形成绝对地址 + 登记入快表
└── 该页不在主存 → 发缺页中断
├── 有空闲页框 → 调入页面 → 更新页表/快表
└── 无空闲页框 → 选择淘汰页
├── 淘汰页已修改 → 写回辅存
└── 淘汰页未修改 → 直接覆盖
→ 调入新页 → 更新页表/快表 → 重执指令
页面调度
基本概念
- 页面调度:主存空间已满时,选择淘汰页的工作
- 缺页中断率
f = F / A- F:不成功访问次数(缺页次数)
- A:总访问次数
- 是衡量存储管理性能和用户编程水平的重要依据
影响缺页中断率的因素
- 分配的页框数:越多 → 缺页率越低
- 页面大小:越大 → 缺页率越低
- 用户编程方法:大数据量下影响显著
用户编程示例
仅分得 1 个页框,页面 128 字,数组 A[128][128] 按行存放:
1
2
3
4
5
6
7
8
9
10
11
// 按列访问:每次赋值都缺页
for(j=0; j<128; j++)
for(i=0; i<128; i++)
A[i][j] = 0;
// 缺页次数:128×128 - 1 = 16383 次
// 按行访问:每换一行才缺页
for(i=0; i<128; i++)
for(j=0; j<128; j++)
A[i][j] = 0;
// 缺页次数:128 - 1 = 127 次
关键启示:数据按行存放时,按行访问符合空间局部性,缺页率大幅降低。
页面调度算法
1. OPT(最佳算法,Belady 算法)
- 淘汰以后不再访问的页,或距现在最长时间后再访问的页
- 只可模拟,不可实现(需要预知未来的访问序列)
- 作为其他算法性能评估的理论下界
2. FIFO(先进先出)
- 淘汰最先调入主存的页(驻留时间最长的页)
- 模拟程序执行的顺序性,有一定合理性
- Belady 异常:增加页框数反而可能导致缺页率增加(FIFO 特有)
3. LRU(最近最少使用)
- 淘汰最近一段时间最久未被访问的页
- 模拟程序的局部性:既考虑循环性又兼顾顺序性
- 严格实现代价大(需要维持特殊队列记录访问顺序)
- 模拟实现:
- 每页设引用标志位
- 设置时间间隔中断:中断时引用标志置 0
- 地址转换时引用标志置 1
- 淘汰时从引用标志为 0 的页中随机选择
4. LFU(最不常用)
- 淘汰最近一段时间访问次数最少的页
- 每页设一个计数器
- 时间间隔中断时所有计数器清 0
- 每访问一次计数器加 1
- 淘汰计数值最小的页
5. CLOCK(时钟算法)
- 采用循环队列构造页面队列(环形结构)
- 使用页引用标志位
- 工作流程:
- 页面调入/访问时,引用标志位置 1
- 淘汰时从指针当前位置开始扫描:
- 引用位 = 1 → 清 0,跳过
- 引用位 = 0 → 淘汰该页,指针推进一步
算法性能比较
1
性能(缺页率低 → 高):OPT > LRU ≈ LFU > CLOCK > FIFO
注意:这是整体比较,个案中 CLOCK 可能优于 LRU。
Belady 异常
- 现象:FIFO 算法中,增加页框数反而导致更多缺页
- 原因:FIFO 不考虑页面的使用频率,仅按进入顺序淘汰
- 注意:LRU 和 OPT 不存在 Belady 异常
页的大小设计
| 页面大小 | 优点 | 缺点 |
|---|---|---|
| 较小 | 内部碎片少 | 页数多 → 页表大 → 页表可能要放入虚存 |
| 较大 | 适合磁盘大块传输;页表小 | 内部碎片多 |
- 极端情况:页面极大 → 退化为固定分区;页面覆盖全部 → 全部装载
- 部分系统支持多种页面大小以灵活利用 TLB
补充:伙伴系统(Buddy System)
基本原理(Knuth, 1973)
- 任何大小为 2^i 的空闲块可以分为两个大小为 2^(i-1) 的伙伴
- 两个伙伴可以合并成原来的 2^i 空闲块
- 是固定分区和可变分区的折中方案
Linux 中的伙伴系统
mem_map[]数组:以page结构为元素free_area数组:以free_area_struct为元素- 位图数组(bitmap)记录伙伴状态
Linux Slab 分配器
问题:伙伴系统以页框为基本分配单位,但内核常需要远小于页框的内存(如 inode、task_struct 等)
解决:基于伙伴系统的 Slab 分配器(源自 SunOS)
- 思想:为常用小对象建立缓存,申请/释放通过 slab 管理,缓存不够时才向伙伴系统申请
- 优点:减少内部碎片、对象管理局部化、减少与伙伴系统交互
- 结构:
- 多个 cache,每个 cache 管理特定类型对象
- 每个 cache 包含三类 slab:满 slab、半满 slab、空 slab
- 13 种通用缓存:32B, 64B, 128B, …, 128KB(2 的幂次增长,碎片率 ≤ 50%)
关键操作:
kmem_cache_create():创建专用 cachekmem_cache_alloc()/kmem_cache_free():分配/释放对象kmem_cache_grow()/kmem_cache_reap():向伙伴系统申请/回收 slabkmalloc()/kfree():通用缓冲区的申请/释放
补充:局部页面替换算法
1. 局部最佳页面替换算法(MIN,Prieve, 1976)
- 类似 OPT,需事先知道页面引用串
- 思想:进程在时刻 t 访问某页面后,如果该页在时间间隔 (t, t+τ) 内未被再次引用,则移出;否则保留
- τ 为系统常量,(t, t+τ) 称为滑动窗口
- 驻留集大小动态变化
- 向前看(看未来)
2. 工作集模型(Denning, 1968)
- 工作集 W(t, Δ):时刻 (t-Δ, t) 内进程所访问的页面集合
- Δ 称为工作集窗口尺寸
- 工作集中的页面数称为工作集尺寸
- 向后看(看过去),模拟局部最佳算法
工作集替换算法:
- 在时刻 t,检查 (t-Δ, t) 窗口内被引用的页面
- 不在窗口内引用过的页面被移出驻留集
- 驻留集大小随命中率动态调整
工作集的应用:
- 监视每个进程的工作集
- 定期从驻留集中删除不在工作集中的页面
- 仅当工作集在主存时,进程才能执行
缺页频率策略(PFF):
- 定义缺页率上界 U 和下界 L
- 缺页率 > U → 分配更多页框
- 缺页率 < L → 减少页框
- 驻留集大小应接近工作集大小 W
反置页表
多级页表
问题:32 位地址空间,4KB 页面 → 2^20 个页 → 页表占 4MB 连续空间,多进程下开销巨大
解决:多级页表
- 二级页表:页目录表(一级) + 页表页(二级)
- 逻辑地址结构:
| 页目录 | 页表页号 | 偏移 | - 本质:多级不连续导致多级索引
- 页目录项 → 页表页的索引
- 页表页项 → 程序页面的索引
- 代价:增加寻址时间(时间换空间)
- SUN SPARC 使用三级分页结构
反置页表(Inverted Page Table, IPT)
问题:传统页表大小与虚拟地址空间成正比
核心思想:
- 不按虚拟页号建表,而是针对内存中的每个页框建立一个表项
- 按页框号排序
- 表项包含:进程标识、页号、特征位、哈希链指针
- 不论多少进程和虚拟页,页表大小固定 = 物理页框数
地址转换过程:
- 用进程标识 + 虚页号经哈希函数得到哈希值
- 哈希值指向哈希表中的一个表目
- 遍历哈希链找到匹配的进程标识和页号
- 该表项的索引即为页框号
- 页框号 + 偏移 → 物理地址
- 未找到匹配项 → 缺页中断
应用:PowerPC, UltraSPARC, IA-64
段式存储管理
段式存储管理
段式程序设计
- 程序由若干段组成,每段从 0 开始编址,段内地址连续
- 逻辑地址:
段号 : 段内偏移 - 典型分段:主程序段、子程序段、工作区段、数据段
基本思想
- 基于可变分区存储管理,一个进程占用多个分区
- 硬件增加段地址寄存器(代码段、数据段、堆栈段、附加段)
- 段表:每段一个表项
- 段始址、段限长
- 存储保护、可移动、可扩充标志位
地址转换流程
1
2
3
4
5
6
段表控制寄存器 → 获取当前段表
→ 按逻辑地址中段号查段表
→ 获得段始址和段长
→ 单元号 < 段长?
├── 是 → 绝对地址 = 段始址 + 单元号
└── 否 → 越界中断
段的共享
- 不同进程段表中的项指向同一个段基址
- 共享段需要保护(如只读),不满足保护条件则产生保护中断
分段寻址计算示例
段号 2,段内偏移 100,查段表得段 2 的基址为 8K:
- 物理地址 = 8K + 100 = 8192 + 100 = 8292
段式虚拟存储管理
基本思想
- 所有分段存放在辅存
- 运行时装入当前需要的段
- 访问不在主存的段时动态装入
- 由 OS 自动实现,对用户透明(区别于段覆盖技术——用户控制)
扩充的段表
1
| 段号 | 特征位 | 存取权限 | 扩充位 | 标志位 | 主存始址 | 限长 | 辅存始址 |
- 特征位:00=不在内存,01=在内存,11=共享段
- 存取权限:00=可执行,01=可读,11=可写
- 扩充位:0=固定长,1=可扩充
- 标志位:00=未修改,01=已修改,11=不可移动
地址转换流程
1
2
3
4
5
6
7
8
9
10
11
12
访问 S 段 B 单元
→ S 段在内存?
├── 是 → B < S 段长度?
│ ├── 是 → 符合存取权限?
│ │ ├── 是 → 形成绝对地址
│ │ └── 否 → 保护中断
│ └── 否 → S 段可扩充?
│ ├── 是 → 检查相邻空闲区 → 扩充
│ └── 否 → 地址错
└── 否 → 缺段中断 → OS 处理
├── 有足够连续空闲区 → 装入 S 段
└── 无 → 移动或调出其他段 → 装入 S 段
3.4.3 段页式存储管理
基本思想
- 段式 + 页式的结合
- 每一段不必占据连续存储空间,可存放在不连续的页框中
- 可扩充为段页式虚拟存储管理(装入部分段,或段中部分页面)
段表和页表
- 段表:每段一个表项,包含页表长度和页表始址
- 页表:每段有自己的页表,记录该段各页的页框号
1
逻辑地址:| 段号 | 页号 | 单元号 |
地址转换
- 按段号查段表 → 获得该段的页表始址和页表长度
- 按页号查该段的页表 → 获得页框号
- 页框号 + 单元号 → 物理地址
- 配合快表加速:快表项包含
段号 | 页号 | 块号
段页式虚拟存储管理的地址转换
1
2
3
4
5
6
7
8
9
查快表(段号+页号)
├── 命中 → 形成绝对地址
└── 未命中 → 查段表
├── 无该段页表 → 缺段中断
└── 有 → 页号超出页表长?
├── 是 → 越界中断
└── 否 → 该页在主存?
├── 是 → 形成绝对地址
└── 否 → 缺页中断
分段与分页的比较
| 比较维度 | 分页 | 分段 |
|---|---|---|
| 本质 | 信息的物理单位 | 信息的逻辑单位 |
| 与源程序关系 | 与逻辑结构无关 | 由源程序逻辑结构决定 |
| 用户可见性 | 不可见 | 可见 |
| 大小 | 系统确定,固定 | 用户指定,可变 |
| 起始地址 | 页大小整倍数 | 任意地址 |
| 连接装配后地址 | 变为一维结构 | 保持二维结构 |
课堂笔记
1. 地址与地址空间

1.1 为什么需要区分”逻辑地址”和”物理地址”?
问题动机:程序员写代码时,并不知道自己的程序最终会被加载到内存的哪个位置。如果程序里写死了物理地址(比如 MOV AX, [0x10000]),那这个程序只能在特定机器上特定内存布局下运行——这显然不可接受。
解决方案:引入两层地址空间的抽象。
| 地址类型 | 别名 | 定义 | 谁使用 |
|---|---|---|---|
| 逻辑地址 | 相对地址、虚地址 | 程序编译后的地址,从 0 开始编号 | 程序员 / 编译器 |
| 物理地址 | 绝对地址 | CPU 总线上实际寻址的地址 | 硬件 |
关键洞察:逻辑地址空间是程序视角的”假想”内存;物理地址空间是实际存在的内存。存储管理的核心任务之一,就是在运行时维护这两者之间的映射。
1.2 逻辑地址的两种结构
一维逻辑地址
1
[ 单一线性地址 ]
程序看到的是一块连续的、从 0 开始的地址空间。页式存储管理使用此结构。
二维逻辑地址(段式)
1
[ 段号 : 段内偏移 ]
程序由若干”段”(代码段、数据段、堆栈段……)组成,每段从 0 独立编号。段式存储管理使用此结构。
为什么要有二维地址? 因为程序在逻辑上本来就是分块的——代码是代码、数据是数据、栈是栈。二维地址空间让这种逻辑结构直接映射到地址结构,方便保护、共享和动态扩充各个段。
1.3 存储管理的四种基本模式
不同地址结构 × 不同内存分配方式,形成四种正交组合:
| 模式 | 逻辑地址 | 主存分配方式 | 是否连续 |
|---|---|---|---|
| 单连续存储管理 | 一维 | 一个固定或可变分区 | ✅ 连续 |
| 页式存储管理 | 一维 | 多个等大页框 | ❌ 不要求连续 |
| 段式存储管理 | 二维 | 多个可变大小分区 | 段内连续,段间不要求 |
| 段页式存储管理 | 二维 | 多个等大页框 | ❌ 不要求连续 |
直觉:四种方式都可以支持虚拟化(按需调入)和共享(多进程共用同一段内存),区别仅在于地址组织方式和内存分配粒度。
2. 存储管理的核心功能
2.1 地址转换(重定位)
将逻辑地址转换为物理地址,是存储管理最基础的任务。
静态重定位
- 时机:程序装入内存时,由装入程序一次性完成
- 方式:扫描程序中所有地址引用,加上分配到的基址
- 缺点:
- 程序必须占用连续且固定的内存区域,无法移动
- 不支持虚拟存储(无法按需调入)
- 适用于早期单用户 OS(如 DOS)
动态重定位
- 时机:CPU 执行每条指令时实时完成
- 方式:每次内存访问都通过硬件地址转换机构将逻辑地址→物理地址
- 优点:
- 程序可以在内存中移动(只需更新基址寄存器)
- 支持虚拟存储
- 必要条件:需要硬件支撑(基址寄存器、MMU 等)
工程现实:现代操作系统全部使用动态重定位。静态重定位是历史遗留,理解它有助于理解为什么需要硬件 MMU。
2.2 内存空间的分配与回收
- 分配:进程创建时,OS 从空闲内存中划分出一块(或多块)分配给进程,并用数据结构记录分配情况
- 回收:进程终止或主动释放时,OS 将该内存标记为空闲,并尝试与相邻空闲区合并
分配和回收的效率直接影响系统吞吐量,不同管理模式有不同的数据结构和算法。
2.3 内存共享
两种含义,需要区分:
- 共享物理资源(宏观):多道程序同时驻留内存,共用同一块 DRAM——这是多道程序设计的基础
- 共享内存区域(微观):多个进程的逻辑地址空间映射到同一块物理内存——用于进程通信或代码共用(如共享库)
2.4 存储保护
目标:防止进程 A 访问进程 B 的内存,防止用户程序访问内核内存。
实现机制(软硬件协同):
1
2
3
4
5
6
7
CPU 发出内存访问请求
↓
硬件检查:访问地址是否在允许范围内?
访问类型是否符合权限(读/写/执行)?
↓
合法 → 正常访问
非法 → 产生"地址保护异常"→ 陷入 OS → OS 处理(通常终止进程)
硬件负责实时检查(每次访问都要),OS 负责建立和维护权限表、处理异常。
2.5 内存扩充
问题:物理内存有限,但用户希望运行比内存更大的程序,或同时运行更多程序。
| 技术 | 核心思想 | 粒度 | 透明性 |
|---|---|---|---|
| 对换技术(Swapping) | 将整个进程调出到磁盘 | 进程级 | 对进程透明,进程必须等待 |
| 虚拟存储技术(Paging/Segmentation) | 只调入进程的当前需要部分 | 页/段级 | 完全透明,进程感知不到 |
虚拟存储技术是现代 OS 的标准方案,对换技术更多用于内存极端紧张时将整个进程换出。
3. 硬件基础
3.1 存储器层次结构
存储管理的设计根植于存储器的物理特性:越靠近 CPU,速度越快、容量越小、成本越高。
1
2
3
4
5
6
7
8
9
10
11
12
13
┌─────────────────────────────────────────────────────────────┐
│ 存储器层次(从快到慢) │
│ │
│ L0 寄存器 ← ~1 cycle, 字节级, CPU 内部 │
│ L1 L1 Cache ← ~4 cycles, 32-256 KB, 片上 │
│ L2 L2 Cache ← ~10 cycles, 256KB-8MB │
│ L3 L3 Cache ← ~40 cycles, 多核共享 │
│ L4 主存 (DRAM) ← ~200 ns, GB 级 │
│ L5 SSD ← ~100 µs, TB 级 │
│ L6 HDD ← ~10 ms, TB 级 │
│ L7 远程存储 ← ~100 ms+, 无限 │
└─────────────────────────────────────────────────────────────┘
↑ 快、小、贵 慢、大、便宜 ↑
关键比率:主存比 L1 Cache 慢约 50 倍,磁盘比主存慢约 50,000 倍。这一比率直接决定了虚拟存储中”缺页”的巨大代价。
3.2 Cache 工作原理
Cache 是 CPU 和主存之间的缓冲,利用程序的局部性原理来减少访问主存的次数。
Cache 的组成:
- 高速存储体:SRAM,存储数据副本
- 联想存储器(CAM, Content Addressable Memory):按内容查找,而非按地址——这是 Cache 和 TLB 的关键硬件
- 地址转换部件:判断命中/未命中,未命中时从主存加载
- 替换逻辑:Cache 满时决定淘汰哪块数据(LRU 等)
联想存储器的直觉:普通内存是”给我地址,返回内容”;联想存储器是”给我内容的一部分(如页号),返回匹配的完整条目(如页框号)”。这种查找方式在硬件上并行比对所有条目,极快,但成本高、容量小。
3.3 地址转换的硬件支撑
基址寄存器 + 限长寄存器(最简单的硬件支撑,用于单连续分区和固定分区):
1
2
3
4
5
逻辑地址: 0 ... LA ... LIMIT-1
↓
LA < LIMIT ?
├── 是 → 物理地址 = BASE + LA
└── 否 → 越界中断(陷入 OS)
更复杂的管理模式(页式、段式)需要更复杂的硬件,后续章节详述。
工程原则:动态重定位、存储保护、虚拟存储,三者都必须有硬件支撑。纯软件实现在效率上不可接受——每条内存访问指令都需要地址转换,必须在一个时钟周期内完成。
4. 单连续分区存储管理
4.1 单用户连续分区
适用场景:单用户单任务操作系统(如早期 DOS)
结构:
1
2
3
4
5
6
┌──────────────┐ ← 主存起始
│ 系统区 │ OS 驻留
├──────────────┤ ← 栅栏寄存器(FENCE)
│ 用户区 │ 单个用户程序
│ │
└──────────────┘ ← 主存末尾
特点:
- 栅栏寄存器保护 OS,防止用户程序越界
- 通常使用静态重定位,实现简单
- 内存利用率极低——只有一个用户程序
4.2 固定分区
思想:将内存预先划分为若干大小固定的分区,每个分区运行一个进程。
主存分配表结构:
| 分区号 | 起始地址 | 长度 | 占用标志 |
|---|---|---|---|
| 0 | 0x10000 | 64KB | 空闲 |
| 1 | 0x20000 | 128KB | 进程 A |
| 2 | 0x40000 | 64KB | 进程 B |
地址转换:
1
2
物理地址 = 下限寄存器(B) + 逻辑地址
若 逻辑地址 > 上限寄存器 → 越界中断
局限性:
- 内部碎片(Internal Fragmentation)不可避免:分区大小固定,进程实际需求小于分区大小时,多余的空间浪费
- 分区数量固定:限制了系统并发度
- 大进程无法运行:无法跨分区分配
5. 可变分区存储管理
5.1 核心思想
改进:不预先划分分区,而是在进程创建时,按其实际需求动态分配恰好合适的内存块。
关键数据结构:使用链表维护内存状态
1
2
已分配区表:[起址 | 长度 | 所属进程]
未分配区表:[起址 | 长度]
优点:消除内部碎片 代价:产生外部碎片(后文详述)
5.2 四种分配算法
最先适应(First Fit)
1
从链表头开始扫描 → 找到第一个 "长度 ≥ 请求大小" 的空闲区 → 分割并分配
- 优点:简单、快速
- 缺点:倾向于在低地址区产生碎片,高地址区保留大块(这反而有利于大请求)
- 工程实践中最常用
邻近适应(Next Fit)
1
从上次分配位置开始扫描 → 找到第一个够大的空闲区
- 优点:避免每次都从头扫描,分配更均匀
- 缺点:大块空闲区在整个地址空间均匀消耗,无法为大请求保留
最优适应(Best Fit)
1
扫描全部空闲区 → 找长度刚好够用、最小的那个空闲区
- 直觉:尽量减少”浪费”的空间
- 反直觉的缺点:最容易产生外部碎片——每次都切割出最小剩余,剩余的碎片往往太小,永远无法被利用
最坏适应(Worst Fit)
1
扫描全部空闲区 → 找最大的空闲区
- 直觉:每次从最大块分割,剩余仍然较大,可被后续请求使用
- 缺点:大块空闲区被快速消耗,当有真正需要大块内存的请求时,反而找不到
算法对比总结:
| 算法 | 查找速度 | 对小请求 | 对大请求 | 碎片倾向 |
|---|---|---|---|---|
| First Fit | O(n) 平均较快 | 好 | 好(高地址保留大块) | 低地址碎片化 |
| Next Fit | O(n) 均匀 | 好 | 差 | 全局碎片化 |
| Best Fit | O(n) 较慢 | 好 | 差 | 最多碎片 |
| Worst Fit | O(n) 较慢 | 差 | 差 | 消耗大块 |
5.3 内存回收与合并
回收进程 X 的内存时,需要检查与相邻空闲区的合并(否则碎片越来越多):
1
2
3
4
情况一:上邻空闲,下邻已分配 → 合并上邻
情况二:上邻已分配,下邻空闲 → 合并下邻
情况三:上下均空闲 → 三区合并为一
情况四:上下均已分配 → 独立新空闲区
5.4 外部碎片问题
外部碎片(External Fragmentation):内存中存在许多分散的小空闲区,总量上够,但没有哪一块连续的空间足够大。
关键认识:任何适配算法都无法从根本上避免外部碎片。这是可变分区方案的固有缺陷。
缓解方法:移动技术(内存紧缩,Compaction)
1
将所有已分配区移动到内存的一端 → 另一端形成大的连续空闲区
- 前提:必须支持动态重定位(移动后修改基址寄存器即可)
- 代价:移动过程中程序必须暂停,且移动操作本身耗时
- 这是一个典型的工程妥协:用 CPU 时间换连续内存空间
6. 页式存储管理
6.1 为什么需要分页?
可变分区的根本问题:要求进程占用连续物理内存。这导致:
- 外部碎片难以消除
- 大进程找不到足够大的连续空间
突破口:打破”必须连续”的假设。
核心思想:
- 将物理内存切成等大的页框(Frame / Page Frame)
- 将逻辑地址空间切成等大的页(Page)
- 页和页框大小相同(通常为 4KB)
- 进程的每个逻辑页,可以映射到任意物理页框
- 用页表(Page Table)记录这种映射关系
1
2
3
4
5
6
7
8
9
10
逻辑地址空间(进程视角) 物理地址空间(实际内存)
┌──────────┐ ┌──────────┐
│ Page 0 │ ──────────────→ │ Frame 3 │
├──────────┤ ├──────────┤
│ Page 1 │ ──────────────→ │ Frame 7 │
├──────────┤ ├──────────┤
│ Page 2 │ ──────────────→ │ Frame 1 │
└──────────┘ ├──────────┤
│ Frame 2 │(其他进程)
└──────────┘
进程”感觉”自己在连续内存中,实际上分散在各处。
6.2 地址转换机制
逻辑地址结构:
1
2
3
┌─────────────┬──────────────────┐
│ 页号 (p) │ 页内偏移 (d) │
└─────────────┴──────────────────┘
物理地址结构:
1
2
3
┌──────────────┬──────────────────┐
│ 页框号 (f) │ 页内偏移 (d) │
└──────────────┴──────────────────┘
转换过程:
1
2
3
4
5
给定逻辑地址 LA:
p = LA / 页大小 (取整)
d = LA % 页大小 (取余)
f = 页表[p] (查页表)
物理地址 = f × 页大小 + d
具体示例(页大小 = 1024 字节):
1
2
3
4
5
6
7
8
9
10
11
指令:MOV [2100], [3100]
地址 2100:
p = 2100 / 1024 = 2(余 52)
查页表:Page 2 → Frame 6
物理地址 = 6 × 1024 + 52 = 6196
地址 3100:
p = 3100 / 1024 = 3(余 28)
查页表:Page 3 → Frame 8
物理地址 = 8 × 1024 + 28 = 8220
6.3 内存分配:位示图
问题:怎么高效地知道哪些页框是空闲的?
解决:位示图(Bitmap)
1
2
3
4
5
6
7
位示图:一个 bit 数组,第 i 位表示第 i 个页框的状态
0 = 空闲
1 = 已分配
例(64个页框):
11100111 10001111 00110000 01111110 ...
↑占用 ↑空闲 ↑占用
分配 n 个页框:扫描位示图找 n 个为 0 的位,置 1。 回收:将对应位清 0。
6.4 TLB(快表):解决地址转换的性能问题
问题:页表存放在主存中。每次内存访问需要:
- 访问主存读取页表(得到页框号)
- 再访问主存读写实际数据
→ 每次内存访问变成了两次访存,速度降低一半!
解决方案:TLB(Translation Lookaside Buffer,快表)
TLB 是一块联想存储器(CAM),存放最近使用的页表项,支持按内容并行查找。
1
2
3
4
┌─────────────────────────────────────────────┐
│ TLB │
│ 页号 → 页框号 (全相联,~16-1024 条目) │
└─────────────────────────────────────────────┘
带 TLB 的地址转换流程:
1
2
3
4
5
6
7
8
9
10
11
给定逻辑地址
↓
查 TLB(极快,~1-4 cycles)
├── TLB 命中 → 直接得到页框号 → 形成物理地址 → 访问数据(1 次主存访问)
└── TLB 未命中
↓
查主存页表(1 次主存访问)
↓
得到页框号 → 形成物理地址 → 访问数据(1 次主存访问)
↓
将该页表项写入 TLB(淘汰旧条目)
性能计算示例:
1
2
3
4
5
6
7
8
9
10
11
设:主存访问时间 = 200ns
TLB 访问时间 = 40ns
TLB 命中率 = 90%
命中时:TLB(40) + 主存(200) = 240ns
未命中:TLB(40) + 主存页表(200) + 主存数据(200) = 440ns
平均时间 = 240 × 90% + 440 × 10% = 216 + 44 = 260ns
对比无 TLB:200 + 200 = 400ns
性能提升:(400 - 260) / 400 = 35%
工程现实:现代 CPU 的 TLB 命中率通常在 99% 以上(得益于程序的空间局部性),实际性能开销极小。TLB miss 的处理方式有软件(MIPS)和硬件(x86)两种,各有权衡。
6.5 页的共享
数据共享:允许不同进程用不同页号指向同一个物理页框。
1
2
进程 A:Page 3 → Frame 10(共享数据)
进程 B:Page 7 → Frame 10(同一物理块)
代码共享:共享可执行代码(如共享库)时,要求不同进程必须使用相同页号。
为什么代码共享要求相同页号?
考虑共享代码页中的跳转指令:
1
地址 100(页内):JMP 200(页内地址)
这条指令的目标地址 200 是页内偏移,与页号无关。 但如果代码中有跨页跳转(JMP 2048),则依赖于这段代码所在的页号。 不同进程若使用不同页号,跨页跳转目标就会不同——导致错误。
解决方案:使用位置无关代码(Position Independent Code, PIC)
1
gcc -fpic -shared -o libfoo.so foo.c
PIC 使用相对偏移代替绝对地址,无论加载到哪个地址都能正确执行。这是共享库(.so / .dll)的基础。
7. 页式虚拟存储管理
7.1 程序局部性原理
虚拟存储的理论基础,由 Denning(1968)系统阐述。
时间局部性(Temporal Locality): 最近被访问的内存位置,在近期极有可能再次被访问。 → 来源:循环、过程调用、变量的重复使用
空间局部性(Spatial Locality): 某个内存位置被访问后,其附近的内存位置很快也会被访问。 → 来源:顺序执行的指令、数组的顺序遍历
局部性的实践意义:
1
2
3
4
5
6
7
8
9
10
11
12
13
// 反例:破坏空间局部性(按列访问行优先存储的二维数组)
// 每次访问跨越 128 个元素,几乎每次都缺页
for(j=0; j<128; j++) // 外层:列
for(i=0; i<128; i++) // 内层:行
A[i][j] = 0;
// 缺页次数 ≈ 128 × 128 = 16384 次
// 正例:遵循空间局部性(按行访问)
// 每行装入一次后连续访问 128 个元素
for(i=0; i<128; i++) // 外层:行
for(j=0; j<128; j++) // 内层:列
A[i][j] = 0;
// 缺页次数 ≈ 128 次
同样的程序,缺页次数相差 128 倍。 理解局部性是写出高性能程序的基础。
7.2 虚拟存储的基本机制
目标:让进程”感觉”拥有比物理内存更大的地址空间。
实现:
1
2
3
4
5
6
7
辅存(磁盘) 主存
┌────────────┐ ┌────────────┐
│ 进程全部 │ │ 进程当前 │
│ 页面 │ ←→ OS调度 │ 活跃页面 │
│(虚拟地址 │ │(物理页框)│
│ 空间) │ │ │
└────────────┘ └────────────┘
- 进程的所有页面存放于辅存(磁盘上的虚拟地址空间)
- 执行时,只将当前需要的页装入主存
- 访问不在主存的页 → 产生缺页中断(Page Fault) → OS 将该页从磁盘调入主存
- 主存满时,选择一个暂时不用的页调出到磁盘(页面置换)
请求页式(Demand Paging):最常用的实现方式——首次只装入进程第一页,其余按需调入。
7.3 扩充的页表项
虚拟存储需要在页表中记录更多信息:
1
2
3
4
┌────────┬──────────┬──────────┬────────┬────────┬──────────┐
│驻留位 │ 页框号 │ 辅存地址 │ 修改位 │ 引用位 │ 保护位 │
│(Valid) │ (Frame) │(Disk Addr)│(Dirty) │(Access)│(R/W/X) │
└────────┴──────────┴──────────┴────────┴────────┴──────────┘
| 位 | 含义 | 作用 |
|---|---|---|
| 驻留位 | 该页是否在主存中 | 地址转换时检查,为 0 则触发缺页中断 |
| 修改位(Dirty bit) | 该页被写入后是否已修改 | 页面替换时,脏页需写回磁盘;干净页可直接丢弃 |
| 引用位(Access bit) | 最近是否被访问 | LRU/CLOCK 等置换算法使用 |
| 保护位 | 读/写/执行权限 | 存储保护,违反则产生保护中断 |
| 辅存地址 | 该页在磁盘上的位置 | 缺页时从磁盘加载 |
7.4 完整地址转换流程(含缺页处理)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
CPU 发出逻辑地址
↓
查 TLB(快表)
├── 命中 → 形成物理地址 → 访问数据 ✓
└── 未命中 → 查主存页表
├── 驻留位 = 1(页在主存)
│ → 形成物理地址 → 更新 TLB → 访问数据 ✓
└── 驻留位 = 0(页不在主存)→ 缺页中断
↓
OS 的缺页中断处理程序
↓
主存有空闲页框?
├── 有 → 从磁盘读入缺失页
│ → 更新页表(驻留位=1,填入页框号)
│ → 更新 TLB
│ → 重新执行引发中断的指令 ✓
└── 无 → 页面置换
↓
选择被替换页(各种算法)
↓
被替换页的修改位 = 1?
├── 是(脏页)→ 将该页写回磁盘 → 清空页框
└── 否(干净)→ 直接清空页框
↓
读入缺失页 → 更新页表和 TLB → 重执指令 ✓
关键细节:缺页中断处理完毕后,必须重新执行引发中断的那条指令(而非继续执行下一条),因为那条指令没有完成。
7.5 抖动(Thrashing)
定义:进程大部分时间在等待页面换入换出,CPU 实际执行指令的时间极少。
产生原因:
- 分配给进程的页框数太少,工作集(活跃页面集合)放不下
- 不断缺页→置换→再缺页,形成恶性循环
检测方式:缺页中断率 f = 缺页次数 / 总访问次数
1
2
f 过高 → 增加分配给该进程的页框数
f 过低 → 可以减少页框数,让更多进程驻留
8. 页面调度算法
8.1 评估指标
缺页中断率 f:
1
2
3
f = F / A
F = 缺页(不成功访问)次数
A = 总访问次数
f 越低 → 性能越好
8.2 五种核心算法
OPT(最佳算法 / Belady 算法)
策略:替换未来最长时间内不会被访问的页。
性质:
- 缺页率最低,是理论最优下界
- 无法实现:需要预知未来的访问序列
- 用途:评估其他算法的性能上限
示例(3 个页框,引用串 7 0 1 2 0 3 0 4 2 3 0 3 2 1 2 0 1 7 0 1):
OPT 在替换时选择序列中下次出现最晚的页,达到理论最优缺页次数。
FIFO(先进先出)
策略:替换在主存中驻留时间最长的页。
实现:维护一个队列,最早入队的页最先被替换。
直觉:假设最老的页最不常用——这个假设往往不成立。
Belady 异常(FIFO 的特有反常现象):
1
2
3
4
引用串:1 2 3 4 1 2 5 1 2 3 4 5
3 个页框:缺页 9 次
4 个页框:缺页 10 次 ← 页框增加,缺页反而增多!
这违反直觉,原因是 FIFO 不考虑页面的实际使用频率,纯粹按时间排队。
工程意义:Belady 异常表明,”多给内存一定更好”并不总是成立——在 FIFO 策略下可能适得其反。这也是 FIFO 在实际操作系统中很少单独使用的原因。
LRU(最近最少使用)
策略:替换最长时间未被访问的页。
直觉:利用时间局部性——最久未用的页,未来也最不可能被用。
理论性质:不存在 Belady 异常;是对 OPT 的合理近似。
严格实现的代价:需要维护一个精确的访问时间戳或 LRU 栈,每次访问都要更新——对硬件要求高,实现复杂。
近似实现(OS 实际常用):
1
2
3
4
5
6
每页设一个引用位(Reference Bit)
定时中断(如每 10ms):将所有引用位清 0
页面被访问时:引用位置 1
替换时:选择引用位为 0 的页(最近一个周期未被访问的页)
若全为 1,则选最旧的(退化为 FIFO)
LFU(最不常用)
策略:替换访问次数最少的页。
实现:
1
2
3
4
每页维护一个计数器
每次访问:计数器 + 1
定时中断:所有计数器清 0(只统计最近一段时间)
替换:选计数器值最小的页
局限:如果某页曾被大量访问但现在不再需要,其高计数值会保护它不被替换。定时清 0 是缓解手段。
CLOCK(时钟算法)
策略:LRU 近似,采用环形缓冲区结构,兼顾效率和近似精度。
实现:
1
2
3
4
5
6
7
将所有页框排成一个环(时钟),维护一个指针
页面调入时:引用位 = 1
需要置换时,从指针当前位置开始扫描:
引用位 = 1 → 清 0,指针前进(给它一次"第二次机会")
引用位 = 0 → 替换该页,指针前进到下一位置
直觉:指针像时钟表针一样旋转,扫过去时给每个页面一次”第二次机会”。被访问过的页(引用位=1)得以保留;一直未被访问(引用位保持0)的页被替换。
工程优势:
- 实现简单,开销低
- 比纯 FIFO 更优(考虑了引用情况)
- Linux、Windows 等主流 OS 均使用 CLOCK 或其变种
8.3 算法性能对比
1
2
3
4
5
缺页率(从低到高,即从好到差):
OPT < LRU ≈ LFU < CLOCK < FIFO
理论最优 实用最优 工程权衡 最差
注意:这是一般性排序,在特定访问模式下可能有例外(如 CLOCK 某些情况下优于 LFU)。
8.4 工作集模型(Denning, 1968)
工作集 W(t, Δ):在时刻 t,进程在过去 Δ 时间窗口内所访问的页面集合。
1
2
3
4
5
6
7
时间轴
──────────────────────────────────→
t-Δ t
├────────────┤
│ 工作集窗口 │
└────────────┘
工作集 = 这段时间内访问过的所有页面
工作集替换策略:
- 在时刻 t,检查每个页面上次访问时间
- 最后一次访问在 (t-Δ, t) 之外的页 → 不在工作集 → 可以移出
- 驻留集大小随工作集大小动态调整
缺页频率策略(Page Fault Frequency, PFF):
1
2
3
缺页率 > 上界 U → 分配更多页框
缺页率 < 下界 L → 减少页框,回收给其他进程
目标:驻留集大小 ≈ 工作集大小
这是实际 OS 进行动态内存管理的重要策略。
9. 段式存储管理
9.1 为什么需要分段?
分页的局限:页是物理单位,与程序的逻辑结构无关。
- 一个函数可能跨越多个页
- 无法对代码段单独设置”只读”而对数据段设置”读写”(粒度不合适)
- 不同进程共享同一个函数时,很难精确共享
分段的动机:按程序的逻辑结构划分地址空间。
一个典型程序自然分为:
1
2
3
4
5
6
7
8
9
┌──────────────┐
│ 主程序段 │ → 可执行,不可写
├──────────────┤
│ 子程序段 │ → 可执行,不可写
├──────────────┤
│ 数据段 │ → 可读写
├──────────────┤
│ 堆栈段 │ → 可读写
└──────────────┘
每段从 0 独立编址,段间无连续性要求,各段可独立增长、独立保护、独立共享。
9.2 基本机制
逻辑地址:段号 S : 段内偏移 d
段表:每个进程一个,每段一个表项
1
2
3
┌──────┬─────────┬─────────┬──────────┬──────────┐
│ 段号 │ 段始址 │ 段长 │ 存取权限 │ 其他标志 │
└──────┴─────────┴─────────┴──────────┴──────────┘
地址转换:
1
2
3
4
5
6
给定逻辑地址 (S, d):
1. 查段表,获得段 S 的始址 base_S 和段长 limit_S
2. d < limit_S?
├── 是 → 物理地址 = base_S + d
└── 否 → 越界中断
3. 检查存取权限(读/写/执行)→ 不符合则保护中断
具体示例:
1
2
逻辑地址 (2, 100),段 2 的基址 = 8192(8K)
物理地址 = 8192 + 100 = 8292
9.3 段的共享
不同进程的段表项指向同一物理内存区域(相同的段始址):
1
2
3
进程 A:段表[1].base = 0x50000 ─┐
├→ 同一物理段
进程 B:段表[3].base = 0x50000 ─┘
共享段通常标记为只读(或只执行),防止一个进程的写操作破坏另一个进程的视图。
9.4 段式虚拟存储
与页式虚拟存储类似,但以段为调度单位:
- 段不在内存时产生缺段中断
- OS 从磁盘将整段调入(需要连续内存区域)
- 可能需要进行内存紧缩
缺段中断处理:
1
2
3
4
5
访问 (S, d)
→ S 段不在内存 → 缺段中断
→ OS 检查是否有足够连续空间
├── 有 → 将 S 段从磁盘读入 → 更新段表 → 重执指令
└── 无 → 将某些段调出(选择策略)→ 可能需要移动 → 再调入
段式虚拟存储的问题:段大小可变,调入/调出代价不均匀;仍然可能有外部碎片。这也是段页式存储管理出现的原因。
10. 段页式存储管理
10.1 结合两者的优点
| 分页 | 分段 | |
|---|---|---|
| 优点 | 无外部碎片,内存利用率高 | 符合逻辑结构,便于保护和共享 |
| 缺点 | 不反映逻辑结构 | 外部碎片,需要连续内存 |
段页式:用分段组织逻辑结构,用分页管理物理内存。
- 程序按段划分(逻辑层)
- 每段再按页划分(物理层)
- 各段不要求连续,各页也不要求连续
10.2 地址结构与转换
逻辑地址:段号 S : 页号 P : 页内偏移 d
1
2
3
4
地址转换需要两次查表:
1. 按段号 S 查段表 → 获得该段的页表基址和长度
2. 按页号 P 查该段的页表 → 获得页框号 F
3. 物理地址 = F × 页大小 + d
配合 TLB:TLB 中存放 (段号, 页号) → 页框号 的映射,加速最常用的地址转换。
10.3 段页式虚拟存储的地址转换流程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
给定逻辑地址 (S, P, d)
↓
查 TLB(段号+页号)
├── 命中 → 直接得到页框号 → 物理地址 ✓
└── 未命中
↓
查段表(按段号 S)
├── 无该段的页表 → 缺段中断 → OS 建立该段页表
└── 有页表
↓
页号 P 超出页表长度?
├── 是 → 越界中断
└── 否 → 查页表(按页号 P)
├── 驻留位 = 1 → 得到页框号 → 更新 TLB → 物理地址 ✓
└── 驻留位 = 0 → 缺页中断 → OS 调入该页 → 重执
11. 高级话题:伙伴系统与反置页表
11.1 伙伴系统(Buddy System)
适用场景:操作系统内核的内存分配(页框级别)
动机:可变分区管理的合并/分割操作效率低;固定分区浪费内存。伙伴系统是两者的折中。
核心规则(Knuth, 1973):
- 内存块大小只能是 2 的幂次(2^0, 2^1, 2^2, … )
- 大小为 2^i 的块,可以分裂为两个大小为 2^(i-1) 的伙伴
- 两个伙伴可以合并回 2^i 的块
- 两个块是伙伴,当且仅当它们大小相同且物理上相邻,且由同一个 2^i 块分裂而来
1
2
3
4
5
6
分配 3KB 的请求(不妨设最小块 4KB):
找到 2^2 = 4KB 的空闲块 → 分配
分配 5KB 的请求:
找 4KB 不够 → 找 2^3 = 8KB 的块 → 分裂为两个 4KB → 再分裂为 2KB + 4KB...
(等等,5KB 需要找到 2^3 = 8KB 的块来分配,内部碎片 3KB)
内部碎片:请求大小不是 2 的幂次时存在,最坏情况约 50%。这是伙伴系统的主要缺点。
Linux 中的实现:
1
2
3
4
free_area[11]:分别管理 2^0 到 2^10 个页框的空闲块链表
分配:找到最小的满足需求的 2^i → 若无,找更大的 2^(i+1) 并分裂
回收:将页框归还到对应链表 → 检查伙伴是否也空闲 → 若是,合并 → 递归向上合并
11.2 Slab 分配器
问题:伙伴系统以页框(4KB)为最小单位,但内核中大量对象远小于 4KB(如 task_struct ≈ 1.7KB,inode ≈ 0.5KB)。
朴素方案:每次分配小对象都向伙伴系统申请一页,浪费严重。
Slab 分配器思想(源自 SunOS):为每种常用小对象建立专属缓存池。
1
2
3
4
5
6
kmem_cache(对象缓存)
├── slab(一组连续页框,切割成等大的对象槽)
│ ├── 满 slab(所有槽都被占用)
│ ├── 半满 slab(部分槽空闲)
│ └── 空 slab(全部槽空闲,可回收给伙伴系统)
└── 每个 slab 存放相同类型的对象
优势:
- 同类对象在空间上局部化 → 更好的 Cache 利用率
- 对象频繁分配/释放时,不用反复初始化(可在对象池中保留已初始化的对象)
- 内部碎片仅发生在 slab 内部,远小于每次向伙伴系统申请整页
通用 Slab(kmalloc/kfree 使用):
1
2
13 种通用缓存:32B, 64B, 128B, 256B, 512B, 1KB, 2KB, 4KB, 8KB, 16KB, 32KB, 64KB, 128KB
(2 的幂次增长,最坏内部碎片率约 50%)
11.3 多级页表
问题:32 位地址空间,4KB 页面 → 2^20 个页表项 → 单进程页表占 4MB 连续内存。100 个进程 → 400MB 只用来存页表,不可接受。
观察:大多数进程只使用地址空间的一小部分(代码+数据+栈),中间大片地址空间是空的。但平坦页表必须为每个可能的页号都预留空间。
解决:二级页表
1
2
3
4
逻辑地址:| 页目录号(10 bits) | 页表页号(10 bits) | 页内偏移(12 bits) |
一级结构(页目录):2^10 = 1024 个表项,每项指向一个页表页
二级结构(页表页):每个页表页有 2^10 = 1024 个表项,指向物理页框
关键优势:
- 页目录始终在内存(只有 1 个,4KB)
- 页表页按需创建:进程没用到的地址空间,对应页表页根本不存在
- 空地址范围 = 空页表页 = 0 内存开销
代价:两次页表查找(时间换空间)。三级、四级页表(x86-64 用 4 级)进一步扩展地址空间,但每次地址转换需要更多次内存访问——这就是 TLB 如此关键的原因。
11.4 反置页表(Inverted Page Table)
问题来源:传统页表大小正比于虚拟地址空间大小,64 位虚拟地址空间下,即使多级页表也面临挑战。
根本转变:不按虚拟页号建表,而是按物理页框建表。
1
2
传统页表:虚拟页号 → 页框号(大小 ∝ 虚拟空间)
反置页表:页框号 → (进程ID, 虚拟页号)(大小 ∝ 物理内存)
反置页表结构:
1
2
3
4
IPT[i](第 i 个页框的表项):
┌────────────┬──────────┬──────────┬──────────────┐
│ 进程标识 │ 虚拟页号 │ 特征位 │ 哈希链指针 │
└────────────┴──────────┴──────────┴──────────────┘
地址转换(较慢,需要哈希):
1
2
3
4
5
6
给定 (进程ID, 虚拟页号)
→ 哈希函数 → 哈希值 h
→ 查 IPT[h],沿哈希链搜索
→ 找到匹配的 (进程ID, 虚拟页号) → 该表项的**索引**即为页框号
→ 物理地址 = 页框号 × 页大小 + 偏移
→ 未找到 → 缺页中断
优点:整个系统只有一张反置页表,大小固定 = 物理页框数,不随虚拟空间增长。
缺点:
- 地址转换需要哈希查找,比传统页表慢
- 共享内存的实现复杂(同一物理帧对应多个虚拟页)
- 需要结合 TLB 补偿性能
应用:PowerPC、UltraSPARC、IA-64(安腾)均使用此方案。
12. 分页与分段的本质对比
这是一道经典考题,但更重要的是理解背后的设计哲学。
| 维度 | 分页 | 分段 |
|---|---|---|
| 本质 | 信息的物理单位,便于 OS 管理 | 信息的逻辑单位,反映程序结构 |
| 目的 | 实现虚拟存储,提高内存利用率 | 方便编程、信息共享、保护、动态增长 |
| 与源程序关系 | 与逻辑结构无关,机械地切割 | 由程序员/编译器定义,反映逻辑结构 |
| 用户可见性 | 对用户透明(程序员感知不到分页) | 对用户可见(程序员操纵段号) |
| 大小 | 系统固定(通常 4KB) | 用户/编译器指定,可变长 |
| 地址结构 | 一维(页号+偏移,但用户只见线性地址) | 二维(段号+段内偏移,用户显式使用) |
| 碎片 | 内部碎片(最后一页可能不满) | 外部碎片(段间可能有空隙) |
| 共享单位 | 整数个页(可能切割逻辑单元) | 整个段(与逻辑单元对齐) |
| 保护粒度 | 页(可能一页同时含代码和数据) | 段(代码段只读,数据段读写) |
一句话总结:
分页是 OS 的手段(解决物理内存管理问题),分段是程序员的工具(组织程序逻辑结构)。 段页式存储管理将两者结合:段满足程序员的逻辑需求,页解决物理内存的管理问题。
附录:关键概念速查
碎片类型
| 类型 | 产生场景 | 消除方法 |
|---|---|---|
| 内部碎片 | 固定分区 / 分页(最后一页不满) | 减小分区/页大小(权衡) |
| 外部碎片 | 可变分区 / 分段 | 内存紧缩(移动技术)或改用分页 |
局部性与缺页率的关系
1
2
3
4
5
6
7
8
9
10
11
12
程序局部性好
→ 工作集小
→ 需要的页框少
→ 缺页率低
→ 系统性能好
反之:
程序随机访问(如哈希表、大型矩阵列访问)
→ 工作集 ≈ 全部页面
→ 需要大量页框
→ 缺页频繁
→ 可能发生抖动
各算法是否有 Belady 异常
| 算法 | 是否有 Belady 异常 |
|---|---|
| OPT | 否 |
| LRU | 否 |
| LFU | 否 |
| CLOCK | 否 |
| FIFO | 是 |
FIFO 有 Belady 异常的根本原因:它不是栈算法(Stack Algorithm)。栈算法保证:n+1 个页框时驻留的页面集合是 n 个页框时的超集,因此不会出现 Belady 异常。OPT、LRU 都是栈算法。
存储管理功能所需的硬件支撑
| 功能 | 所需硬件 |
|---|---|
| 静态重定位 | 无(装入时软件完成) |
| 动态重定位 | 基址寄存器、MMU |
| 存储保护 | 限长/边界寄存器、权限位检查 |
| 分页地址转换 | 页表基址寄存器、TLB(联想存储器) |
| 虚拟存储 | MMU + 缺页中断机制 |