Transformer
一、为什么需要 Seq2seq?
问题动机
现实中存在大量输入和输出都是变长序列的任务,例如:
| 任务 | 输入 | 输出 | 特点 |
|---|---|---|---|
| 语音识别 | 音频序列(长度T) | 文字序列(长度N) | N ≠ T |
| 机器翻译 | 源语言句子(长度N) | 目标语言句子(长度N’) | N’ 不确定 |
| 语音翻译 | 音频序列 | 目标语言文字 | 跳过中间语言 |
| 聊天机器人 | 对话输入 | 对话回复 | 长度完全不确定 |
| 语法解析 | 句子 | 括号树结构 | 结构化输出 |
| 多标签分类 | 文档 | 若干标签 | 标签数量可变 |
| 目标检测 | 图像 | 若干目标框 + 类别 | 目标数量可变 |
核心思想:把输出长度的决定权交给模型,而不是人为指定。
⚠️ 关键洞察:几乎所有 NLP 任务都可以被 reformulate 成 seq2seq 问题。语法解析输出的树结构,只需线性化成括号序列就可以用 seq2seq 处理(”Grammar as a Foreign Language”,Vinyals et al., 2014)。
二、Seq2seq 整体架构
1
输入序列 → [Encoder] → 上下文向量 → [Decoder] → 输出序列
- Encoder:读取整个输入序列,输出一组向量表示
- Decoder:逐步生成输出序列,每一步都以已生成的内容为条件
两者通过 Cross-Attention(交叉注意力) 桥接。
三、Encoder 详解
3.1 功能
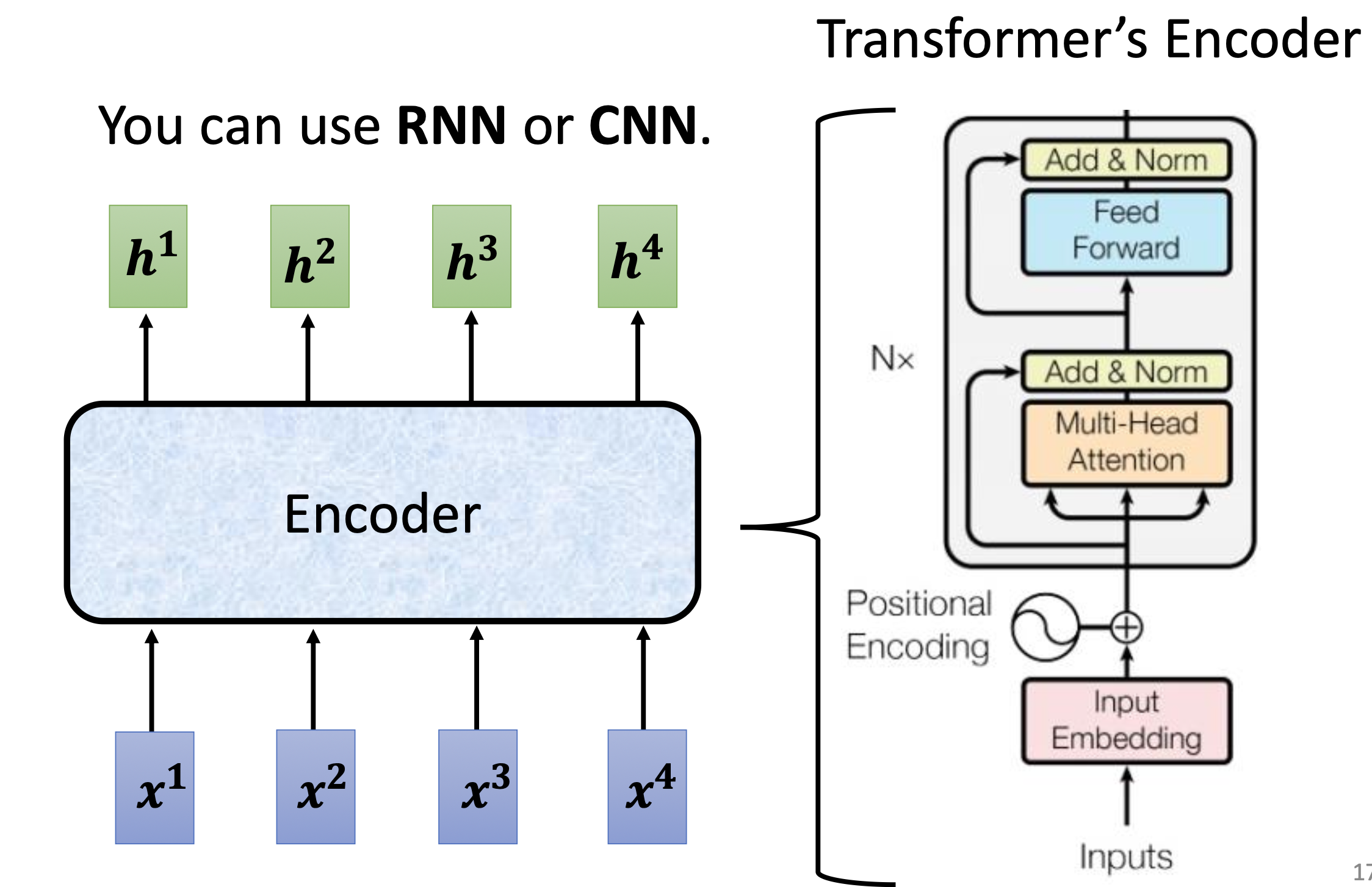
接收输入序列 $x^1, x^2, …, x^N$,输出等长的上下文感知向量 $h^1, h^2, …, h^N$。
每个 $h^i$ 不只代表第 $i$ 个 token,而是融合了全局上下文的表示。
3.2 Transformer Encoder 的结构
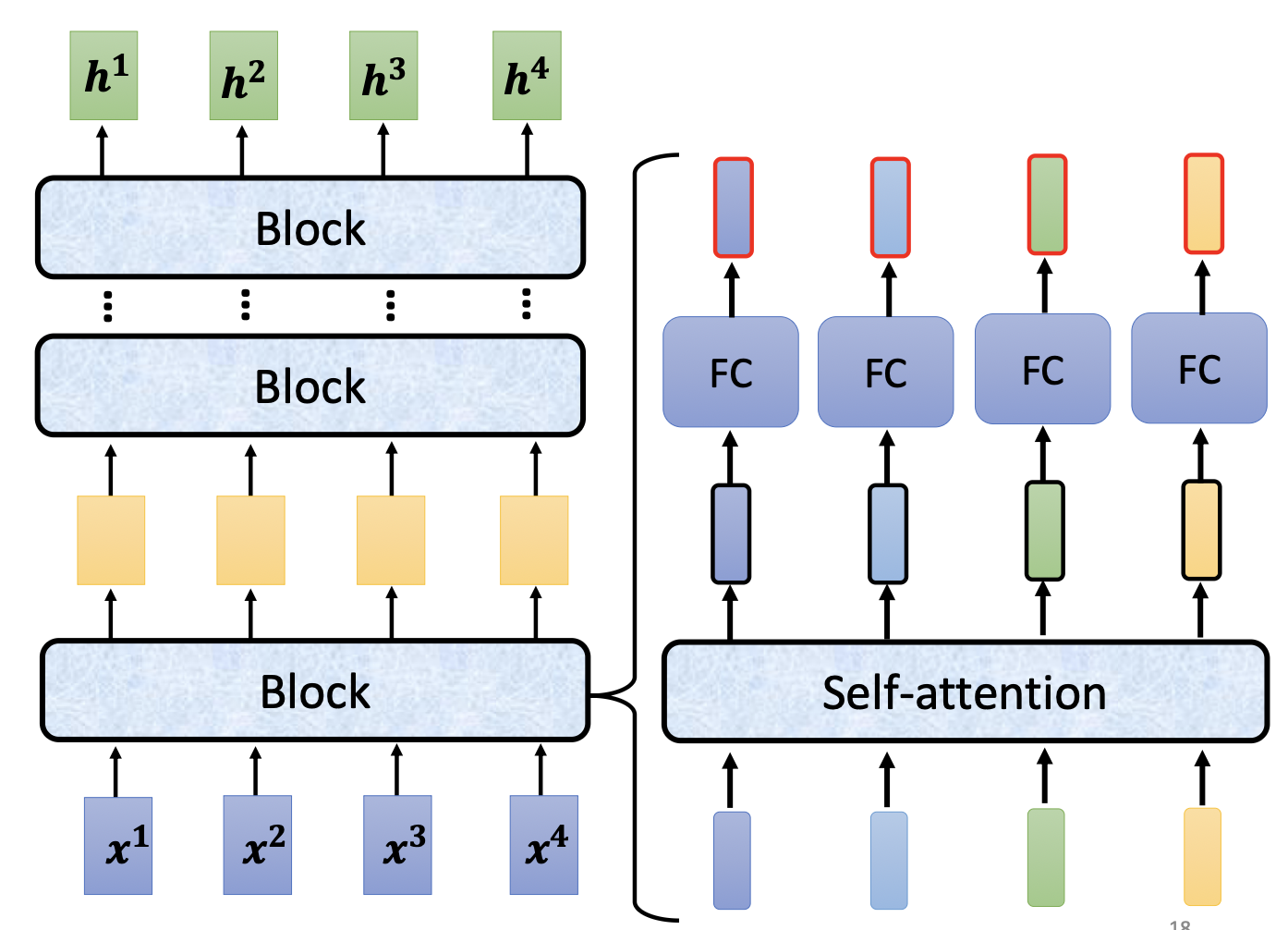
每一个 Block 由以下子层组成(重复 N 次):
1
2
3
4
5
6
7
8
9
10
11
12
13
输入
↓
[Input Embedding + Positional Encoding]
↓
[Multi-Head Self-Attention]
↓
[Add & Norm] ← 残差连接 + Layer Normalization
↓
[Feed Forward Network]
↓
[Add & Norm]
↓
输出
3.3 为什么用 Layer Norm 而不是 Batch Norm?
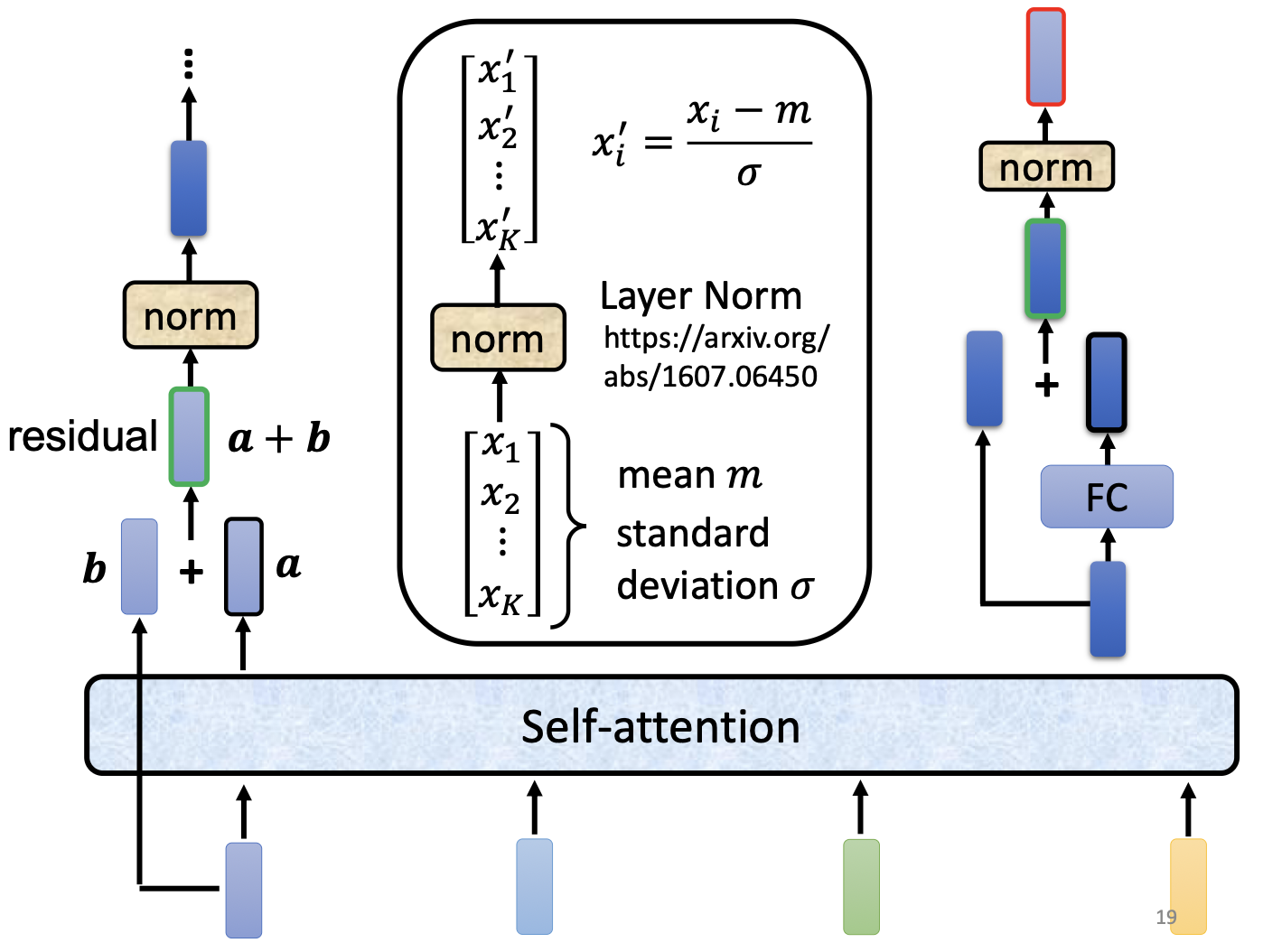
- Batch Norm:在一个 batch 内,对同一特征维度做归一化
- Layer Norm:对单个样本的所有特征维度做归一化
其中 $m$ 是该样本所有维度的均值,$\sigma$ 是标准差。
为什么 Transformer 选 Layer Norm:
- 序列长度可变,Batch Norm 跨样本统计不稳定
- Layer Norm 只依赖单个样本,适合变长序列
- 训练更稳定
注意:原始 Transformer 的 Layer Norm 在 attention 之后(Post-LN)。后来研究发现放在 attention 之前(Pre-LN)训练更稳定(见
arxiv:2002.04745)。
3.4 残差连接(Residual Connection)
每个子层的输出是:
\[\text{output} = \text{LayerNorm}(x + \text{Sublayer}(x))\]作用:
- 缓解梯度消失
- 保留原始输入信息,防止层数过深时信息被覆盖
- BERT 与 Transformer Encoder 共享完全相同的结构
四、Decoder 详解
4.1 两种 Decoder 范式对比
Autoregressive(AT,自回归)
1
2
3
输出过程:
START → 机 → 机器 → 机器学 → 机器学习 → END
(每步用上一步的输出作为下一步的输入)
特点:
- 输出是串行生成的,不能并行
- 每步依赖上一步,错误会累积(error propagation)
- 质量通常更高
Non-Autoregressive(NAT,非自回归)
1
START START START START → 并行输出 → 机 器 学 习
特点:
- 输出完全并行,速度快
- 需要额外机制确定输出长度
- 质量通常低于 AT,原因是多模态问题(Multi-modality)
多模态问题:同一句话有多种合法翻译(如 “How are you” 可译为”你好吗”/”最近怎么样”),NAT 尝试同时生成所有可能,导致输出模糊混乱。
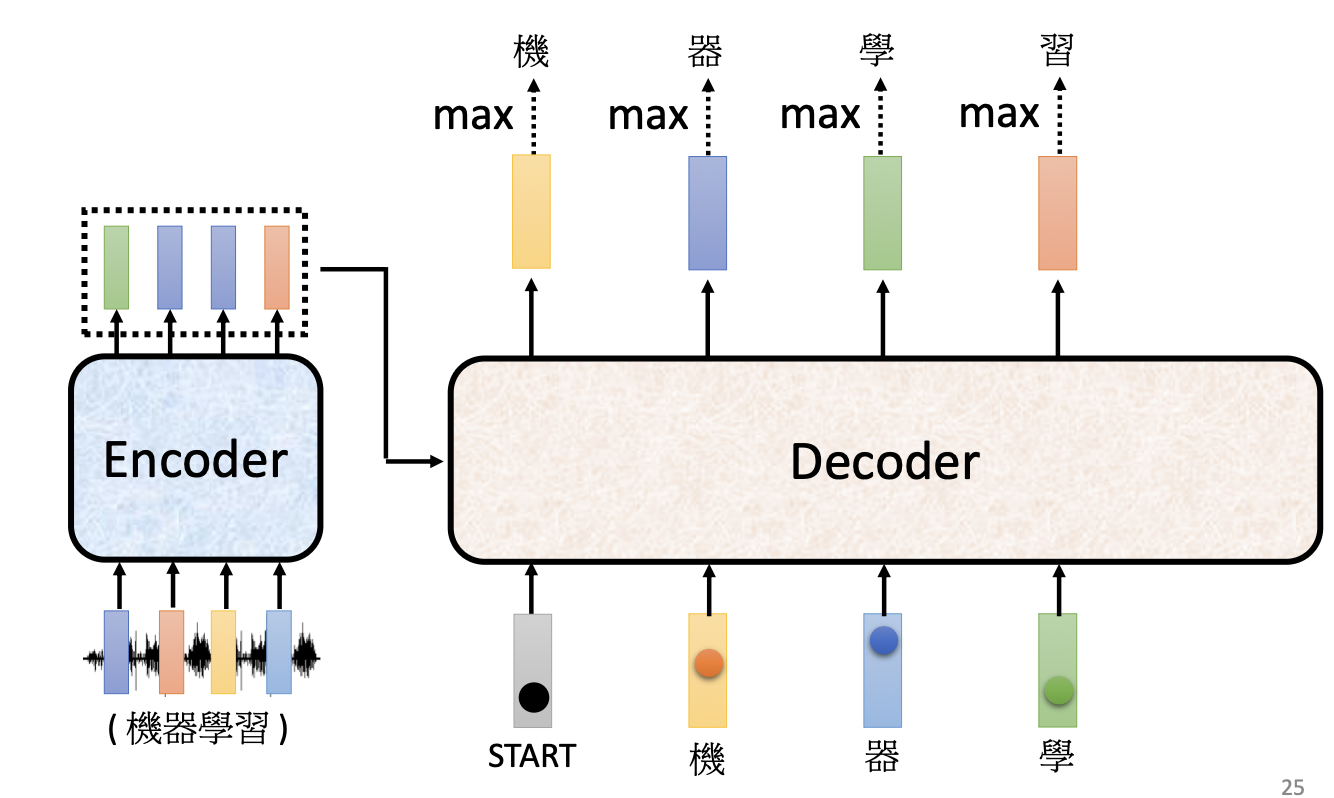
4.2 Autoregressive Decoder 的工作流程
- 接收特殊起始 token
<BOS>/START - 读取 Encoder 输出(通过 Cross-Attention)
- 输出一个词表大小的概率分布(softmax)
- 取 argmax 得到第一个 token “机”
- 将 “机” 作为下一步输入,重复直到输出
<EOS>/END
4.3 如何处理终止条件?
问题:模型不知道应该何时停止。
解决方案:在词表中加入特殊 Stop Token <EOS>。
当 softmax 输出中 <EOS> 的概率最大时,停止生成。这个停止行为是模型学到的,不是硬编码的。
4.4 Transformer Decoder 的结构
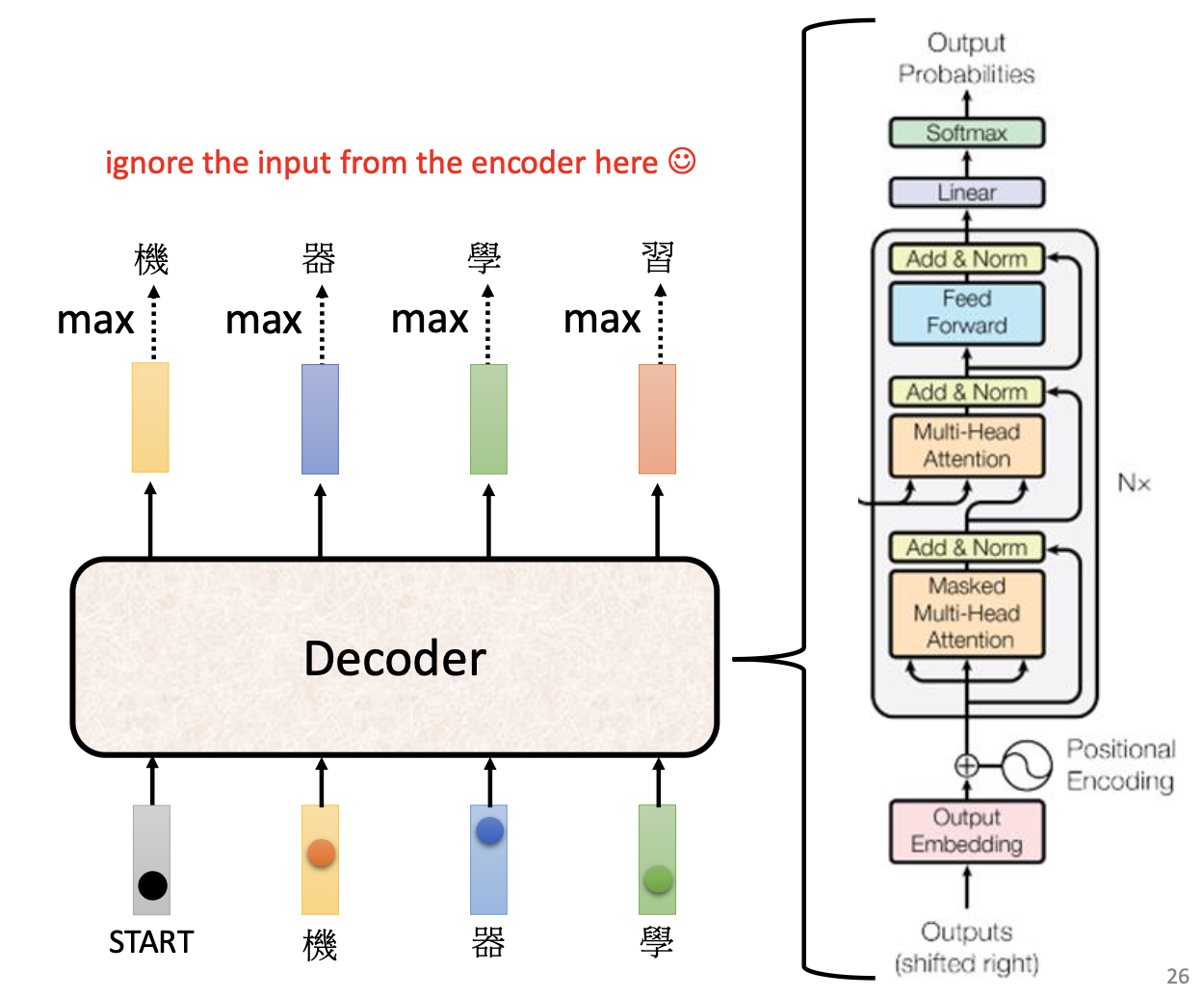
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Outputs (shifted right)
↓
[Output Embedding + Positional Encoding]
↓
[Masked Multi-Head Self-Attention] ← 关键!只看已生成的内容
↓
[Add & Norm]
↓
[Multi-Head Cross-Attention] ← 读取 Encoder 的输出
↓
[Add & Norm]
↓
[Feed Forward Network]
↓
[Add & Norm]
↓
[Linear → Softmax]
↓
Output Probabilities
4.5 为什么 Self-Attention 要加 Mask?
问题:训练时所有输出 token 已知,可以并行计算。但推理时 Decoder 是自回归的,生成第 $t$ 个 token 时,只能看到前 $t-1$ 个 token。
解决:Masked Self-Attention 在计算第 $t$ 个位置时,mask 掉所有位置 $> t$ 的 attention score(设为 $-\infty$,softmax 后变为 0)。
1
2
3
4
5
位置: 1 2 3 4
1 可见 不见 不见 不见
2 可见 可见 不见 不见
3 可见 可见 可见 不见
4 可见 可见 可见 可见
这保证了训练和推理行为的一致性。
五、Cross-Attention(编解码注意力)
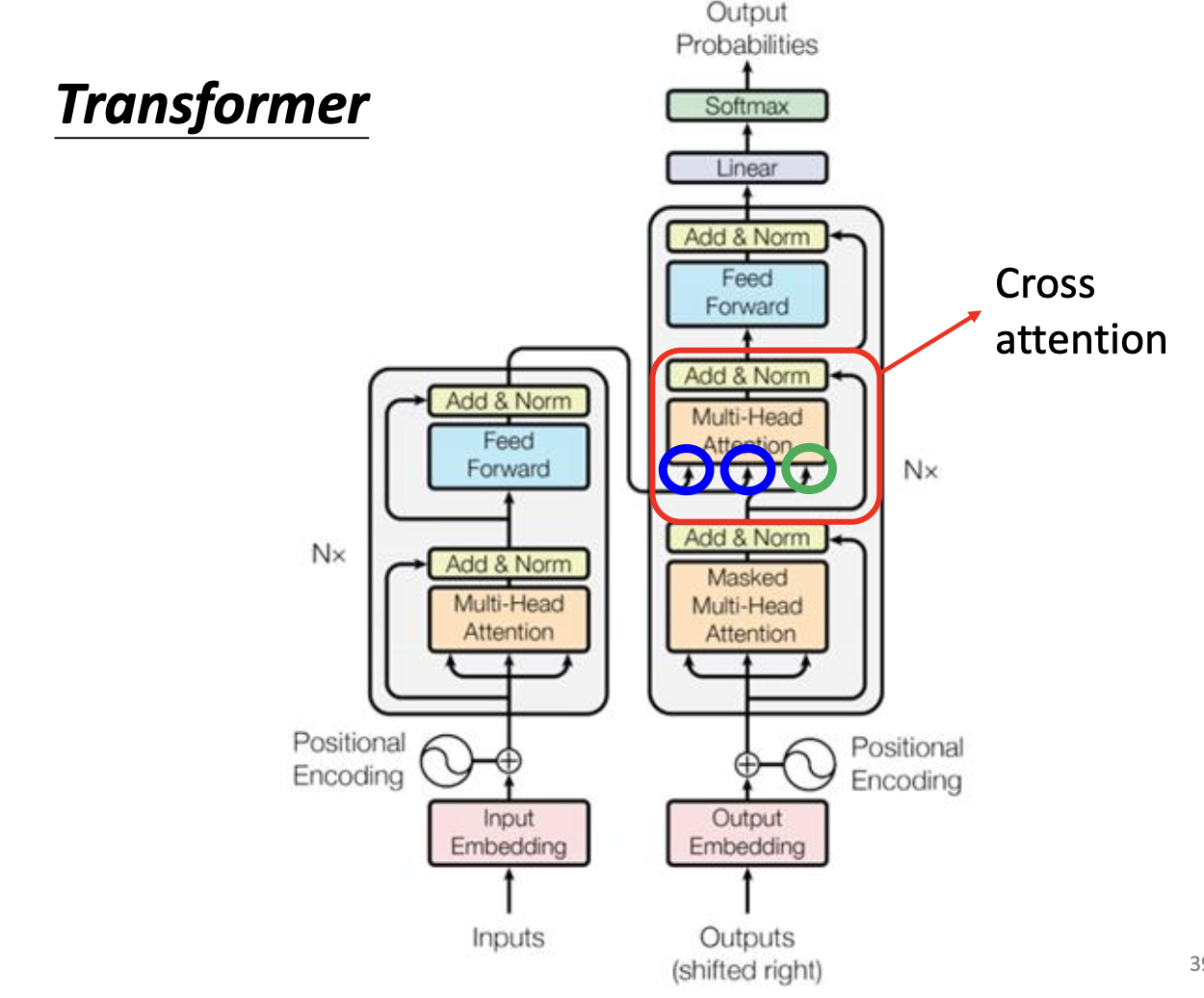
5.1 机制
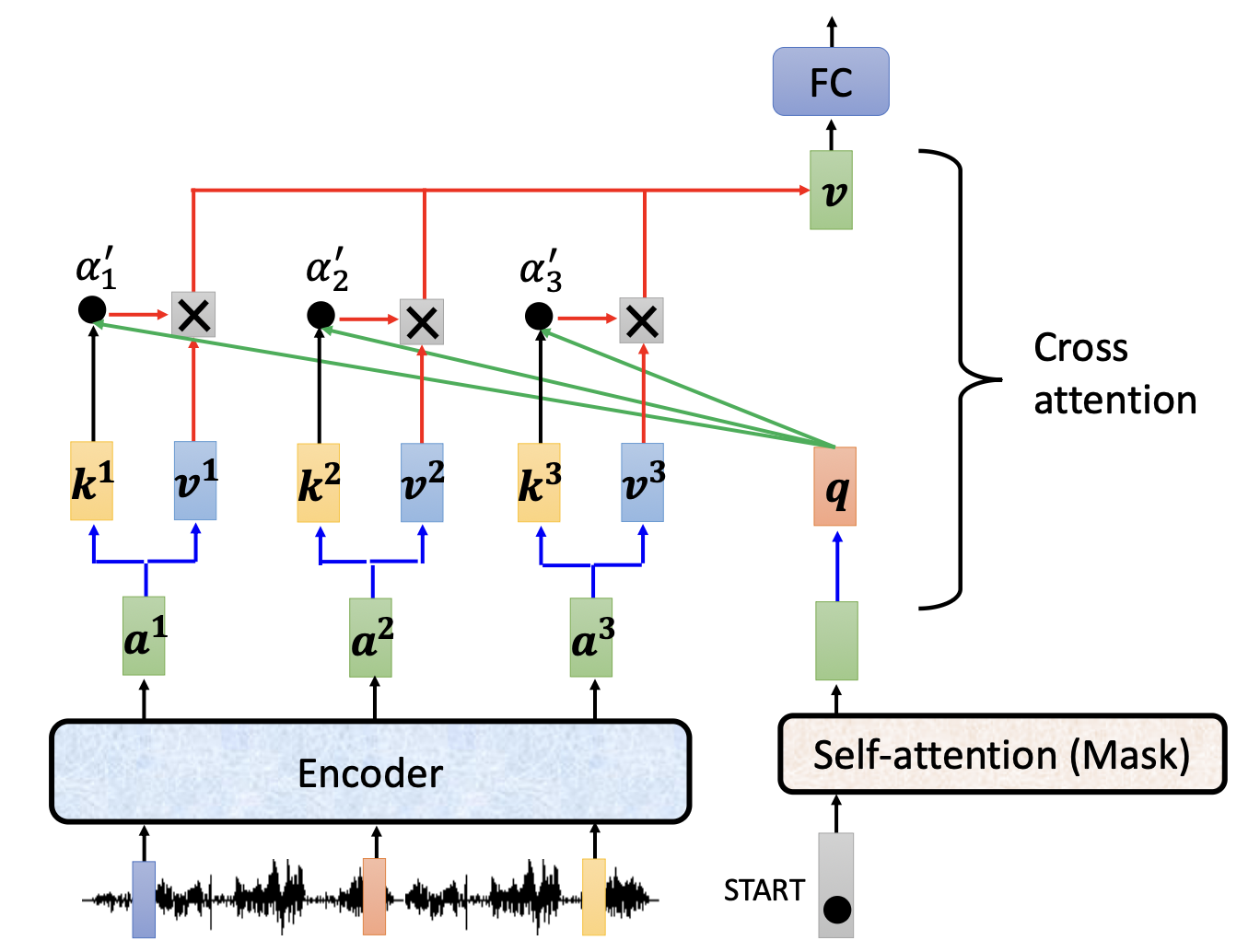
Cross-Attention 是 Encoder 和 Decoder 的桥梁:
- Query(Q):来自 Decoder 当前状态
- Key(K)和 Value(V):来自 Encoder 的输出
直觉:Decoder 用当前生成的内容作为”问题”,去询问 Encoder 输出的”哪些部分”与当前生成最相关。
5.2 信息流
1
2
3
4
5
6
7
8
9
10
11
Encoder 输出: a¹, a², a³
↓ ↓ ↓
k¹,v¹ k²,v² k³,v³
↑
Decoder 当前状态 → Masked Self-Attn → q
↓
计算 α'₁, α'₂, α'₃(softmax)
↓
加权求和 v → 输出上下文向量
↓
Feed Forward → 下一个 token
5.3 不同层之间的 Cross-Attention 连接方式
原始 Transformer 中,每个 Decoder 层都连接到 Encoder 最后一层的输出。研究者也探索了其他连接方式:
- 每个 Decoder 层连接对应层的 Encoder 输出
- 全连接(每个 Decoder 层可以连接所有 Encoder 层)
六、训练:Teacher Forcing
6.1 标准训练目标
每个时间步的训练目标:最小化真实 token 和预测分布之间的交叉熵。
\[\mathcal{L} = -\sum_t \log P(y_t^* | y_1^*, ..., y_{t-1}^*, x)\]6.2 Teacher Forcing
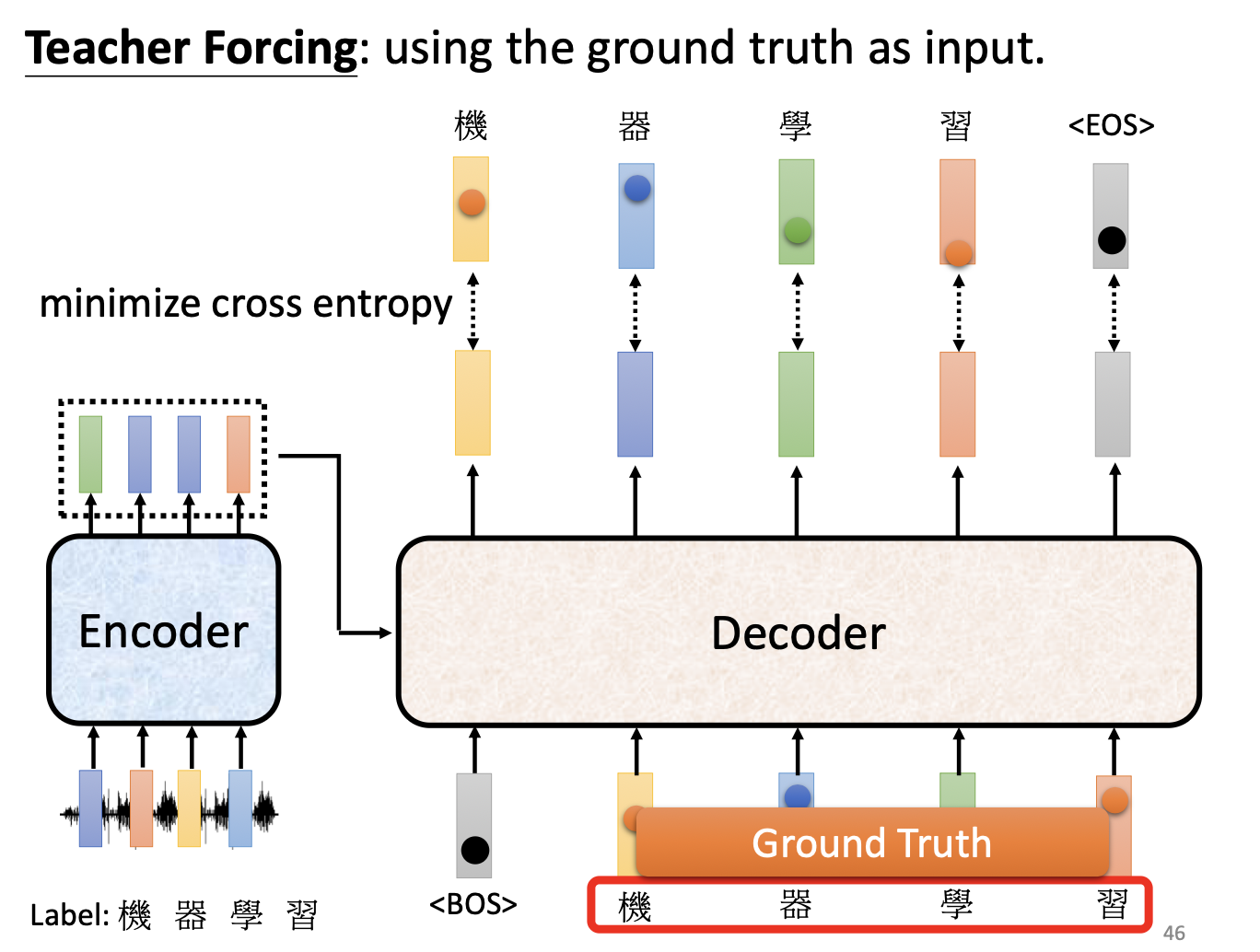
训练时:Decoder 的输入是 Ground Truth,而不是上一步的模型预测输出。
1
2
输入:<BOS>, 机, 器, 学 (真实标签)
目标:机, 器, 学, 习, <EOS>
优点:
- 训练信号稳定,不会因前期错误而级联失败
- 可以高度并行化
缺点:引入 Exposure Bias(曝光偏差)
6.3 Exposure Bias 问题
训练时 Decoder 的输入始终是 Ground Truth(理想条件),但推理时 Decoder 的输入是模型自己的上一步输出(可能有错误)。
这造成了训练-推理分布不匹配:模型从未在训练中见过”接收错误输入后如何纠正”的情况。
解决方案:Scheduled Sampling
训练时以一定概率随机选择:
- 使用 Ground Truth token(Teacher Forcing)
- 使用模型自己的预测 token(模拟推理条件)
随着训练进行,逐渐增大使用自身预测的比例。
七、推理技巧
7.1 Greedy Decoding
每一步选择概率最高的 token。
问题:局部最优不等于全局最优。
1
2
3
例:选了概率 0.9 的 A,下一步只有概率 0.4 的 token
不如选概率 0.6 的 B,下一步有概率 0.9 的 token
路径 B→... 的联合概率更高
7.2 Beam Search
维持 $k$ 条候选路径(beam width = $k$),每步从所有候选中保留联合概率最高的 $k$ 条。
- 计算复杂度 $O(k \times V \times T)$,$V$ 为词表大小
- 是 Greedy 和穷举搜索之间的工程折中
- 不保证找到全局最优解
Beam Search 的局限:对于创意性任务(开放域对话、故事生成),Beam Search 倾向于生成重复、平淡的文本(陷入循环),如”University of … University of …“。
7.3 Sampling(随机采样)
从概率分布中随机采样而非取 argmax,引入多样性。
变体:
- Top-k Sampling:只从概率最高的 $k$ 个 token 中采样
- Nucleus (Top-p) Sampling:从累积概率超过 $p$ 的最小集合中采样
任务依赖性:
- 确定性任务(翻译、摘要)→ Beam Search
- 创意性任务(对话、故事)→ Sampling
八、训练技巧
8.1 Copy Mechanism(复制机制)
问题:某些 token(人名、专有名词、未登录词)不应该被”生成”,而应该直接从输入复制。
实现思路(Pointer Network / CopyNet):
模型在每一步决策:
- 从词表生成一个 token,概率 $p_{\text{gen}}$
- 从输入序列复制一个 token,概率 $1 - p_{\text{gen}}$
最终分布是两者的加权混合。
典型应用:文本摘要、对话系统(复制用户名字)、机器翻译(复制专有名词)
8.2 Guided Attention
问题:在语音合成(TTS)等任务中,输入和输出存在单调对齐关系(先读前面的字再读后面的字)。但模型的 attention 可能学到非单调、跳跃式的对齐,导致漏字、重复等问题。
解决:在训练时加入注意力正则化约束,强制注意力权重符合单调递增的对角线形状(Monotonic Attention)。
8.3 优化评估指标
问题:训练用交叉熵,评估用 BLEU score(机器翻译)。两者不一致,优化前者不等于优化后者。
BLEU score 是不可微的,无法直接做梯度下降。
解决:用强化学习(RL)。把 Decoder 视为 Policy,把 BLEU score 视为 Reward,用 REINFORCE 算法优化。
九、AT vs NAT 系统性对比
| 维度 | Autoregressive (AT) | Non-Autoregressive (NAT) |
|---|---|---|
| 生成方式 | 串行,逐 token | 并行,一次全出 |
| 速度 | 慢($O(T)$ 步) | 快($O(1)$ 步) |
| 质量 | 高 | 低(多模态问题) |
| 长度控制 | 靠 EOS token | 需要额外预测器或截断 |
| 稳定性 | 易错误累积 | 稳定(TTS 等场景好) |
| 适用场景 | 翻译、摘要、QA | TTS、特定条件生成 |
十、Transformer 完整架构总结
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
Output Probabilities
↑
[Softmax]
[Linear]
[Add & Norm]
[Feed Forward] N×
[Add & Norm]
[Multi-Head Cross-Attention] ←──────── Encoder 输出
[Add & Norm]
[Masked Multi-Head Self-Attention]
[Positional Encoding + Output Embedding]
↑
Decoder 输入(shifted right)
Encoder 输出 (h¹...hⁿ)
↑
[Add & Norm]
[Feed Forward] N×
[Add & Norm]
[Multi-Head Self-Attention]
[Positional Encoding + Input Embedding]
↑
输入序列
关键设计决策及其原因
| 设计 | 为什么 |
|---|---|
| Self-Attention 替代 RNN | 并行计算;任意两位置直接交互,不受距离限制 |
| Positional Encoding | Self-Attention 本身无位置感知,需要外加位置信息 |
| Layer Norm | 变长序列中比 Batch Norm 更稳定 |
| Residual Connection | 防止梯度消失,允许堆叠深层网络 |
| Masked Self-Attention | 保证 Decoder 训练/推理行为一致 |
| Cross-Attention | 允许 Decoder 在生成时选择性地关注输入的不同部分 |
十一、常见误区
- BERT ≠ 完整 Transformer:BERT 只使用 Transformer 的 Encoder 部分,没有 Decoder。
- Masked Attention 的”mask”原因:不是防止信息泄露(那是训练的事),而是保证推理时的因果性。
- Teacher Forcing 只用于训练:推理时永远用自身输出,Teacher Forcing 是训练技巧。
- Beam Search 不等于 Greedy:Beam Search 是近似全局搜索,但仍非全局最优;Beam width=1 时退化为 Greedy。
- NAT 并不总是更快:长序列下优势明显,短序列下差异不大,且质量代价不容忽视。
延伸阅读
| 主题 | 论文 |
|---|---|
| 原始 Transformer | Attention Is All You Need (arxiv:1706.03762) |
| 原始 Seq2seq (RNN) | Sequence to Sequence Learning with Neural Networks (arxiv:1409.3215) |
| Layer Norm 位置讨论 | On Layer Normalization in the Transformer Architecture (arxiv:2002.04745) |
| NAT 详解 | (YouTube: youtu.be/jvyKmU4OM3c) |
| Copy Mechanism | Get To The Point (arxiv:1704.04368) |
| Pointer Network | arxiv:1603.06393 |
| Scheduled Sampling | arxiv:1506.03099 |
| RL for Seq2seq | arxiv:1511.06732 |
| Neural Text Degeneration | arxiv:1904.09751 |