PAC
为什么需要 PAC 框架?
核心问题: 训练误差很低,但我们真正关心的是泛化误差。两者之间的关系能被量化吗?

具体而言,以下问题都没有严格答案:
- 训练误差 5%,测试误差能保证多少?
- 测试集上表现好,是“真好”还是“碰巧好”?
- 训练这个模型需要多少数据?
解决思路(Valiant, 1984): 引入概率,对“学习成功”给出概率性保证。
PAC 框架的基本符号与定义
基本符号
| 符号 | 含义 |
|---|---|
| $\mathcal{X}$ | 输入空间(所有可能的样本) |
| $\mathcal{Y}$ | 输出空间(标签,如 ${-1,+1}$) |
| $c: \mathcal{X} \to \mathcal{Y}$ | 目标概念(hidden,未知) |
| $C$ | 概念类(所有可能概念的集合) |
| $H$ | 假设集(学习者考虑的所有假设) |
| $D$ | 样本分布(fixed but unknown) |
| $S$ | 训练样本 $(x_1,\ldots,x_m)$,i.i.d. 采自 $D$ |
关键区分: 目标概念 $c \in C$ 未知;分布 $D$ 也未知;但学习者知道 $C$ 和 $H$。
两种误差
泛化误差(Generalization Error / True Risk):
\[\mathcal{R}(h) = \mathbb{P}*{x \sim D}[h(x) \neq c(x)] = \mathbb{E}*{x \sim D}[\mathbf{1}_{h(x) \neq c(x)}]\]- 是对真实分布上所有点的期望,不可直接计算。
经验误差(Empirical Error):
\[\hat{\mathcal{R}}*S(h) = \frac{1}{m}\sum*{i=1}^{m}\mathbf{1}_{h(x_i) \neq c(x_i)}\]- 是在训练集上的平均误差,可计算。
重要关系:
\[\mathbb{E}_{S \sim D^m}[\hat{\mathcal{R}}_S(h)] = \mathcal{R}(h)\]经验误差是泛化误差的无偏估计(但单个样本上的估计仍有随机性)。
PAC 可学习性的定义
定义(PAC-learnable): 概念类 $C$ 称为 PAC 可学习的,若存在算法 $\mathbb{A}$ 和多项式函数 $\text{poly}(\cdot,\cdot)$,使得对任意 $\epsilon > 0$,$\delta > 0$,任意分布 $D$,任意目标概念 $c \in C$,只要样本量:
\[m \geq \text{poly}!\left(\frac{1}{\epsilon}, \frac{1}{\delta}\right)\]就有: \(\mathbb{P}_{S \sim D^m}[\mathcal{R}(h_S) \leq \epsilon] \geq 1 - \delta\)
三层含义拆解:
- $\epsilon$(approximately correct): 泛化误差至多 $\epsilon$
- $1-\delta$(probably): 以至少 $1-\delta$ 的概率成立
- 多项式样本量: 需要的数据量是 $1/\epsilon$ 和 $1/\delta$ 的多项式
两个重要性质:
- Distribution-free: 对任意分布 $D$ 均成立,无需假设数据分布
- 针对概念类 $C$,不是某个具体的 $c$
案例:轴对齐矩形(Axis-aligned Rectangles)
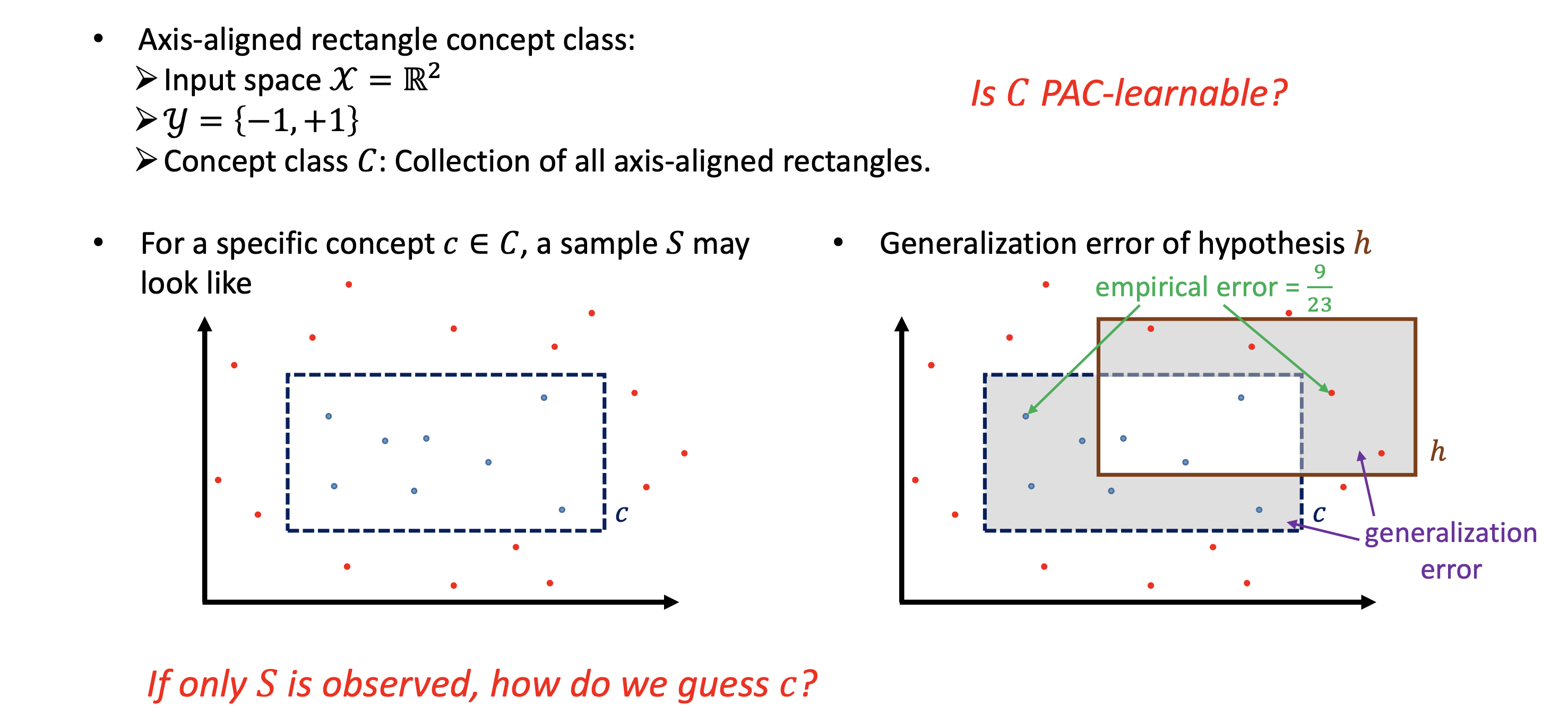
问题设置: 输入 $\mathcal{X} = \mathbb{R}^2$,概念类 $C$ 为所有轴对齐矩形,$c \in C$ 为某个具体矩形(内部的点标 $+1$)。
算法(Closure Algorithm): 给定样本 $S$,返回包含所有正样本的最小矩形 $h_S$。
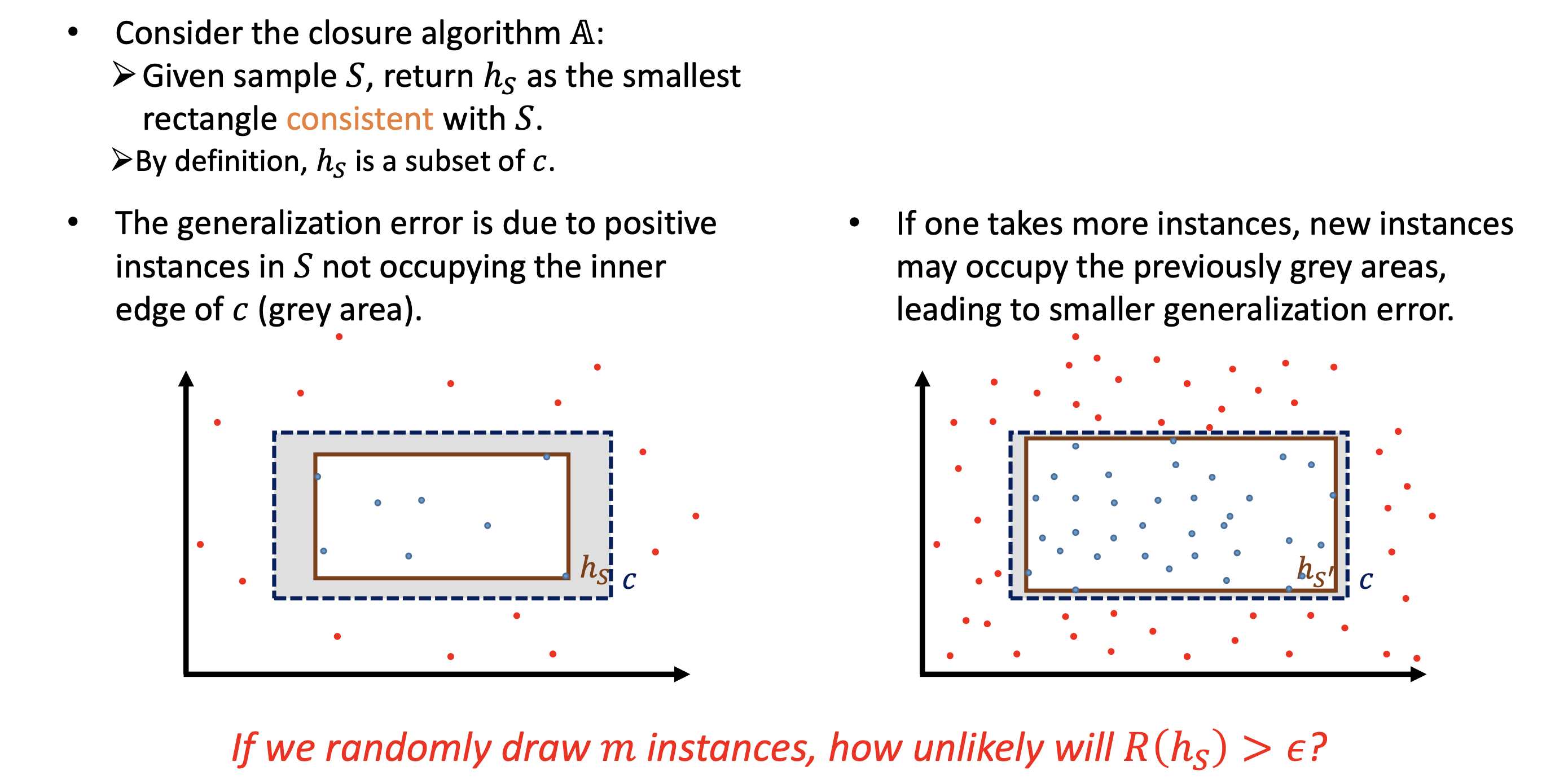
推导:何时 $\mathcal{R}(h_S) > \epsilon$?
将真实矩形 $c$ 的四条边内侧各取一个条带区域,每个区域的概率质量恰好为 $\epsilon/4$。若样本 $S$ 至少触碰到每一个条带,则 $\mathcal{R}(h_S) \leq \epsilon$。
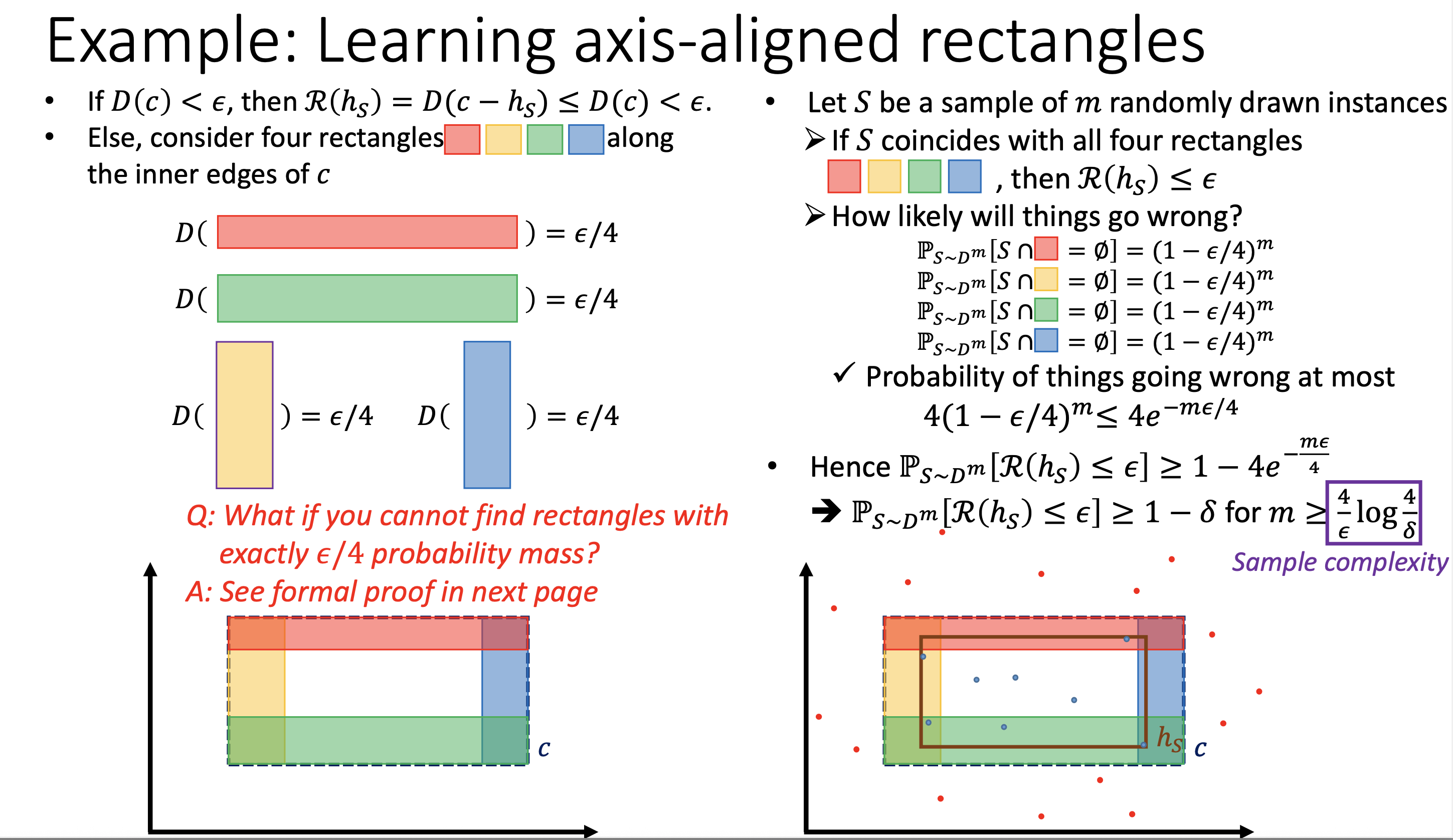
由 union bound,出问题的概率:
\[\mathbb{P}[\mathcal{R}(h_S) > \epsilon] \leq 4(1 - \epsilon/4)^m \leq 4e^{-m\epsilon/4}\]令此式 $\leq \delta$,解出 $m$:
\[m \geq \frac{4}{\epsilon} \log \frac{4}{\delta}\]结论: 轴对齐矩形是 PAC 可学习的,样本复杂度为 $O!\left(\frac{1}{\epsilon}\log\frac{1}{\delta}\right)$。
推广至 $n$ 维轴对齐超立方体(formal proof,Theorem 7.2):
\[m \geq \frac{2n}{\epsilon}\log\frac{2n}{\delta}\]有限假设集的样本复杂度
Consistent Case
假设: 算法 $\mathbb{A}$ 能找到与训练集完全一致的假设,即 $\hat{\mathcal{R}}_S(\mathbb{A}(S)) = 0$。
定理(Mohri 2012, Theorem 2.1):
\[\mathbb{P}_{S \sim D^m}[\mathcal{R}(\mathbb{A}(S)) \leq \epsilon] \geq 1 - |H| e^{-m\epsilon}\]等价地:
\[\mathbb{P}_{S \sim D^m}!\left[\mathcal{R}(\mathbb{A}(S)) \leq \frac{1}{m}!\left(\log|H| + \log\frac{1}{\delta}\right)\right] \geq 1 - \delta\]样本复杂度:
\[m \geq \frac{\log|H| + \log(1/\delta)}{\epsilon}\]| 直觉: 假设集越大,需要越多数据才能“排除”坏假设。$\log | H | $ 是假设集“大小”的有效度量。 |
证明思路
定义“坏假设”集合 $H_\epsilon = {h \in H : \mathcal{R}(h) > \epsilon}$。
若算法输出的假设在 $H_\epsilon$ 中,则它虽然在训练集上完美,但泛化误差超过 $\epsilon$。这要求该坏假设恰好在 $m$ 个样本上全部正确,概率为:
\[\mathbb{P}[h(S) = c(S)] \leq (1-\epsilon)^m \leq e^{-m\epsilon}\]| 用 union bound 对所有 $ | H_\epsilon | \leq | H | $ 个坏假设求和,得到上界。 |
Empirical Risk Minimization(ERM)
思路: 既然无法直接最小化真实风险 $\mathcal{R}(h)$,就最小化经验风险:
\[h_S^{ERM} \in \arg\min_{h \in H} \hat{\mathcal{R}}_S(h)\]ERM 的次优性分析:
\[\mathcal{R}(h_S^{ERM}) - \mathcal{R}(h^*) \leq 2\sup_{h \in H}|\hat{\mathcal{R}}_S(h) - \mathcal{R}(h)|\]即 ERM 的超额风险被“所有假设上经验误差与真实误差的最大偏差”所控制。这个量是后续 Rademacher 复杂度要绑定的核心对象。
Inconsistent Case
场景: 不再假设训练集上存在零误差假设(更一般,更实用)。
定理(Mohri 2012, Theorem 2.2):
\[\mathbb{P}*{S \sim D^m}!\left[\max*{h \in H}|\hat{\mathcal{R}}_S(h) - \mathcal{R}(h)| < \epsilon\right] \geq 1 - 2|H|e^{-2m\epsilon^2}\]等价地:
\[\mathbb{P}!\left[\max_{h \in H}|\hat{\mathcal{R}}_S(h) - \mathcal{R}(h)| < \sqrt{\frac{\log|H| + \log(2/\delta)}{2m}}\right] \geq 1 - \delta\]样本复杂度:
\[m \geq \frac{\log|H| + \log(2/\delta)}{2\epsilon^2}\]对比 consistent 情形: 分母从 $\epsilon$ 变成了 $2\epsilon^2$,需要更多数据;但这是更强的保证(对所有假设同时成立的一致收敛)。
Rademacher 复杂度
为什么需要 Rademacher 复杂度?
| 有限假设集的界依赖 $\log | H | $,但若 $ | H | = \infty$(如神经网络),此方法失效。 |
需要一种度量假设集“有效大小”(expressiveness)的方法 —— Rademacher 复杂度。
损失函数族 $G$
对假设集 $H$,每个假设 $h_\theta$ 通过损失函数 $L$ 对应一个函数:
\[g_\theta(x, \hat{y}) = L(h_\theta(x), \hat{y})\]$G = {g_\theta : \theta \in \Theta}$ 是所有损失函数构成的函数族。
关键观察: $G$ 越大 → 越容易拟合训练集 → 越容易过拟合。因此对 $G$ 大小的度量直接关系到泛化界。
Rademacher 复杂度的定义
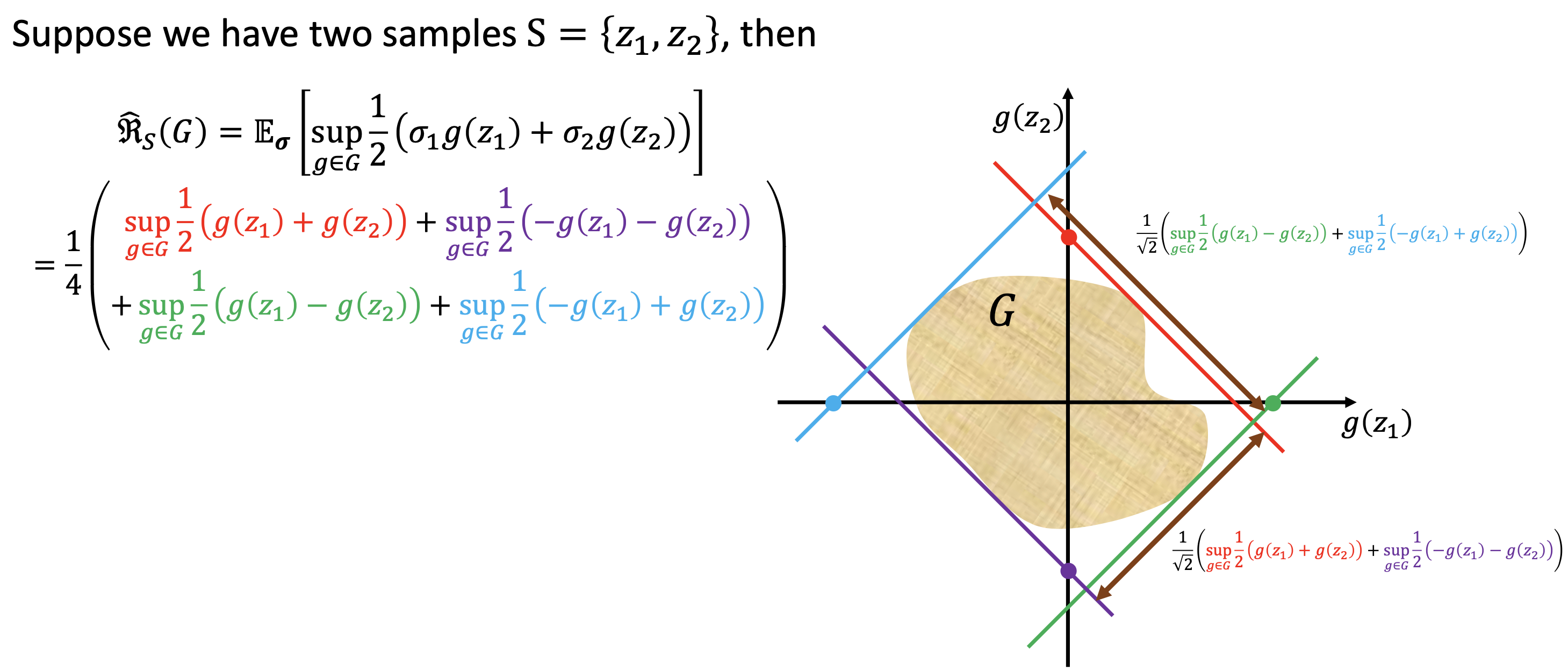
经验 Rademacher 复杂度(针对固定样本 $S$):
\[\hat{\mathfrak{R}}*S(G) = \mathbb{E}*{\boldsymbol{\sigma}}!\left[\sup_{g \in G}\frac{1}{m}\sum_{i=1}^{m}\sigma_i g(z_i)\right]\]其中 $\sigma_i$ 是独立均匀取值于 ${-1,+1}$ 的 Rademacher 变量。
Rademacher 复杂度(期望版本): \(\mathfrak{R}*m(G) = \mathbb{E}*{S \sim D^m}[\hat{\mathfrak{R}}_S(G)]\)
几何直觉: $\hat{\mathfrak{R}}_S(G)$ 衡量 $G$ 中的函数与随机噪声标签的相关程度。若 $G$ 很”大”,总能找到一个 $g$ 与任意随机标签高度相关,表明 $G$ 可以拟合噪声 → 容易过拟合。
二分类泛化界
定理(Mohri 2012, Theorem 3.2):
对 0-1 损失,以至少 $1-\delta$ 的概率:
\[\sup_{h \in H}[\mathcal{R}(h) - \hat{\mathcal{R}}_S(h)] \leq \mathfrak{R}_m(H) + \sqrt{\frac{\log(1/\delta)}{2m}}\]含义: 泛化误差与训练误差之差被以下两项之和控制:
- $\mathfrak{R}_m(H)$:假设集的 Rademacher 复杂度(模型复杂度项)
- $\sqrt{\log(1/\delta)/(2m)}$:置信项(样本量越大越小)
神经网络的 Rademacher 复杂度
| 对于标准全连接神经网络(深度 $d$,权重矩阵范数约束 $ | W_k | {p,q} \leq M{p,q,k}$),Rademacher 复杂度有上界(Golowich et al., 2018): |
当 $p=q=2$ 时: \(\hat{\mathfrak{R}}*{S*\mathcal{X}}(H_d) \leq \frac{BM_{2,2}\sqrt{2(d-1)\log 2 + 1}}{\sqrt{m}}\)
关键洞察: 该上界与网络宽度无关(size-independent),只依赖深度 $d$、权重范数乘积 $M_{2,2}$ 和数据范数 $B$。这解释了为什么过参数化的神经网络仍能泛化。
增长函数与 VC 维度
增长函数(Growth Function)
\[\Pi_H(m) = \max_{x_1,\ldots,x_m \in \mathcal{X}}\left|{(h(x_1),\ldots,h(x_m)) : h \in H}\right|\]即 $H$ 在 $m$ 个点上能产生的最大不同标签模式数。最大为 $2^m$(完全打散)。
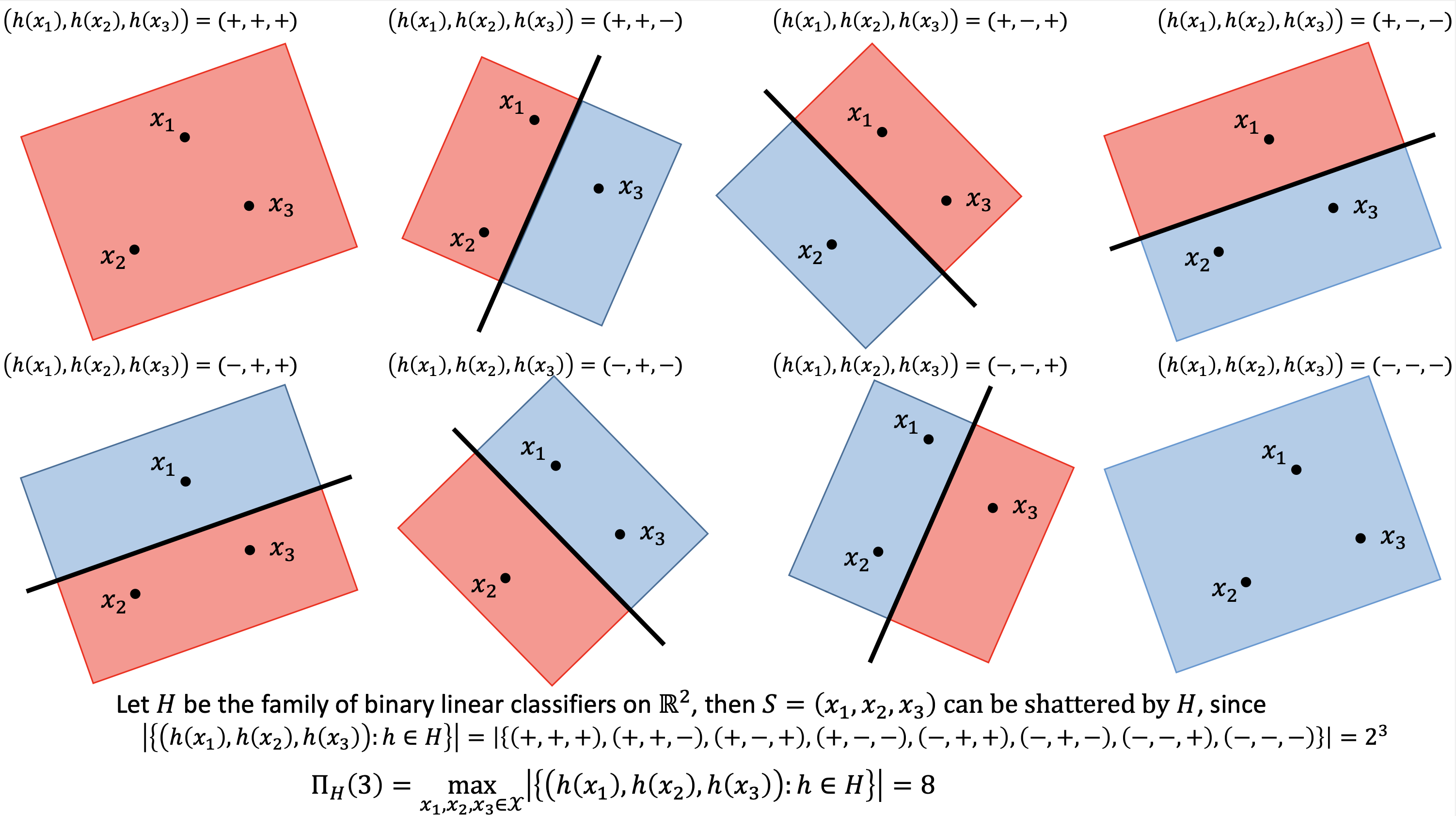
Shattering 与 VC 维度
打散(Shattering): 若 $H$ 在样本 $S = (x_1,\ldots,x_m)$ 上产生所有 $2^m$ 种标签组合,则称 $H$ 打散了 $S$。
VC 维度: \(\text{VCdim}(H) = \sup{m : \Pi_H(m) = 2^m}\)
即 $H$ 能打散的最大集合的大小。
例: $\mathbb{R}^2$ 上的线性分类器(半平面)可以打散任意 3 个不共线的点,但无法打散任意 4 个点。 \(\text{VCdim}(H) = 3\)
一般结论(Mohri Theorem 3.4): $\mathbb{R}^d$ 上超平面决策边界的二分类器的 VC 维度为 $d+1$。

Sauer 引理与 VC 维度的泛化界
Sauer 引理: 若 $H$ 的 VC 维度为 $d$,则:
\[\Pi_H(m) \leq \left(\frac{em}{d}\right)^d\]由此可以建立 Rademacher 复杂度与增长函数的关系(Mohri Corollary 3.1):
\[\mathfrak{R}_m(H) \leq \sqrt{\frac{2\log\Pi_H(m)}{m}}\]最终,以至少 $1-\delta$ 的概率,泛化界为:
\[\sup_{h \in H}[\mathcal{R}(h) - \hat{\mathcal{R}}_S(h)] \leq \sqrt{\frac{2d\log(em/d)}{m}} + \sqrt{\frac{\log(1/\delta)}{2m}}\]三者关系链:
\[\text{VC维度} \xrightarrow{\text{Sauer引理}} \text{增长函数} \xrightarrow{\text{Corollary 3.1}} \text{Rademacher复杂度} \xrightarrow{\text{Thm 3.2}} \text{泛化界}\]三大复杂度度量的对比与定位
| 度量 | 适用场景 | 依赖什么 | 局限 |
|---|---|---|---|
| $\log | H | $ | $ |
| Rademacher 复杂度 | $ | H | $ 有限或无限 |
| VC 维度 | 二分类,$ | H | $ 无限 |
关键公式
PAC 可学习的样本复杂度(有限 $H$,consistent):
\[m \geq \frac{\log|H| + \log(1/\delta)}{\epsilon}\]有限 $H$,inconsistent(一致收敛):
\[m \geq \frac{\log|H| + \log(2/\delta)}{2\epsilon^2}\]轴对齐矩形:
\[m \geq \frac{4}{\epsilon}\log\frac{4}{\delta}\]VC 维度泛化界: \(\sup_{h \in H}[\mathcal{R}(h) - \hat{\mathcal{R}}_S(h)] \leq \sqrt{\frac{2d\log(em/d)}{m}} + \sqrt{\frac{\log(1/\delta)}{2m}}\)
常见误解与注意点
- 误解: “只要训练误差小,模型就好。” → 错。需要对泛化误差有概率保证。
- 误解: VC 维度越大越好。 → 错。VC 维度越大,泛化界越松(需要更多数据)。
- 误解: PAC 框架对特定分布 $D$ 做了假设。 → 错。PAC 是 distribution-free 的。
- 注意: PAC 框架假设训练集和测试集同分布(stationarity assumption)。实际中若分布漂移,理论保证失效。
- 注意: Rademacher 复杂度的界是对”所有假设同时成立”的一致收敛界,比单个假设的界更强也更难满足。