语义分析
语义分析
语义分析需要做两件事情:
- 类型检查 — 静动(when)强弱(how serious) 【在这里不涉及】
- 符号检查 — 符号:变量名、函数名、类型名、标签名…
常见错误:
- 用到了变量/函数,但是前面没有定义【为什么不在语法分析处理?—上下文相关!】
- 把变量当作函数去用
- 重复定义
SDD和SDT
语法制导定义**SDD **(Syntax-Directed Definition) 是一个上下文无关文法(CFG)和属性(Attribute)及规则(Rule)的结合。
- 每个文法符号(终结符或非终结符)都关联一组属性。
每个产生式 $A \to \alpha$ 都关联一组语义规则,用于计算该产生式中符号的属性值。
- 核心特征
- 非过程性 (Declarative):它只规定了属性之间“等于什么”,而不规定计算这些属性的具体先后顺序(只要满足依赖关系即可)。
- 属性分类:
- 综合属性 (Synthesized Attribute):在产生式 $A \to \alpha$ 中,非终结符 $A$ 的属性值是通过其子节点(即 $\alpha$ 中的符号)的属性值计算出来的。
- 继承属性 (Inherited Attribute):在产生式 $A \to \alpha$ 中,$\alpha$ 中某个符号的属性值是通过其父节点 $A$ 或其兄弟节点的属性值计算出来的。
语法制导翻译SDT (Syntax-Directed Translation) 是在其产生式体中嵌入了程序片段(称为语义动作,Semantic Actions)的上下文无关文法。
语义动作通常用花括号
{ }括起来。动作可以出现在产生式体的任何位置。
核心特征
- 过程性 (Procedural):它显式地规定了动作执行的时机。
- 实现机制:在语法分析过程中,每当分析器扫描到动作所在的位置时,就立即执行该代码片段。
- 位置敏感性:
- 后缀 SDT:所有动作都在产生式末尾。这在自底向上(LR)分析中非常容易实现。
- 中间动作:动作在产生式中间,通常用于自顶向下(LL)分析,用来向子树传递继承属性。
SDD是一种更高级、更抽象的说明书,它关心“结果是什么”;而SDT是在SDD的基础上增加了执行顺序,它将具体的语义动作(代码)嵌入到产生式中。
我们来举一个🌰
SDD阶段:建立逻辑
| 产生式 | 语义规则 (Semantic Rules) |
|---|---|
| $E \to E_1 + T$ | $E.code = E_1.code \parallel T.code \parallel ‘+’$ |
| $E \to T$ | $E.code = T.code$ |
| $T \to \text{digit}$ | $T.code = \text{digit.lexval}$ |
注:$\parallel$ 表示字符串拼接。
SDT阶段:规定时机
为了实现上面的 SDD,我们需要决定什么时候执行 print。因为逆波兰式的操作符是在操作数之后的,所以这是一个后缀 SDT(动作放在产生式最后)。
- $E \to E_1 + T \quad { \text{print(‘+’);} }$
- $E \to T$
- $T \to \text{digit} \quad { \text{print(digit.lexval);} }$
SDD是对上下文无关文法的推广
SDD = 上下文无关文法 + 属性 + 语义规则
CFG 解决了“长什么样”的问题,而 SDD 通过增加属性和规则,解决了“代表什么意思”以及“值怎么传递”的问题。
主要就是为CFG中的文法符号设置语义属性,具体来说,主要就是将一些语义属性附加到代表语言构造的文法符号上,从而把信息和语言构造联系起来
符号表 Symbol Table
定义:符号表是用于保存各种符号相关信息的数据结构
可以利用哈希表、红黑树等实现
领域特定语言DSL通常只有单作用域(全局作用域);
但是通用程序设计语言GPL通常需要嵌套作用域,那这里用一个哈希表就不够用了,我们用多个哈希表,最终呈现一个树状结构
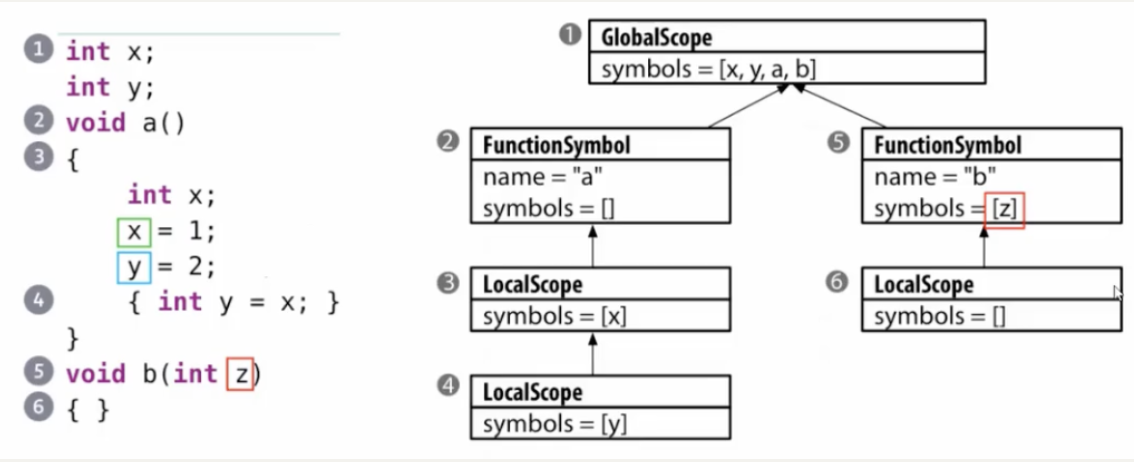
三种作用域:全局作用域、函数/方法作用域、局部作用域
1
2
3
4
5
6
public interface Scope {
public String getName(); // 有名称吗?
public Scope getEnclosingScope(); // 有外部作用域吗?
public void define(Symbol sym); // 在作用域中定义符号
public Symbol resolve(String name); // 根据名称查找
}
This post is licensed under CC BY 4.0 by the author.