卷积神经网络CNN
Image Classification
目标: 给定一张输入图片,输出对各类别的概率分布(猫、狗、树……)
关键设置:
- 所有输入图片必须是相同尺寸(例如 100×100)
- 输出是一个 one-hot 向量
ŷ:维度 = 模型能识别的类别数量 - 模型预测输出
y'是一个概率向量(经过 softmax) - 损失函数:
y'与ŷ之间的交叉熵(Cross Entropy)
计算机如何“看”一张图片
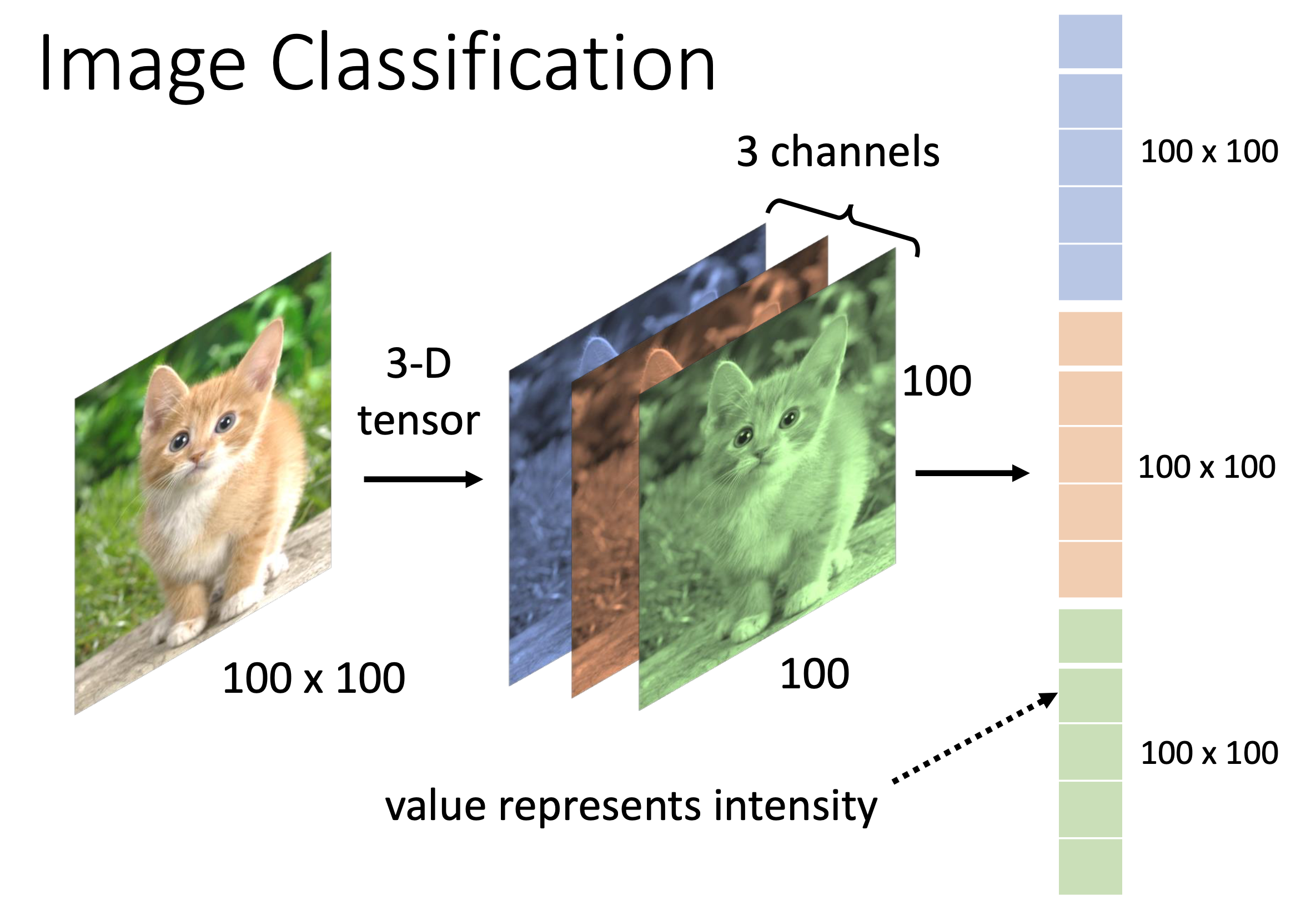
图片对计算机来说不是一个平面网格,而是一个 3D 张量(Tensor):
1
2
形状:[高度 × 宽度 × 通道数]
例如:100 × 100 × 3
- 高度 & 宽度 = 分辨率(像素数量)
- 通道数(Channel) = 颜色平面:RGB 彩色图 = 3 个通道;灰度图 = 1 个通道
- 张量中每个数值 = 像素强度(取值范围 [0, 255] 或 [0, 1])
什么是 Tensor(张量)? 是标量(0维)、向量(1维)、矩阵(2维)向更高维度的推广。3D 张量就是一个三维数值数组。
输入全连接网络前需要“拉直”
要把图片输入标准神经网络,需要将 3D 张量展平(Flatten)成 1D 向量:
1
100 × 100 × 3 = 30,000 个输入值
为什么不直接用全连接(fully connected)网络?
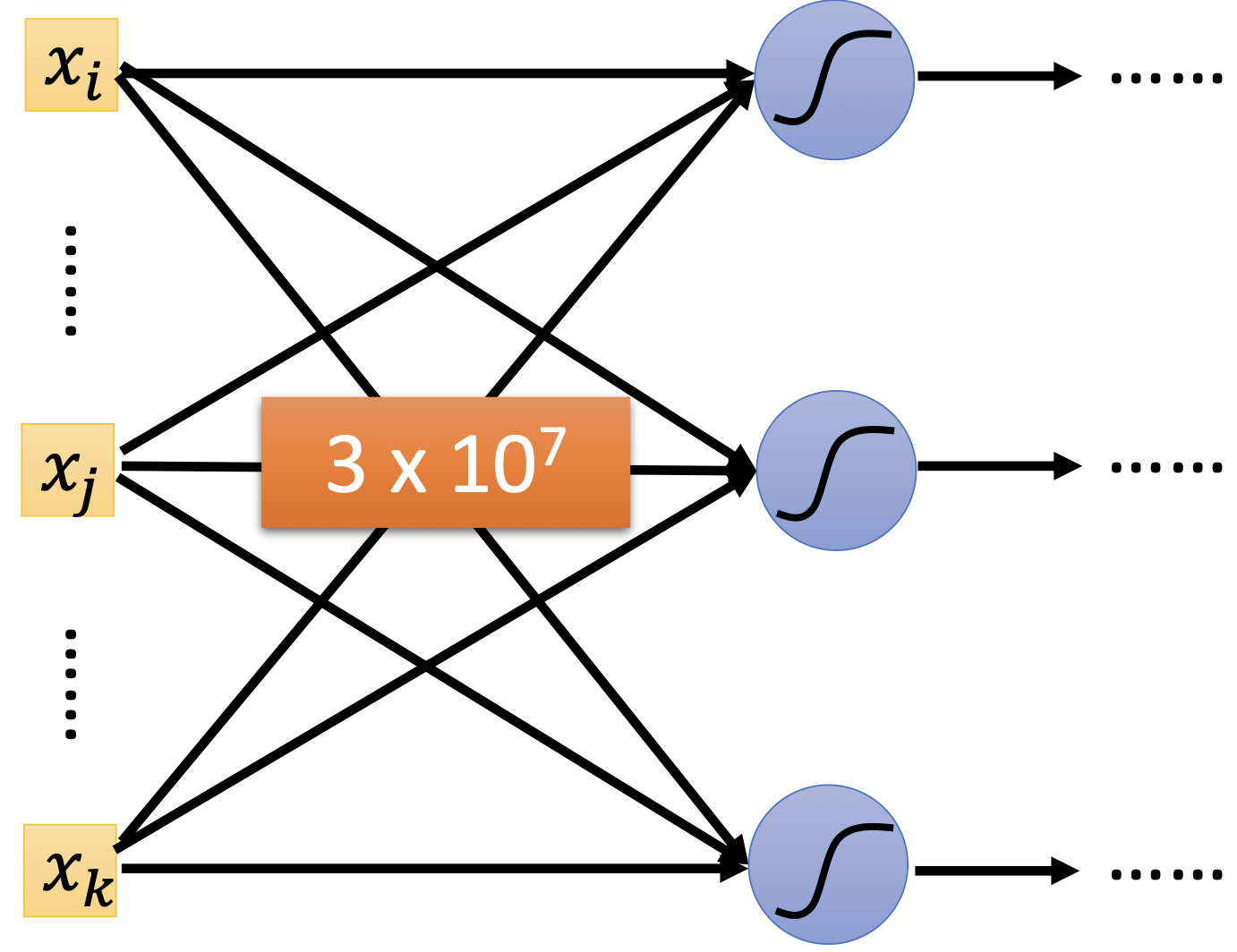
参数量爆炸。 以 100×100×3 的输入、1000 个隐藏层神经元为例:
1
参数量 = 30,000 × 1,000 = 3 × 10^7(三千万个参数)
这不仅计算量巨大,更重要的是:它完全忽略了图像本身的结构特性。
我们不妨想想,处理图像时,我们真的需要“全连接”吗?
答案是不需要。原因来自对图像的三个观察。
三个观察 → 三个设计决策
观察一:模式是局部的
- 关键特征(鸟嘴、眼睛、翅膀)远比整张图片小得多
- 一个神经元不需要看整张图,只需要看一个小的局部区域
- 浅层学习基础检测器(边缘、角点);深层学习高级检测器(鸟嘴、眼睛)
→ 设计决策:感受野(Receptive Field)— 局部连接
观察二:相同的模式会出现在不同位置
- 在左上角学到的“鸟嘴检测器”,在右下角同样适用
- 为每一个位置都单独训练一个检测器 → 极度冗余且浪费
→ 设计决策:参数共享(Parameter Sharing)
观察三:下采样不会改变物体的类别
- 把一张鸟的图片隔一个像素抽一个 → 还是能看出是鸟
- 可以对图像降采样以节省计算,同时不损失分类能力
→ 设计决策:池化(Pooling)
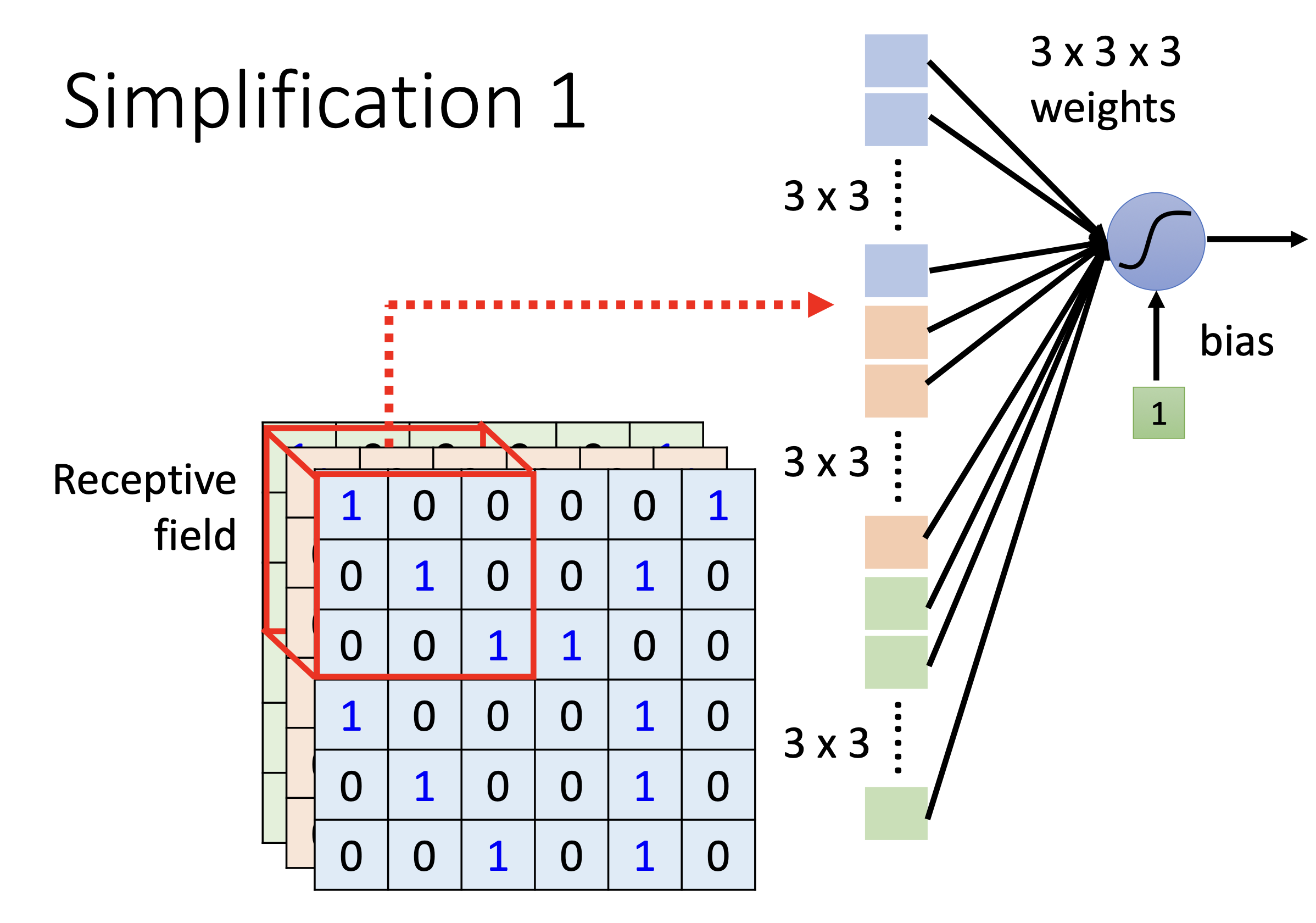
感受野(Receptive Field)
每个神经元不再连接全部 30,000 个输入,而只连接一个局部小区域。
对于fully connected network,它可以选择看全局,也可以选择只看一个小范围(把许多weight设为0即可),但是对于receptive field来说,只能看到小范围!
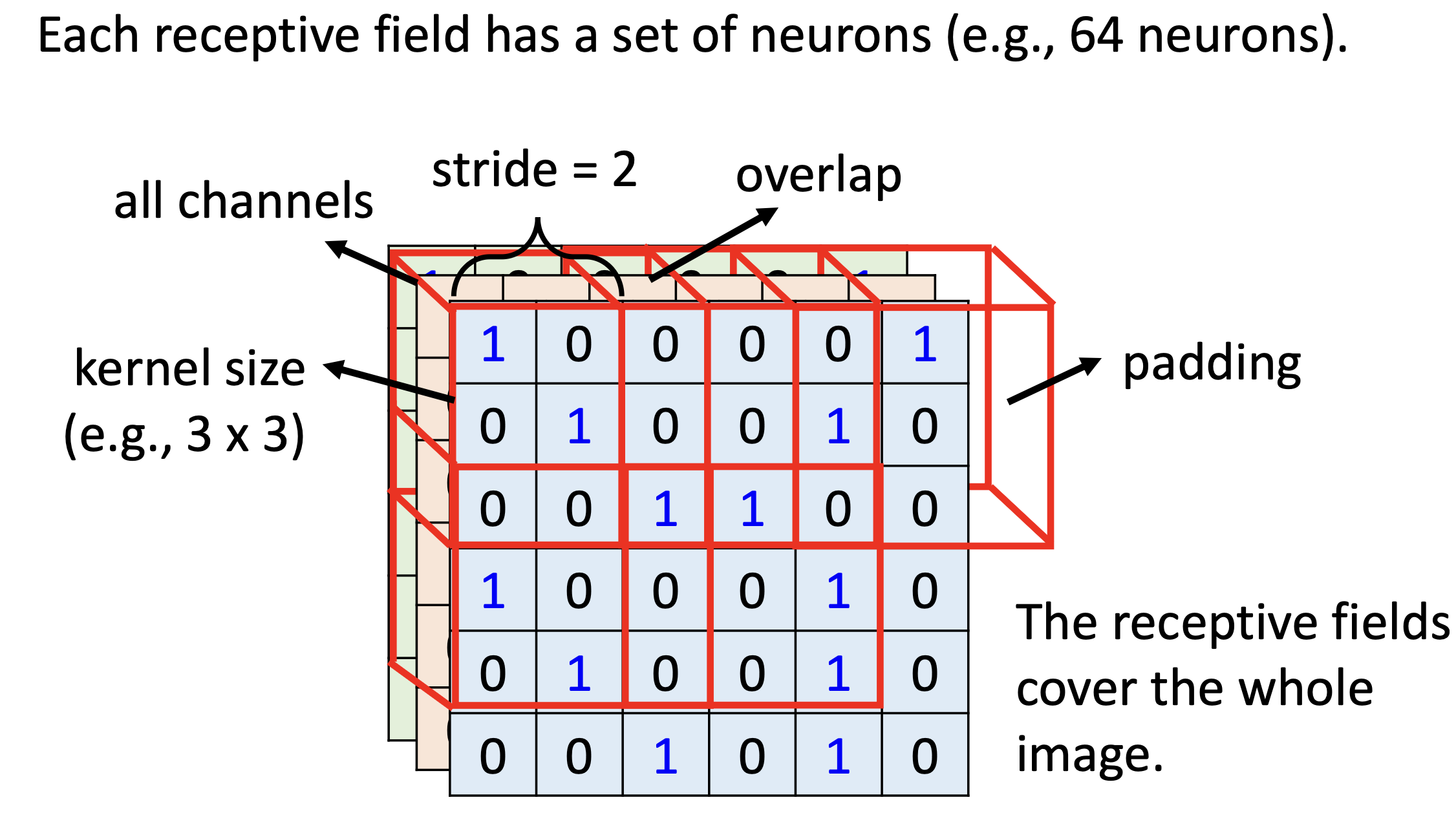
典型设置:
- 卷积核大小(Kernel size):3×3(在空间上覆盖 3×3 区域,跨越所有通道)
- 每个神经元的参数数量:3×3×C 个权重 + 1 个偏置(C = 通道数)
- 不同感受野之间相互重叠(由 stride 控制)
- 添加 Padding (补值,通常有补0、补平均,等等)使感受野能覆盖图像边缘
- Stride(步长):每次移动感受野的像素数(stride=2 → 空间尺寸减半)
注意: 同一个感受野位置上可以有多个神经元,它们使用不同的权重,检测该区域内的不同模式。
Receptive Field的设计可以完全由设计者决定,完全可以大胆发挥!
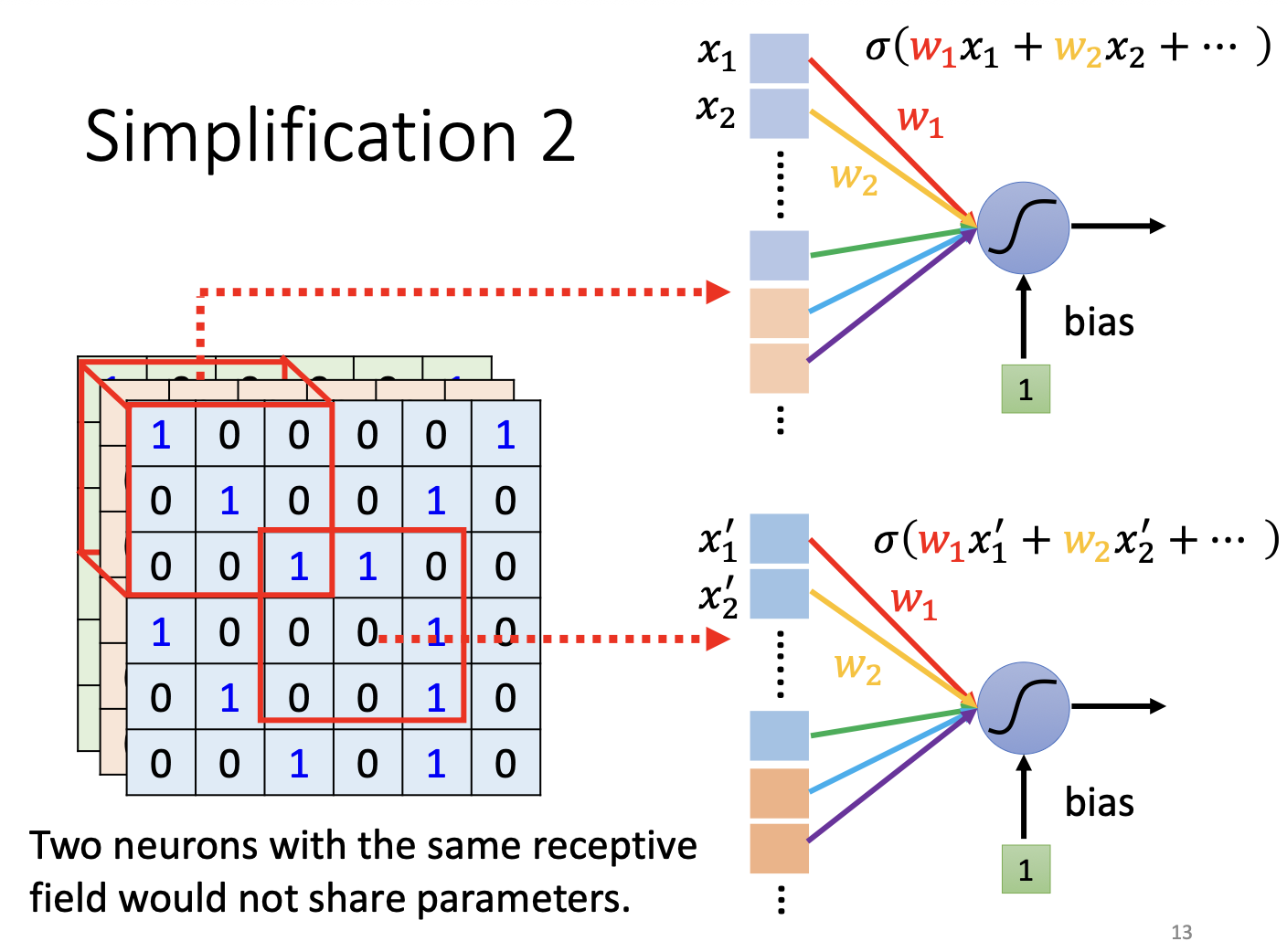
参数共享(Parameter Sharing)
核心思想: 相同的模式可以出现在图像的任意位置,因此可以在所有位置使用同一套权重(即同一个滤波器 Filter)。
- 位于不同位置、但“做同一件事”的神经元 → 共享参数
- 这就是参数共享
从操作角度来说:一个 Filter 会在整张图像上滑动(卷积)。
重要区分: 同一位置上检测不同模式的两个神经元,参数不共享 — 它们对应不同的 Filter。
典型设置:
- 每个感受野位置对应一组神经元(例如 64 个)
- 这 64 个神经元分别对应 64 个不同的 Filter
- 所有位置共用这 64 个 Filter → 参数量大幅减少
从receptive field到parameter sharing,我们不断在限制模型的弹性。CNN的弹性小,model bias就大。
卷积层(Convolutional Layer)
将Receptive Field和Parameter Sharing结合,就得到了卷积层。
理解卷积层有两种等价视角:
| 神经元视角 | 滤波器视角 |
|---|---|
| 每个神经元只看一个局部感受野 | 每个 Filter 是一个小权重张量(3×3×C) |
| 不同位置的神经元共享参数 | 每个 Filter 在整张图像上滑动 |
| → 同一个检测任务在每个位置都执行 | → 每个 Filter 输出一张“特征图” |
这两种视角描述的是完全相同的操作 — 只是两种理解方式。
具体计算过程(以灰度图 C=1 为例)
给定一张 6×6 的图像和若干滤波器(如课件中的 Filter 1、Filter 2),每个 Filter 以 stride=1 在图像上滑动,在每个位置计算点积,输出一张特征图(Feature Map)(6×6 输入 + 3×3 卷积核 + stride=1 + 无 padding → 4×4 输出)。
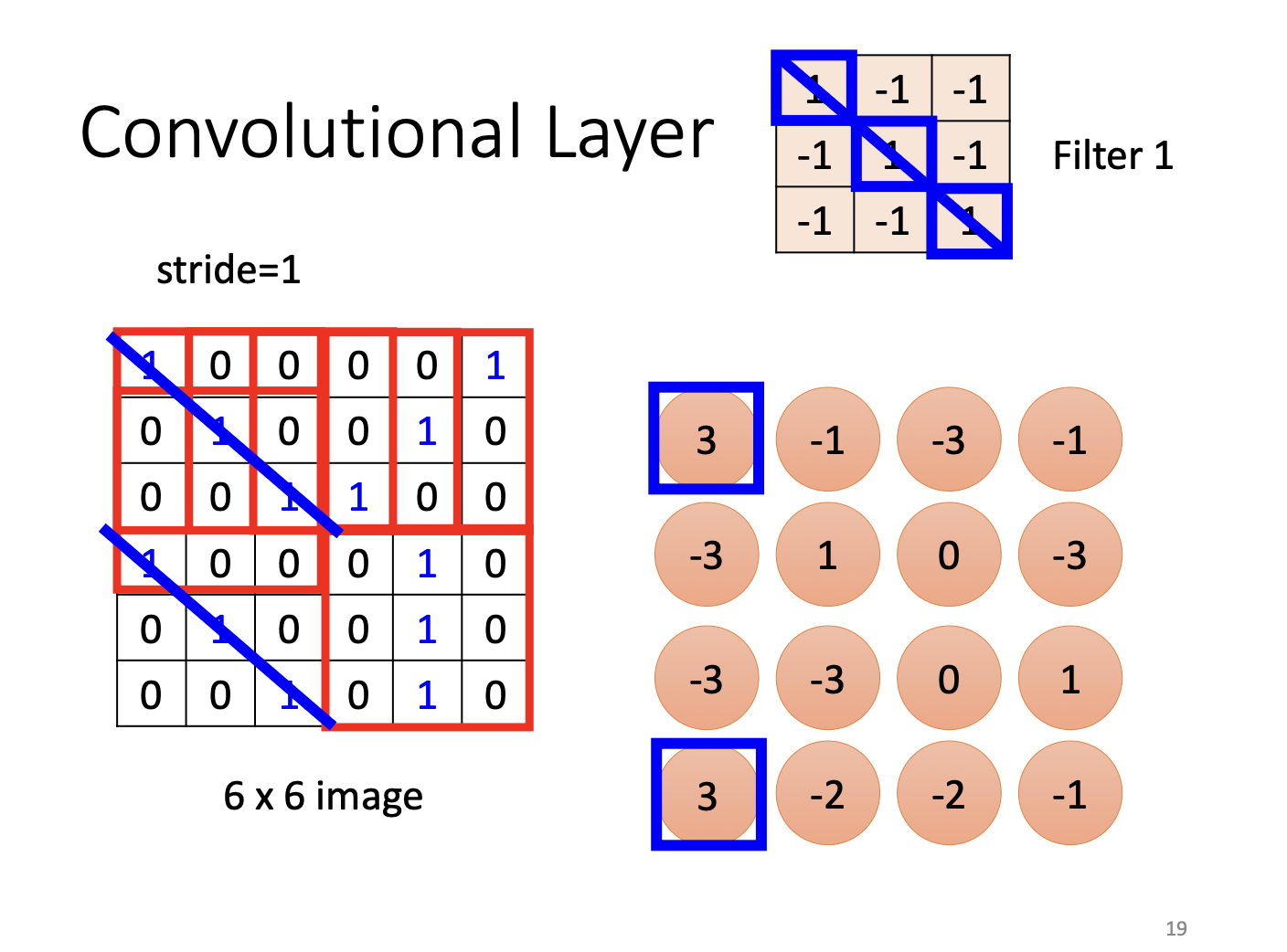
卷积层的输出:
- 若有 64 个 Filter,输出就是一个带有 64 个通道的“图像”(每个 Filter 对应一个通道)
- 空间尺寸略有缩小(或加 padding 保持不变)
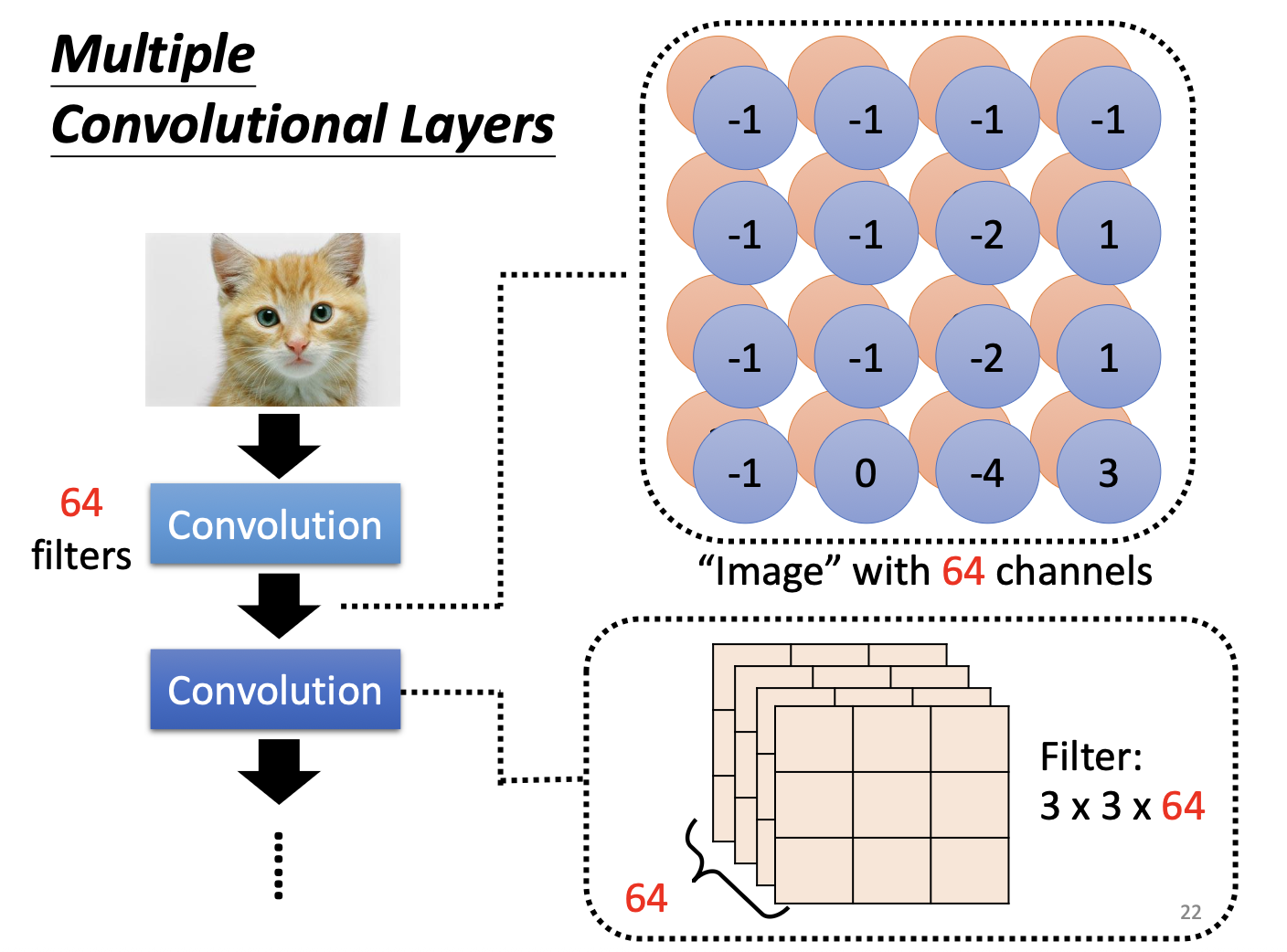
多层卷积叠加
第一层输出(64 通道)作为第二层的输入:
- 第二层的 Filter 形状变为 3×3×64(跨越全部 64 个通道)
- 深层 Filter 可以检测低层特征的组合模式
- 第 1 层:检测边缘 → 第 2 层:检测角点、曲线 → 第 3 层+:检测眼睛、嘴巴……
无需担心 3×3 的 Filter 只能检测小范围的模式。 虽然每个 Filter 的尺寸只有 3×3,但 CNN 通常由多个卷积层叠加而成。第二层的输入是第一层的输出特征图,而特征图中的每一个值,都已经融合了原图上一个 3×3 区域的信息。因此,第二层的 3×3 Filter 实际上”看到”的是原图上一个 5×5 的区域。层数越深,有效感受野(Effective Receptive Field) 就越大,深层神经元最终可以捕捉到图像中的大范围模式。
顺便补充一个有用的规律:每多叠一层 3×3 卷积(stride=1),有效感受野就在每个方向上扩大 2 个像素,即 每层 +2,k 层后有效感受野为
(2k+1) × (2k+1)。这也是为什么现代网络(如 VGG)倾向于用多个小 Filter 叠加,而非直接用一个大 Filter。
池化(Pooling)— 最大池化(Max Pooling)
Pooling是没有需要学习的东西的(更像sigmoid、ReLu那种activation function)
动机: 对图像进行下采样,不会改变它代表的物体类别。
最大池化操作:
- 取一个 2×2 区域 → 输出其中的最大值
- 空间尺寸减半
- 通道数不变(池化对每个通道独立进行)
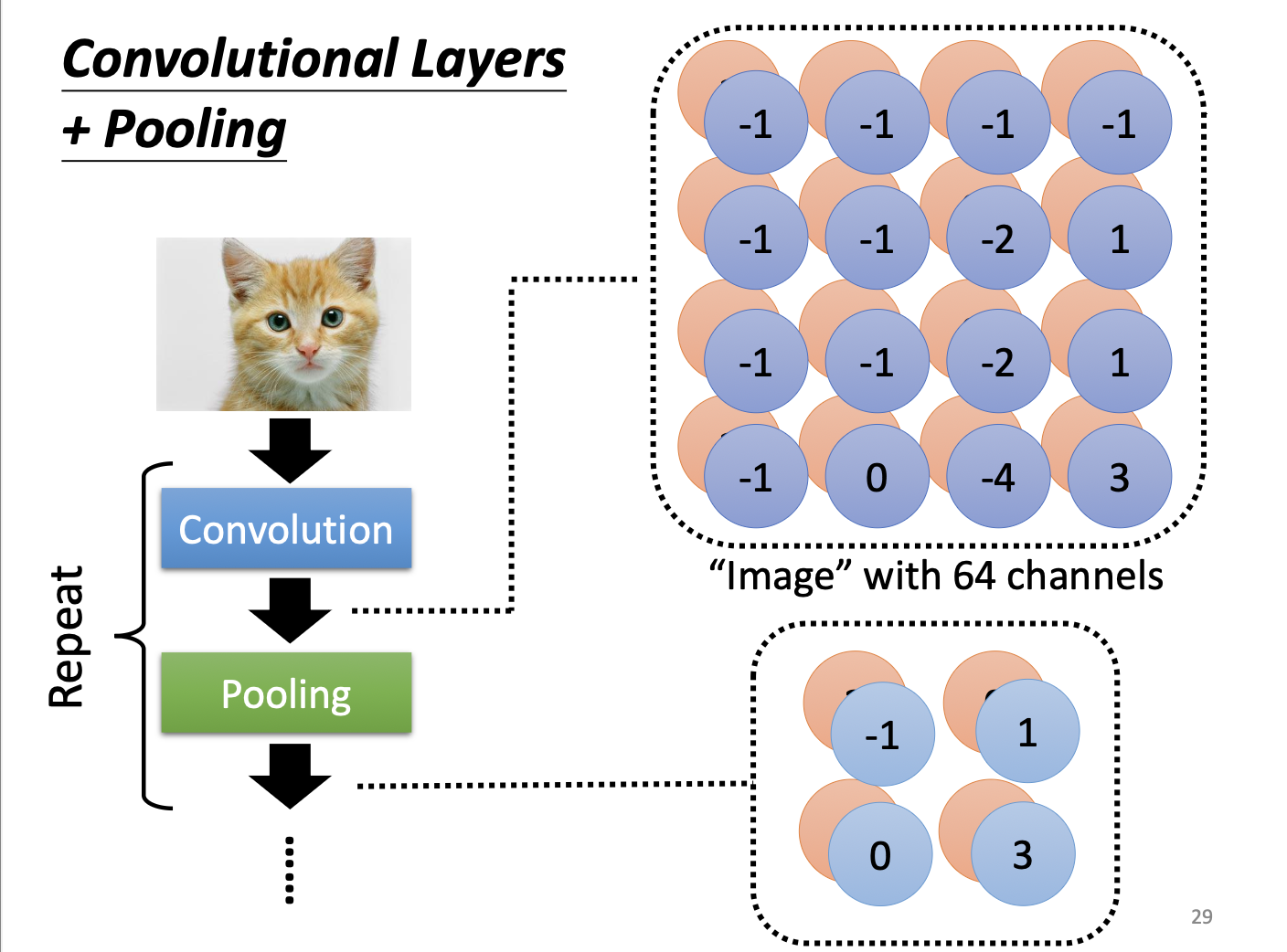
示例:
1
2
3
4
5
输入(4×4): 经过 2×2 最大池化后:
3 -1 -3 -1
-3 1 0 -3 → 3 0
-3 -3 0 1 3 1
3 -2 -2 -1
池化的作用:
- 减小空间尺寸 → 后续层参数量减少
- 引入一定的平移不变性(小范围的位置偏移不影响最大值)
- 提升计算效率
注意: 池化是一种启发式的工程选择,并非数学上必须的。现代网络有时会跳过池化,因为计算能力越来越强了(例如 AlphaGo 就不使用池化)。
完整的 CNN 架构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
输入图像(H × W × 3)
↓
卷积层(学习各种 Filter)
↓
池化层(降采样)
↓
卷积层(提取更深层特征)
↓
池化层
↓
......
↓
Flatten(3D → 1D 向量,即把向量拉直成一个向量)
↓
全连接层(Fully Connected)
↓
Softmax
↓
输出:各类别概率
卷积层负责提取特征;末尾的全连接层负责最终的分类决策。
核心视角:CNN = 加了约束的全连接网络
CNN 不是一种全新的网络结构 — 它本质上是一个施加了两个约束的全连接网络:
- 局部连接(感受野)→ 每个神经元只连接局部小区域
- 参数共享 → 不同位置的神经元使用相同的权重
这两个约束大幅减少了参数量,并向模型注入了图像领域特有的归纳偏置(Inductive Bias)。
权衡: 更强的模型偏置(对数据结构做了更强的假设)→ 灵活性降低,但在图像任务上泛化能力大幅提升。全连接网络对图像来说是”样样都会,样样稀松”。
应用案例:AlphaGo 与 CNN 在图像之外的应用
为何把棋盘当作图像处理?
- 棋盘是一个 19×19 的矩阵(结构与灰度图完全相同)
- AlphaGo 使用 48 个通道(编码气、提子、历史落子等信息)
- 输入张量:19×19×48
CNN 为何适用于围棋?
- 观察一成立: 局部棋形(如“接触”、“征子”)是关键且局部的
- 观察二成立: 左上角的棋形和右下角的同一棋形,战略意义完全相同
- AlphaGo 第一层使用 5×5 的 Filter(感受野比常规图像 CNN 略大)
AlphaGo 为何不使用池化?
- 观察三对围棋不成立: 对棋盘进行下采样会破坏信息(每个交叉点都至关重要)
- 棋盘没有空间冗余 — 你不能对棋盘降采样后还正常下棋
- 重要启示:三个观察并不总是同时成立,需要根据具体任务判断哪些组件适用、哪些应当舍弃。
这是一个很好的例子:理解归纳偏置的适用条件,而不是盲目套用架构。
其他领域的应用
CNN 的两个核心特性(局部模式 + 平移不变性)可以推广到二维图像之外:
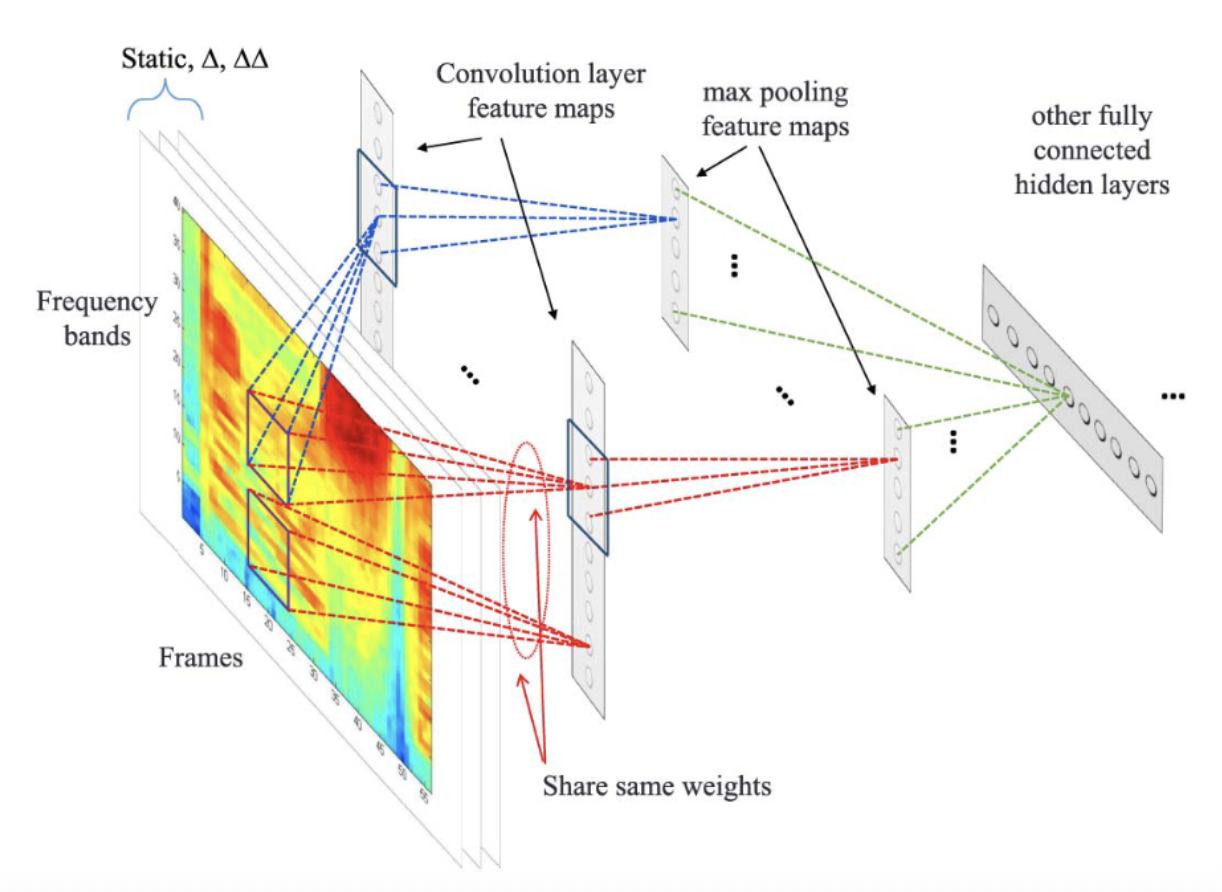
语音识别: 将语谱图(频率 × 时间)视为二维图像处理;频率模式在时间轴上重复出现 → 沿时间轴进行参数共享
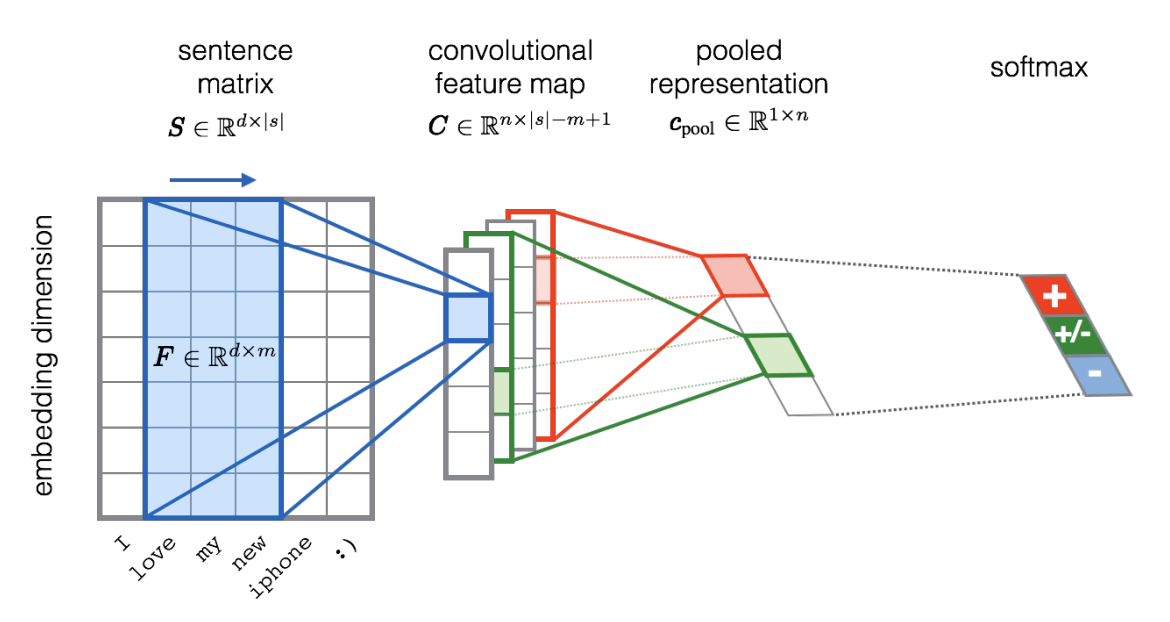
自然语言处理(文本分类): 将词向量叠成矩阵;用一维卷积检测局部的 n-gram 模式
ref:UNITN: Training Deep Convolutional Neural Network for Twitter Sentiment Classification
CNN 的局限性
| 局限 | 说明 |
|---|---|
| 对缩放和旋转不具备不变性 | 旋转 45° 的猫可能无法被识别;需要数据增强(Data Augmentation) |
| 感受野大小固定 | 难以同时捕捉非常局部和非常全局的模式 |
| 池化会丢失位置信息 | Max Pooling 只保留“有没有”,丢失了“在哪里”(Capsule Network 尝试解决此问题) |
| 依赖空间局部性假设 | 如果任务本身不具备局部结构,CNN 的归纳偏置反而有害 |
对缩放/旋转问题的解决方案:
- 工程方案:数据增强(展示经过翻转、旋转、缩放的样本)
- 更本质的方案:Spatial Transformer Network(可学习的几何变换层)