中间代码生成
中间代码生成
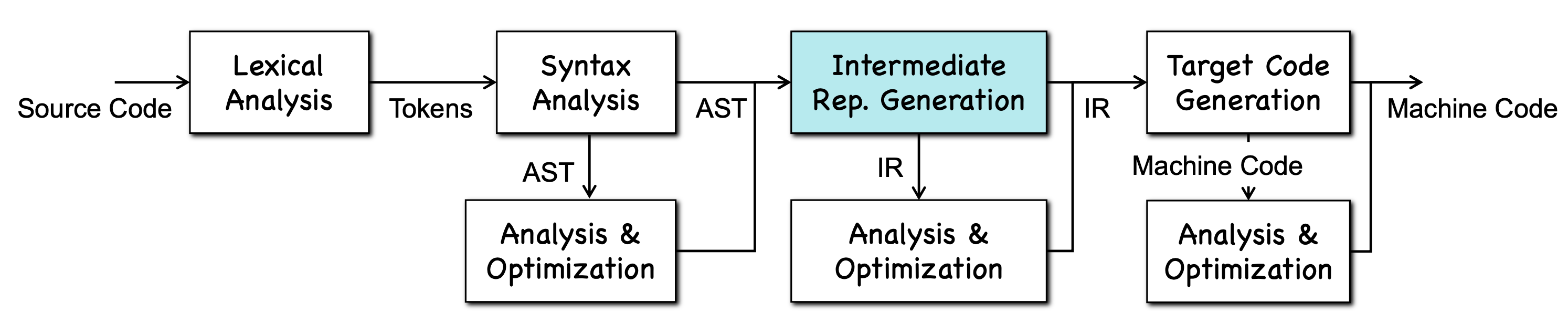
中间代码表示
中间表示(Intermediate Representation, IR):编译器在前端与后端之间使用的、与具体源语言和目标机器都相对独立的程序表示形式,用于承载程序语义、驱动优化,并作为目标代码生成的输入
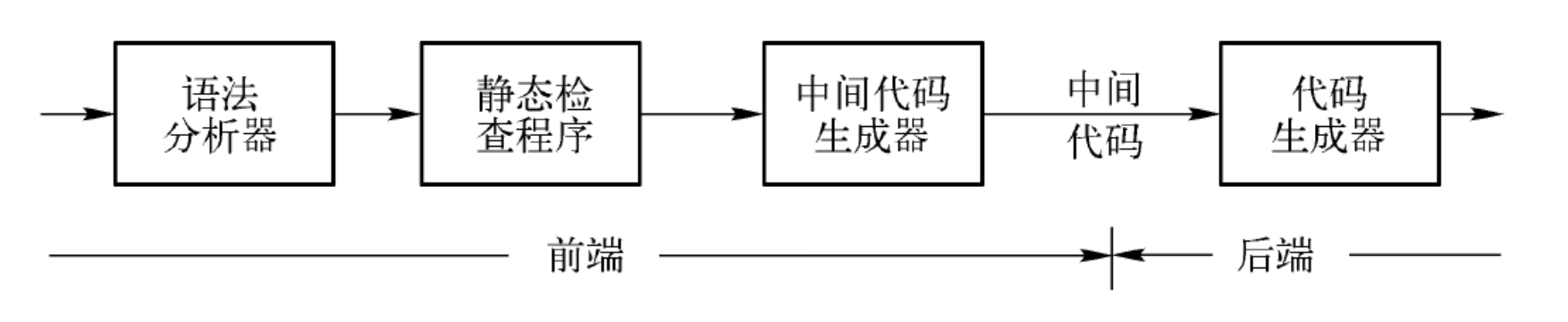
前端对源程序进行分析并产生中间表示,后端在此基础上生成目标代码
为什么需要IR?
- 解耦与可移植性:同一前端可面向多个后端;同一后端可复用多个前端
- 优化平台:大多数中端优化都在IR层进行(如常量传播、死代码删除、循环优化)
- 简化实现:比AST更接近机器,比汇编更抽象,便于规则化生成与分析
- 跨语言统一:多语言编译到统一IR,复用优化与后端(如LLVM IR)
常见IR范式与代表
- 树形IR:抽象语法树(AST)、语法树-语义注释
- 适合“早期”高层变换,不适合低层优化
- 三地址码(TAC):x = y op z;if x goto L;param x;call f, n;return x
- 表示方式:四元式(op, arg1, arg2, result)、三元式(op, arg1, arg2)
- SSA(静态单赋值)形态的IR:在TAC基础上引入Φ函数
- 优化友好:简化数据流问题,如活跃性、可用表达式、冗余消除
- 堆栈式IR:操作数隐含在栈上(如JVM字节码)
- 简单、紧凑,但数据依赖不显式,部分优化不便
- LLVM IR/Sea-of-Nodes 等工业IR
三地址码
三地址码是一种常见的中间表示形式,它将源程序转换为一系列简单的指令,每条指令最多涉及三个“地址”(操作数或结果),典型格式为:
\[result \space=\space arg1\space\space op\space\space arg2\]静态单赋值
静态单赋值形式(Static Single Assignment,SSA)是编译器设计中用于优化的中间表示形式,其核心规则要求每个变量仅被赋值一次,通过添加下标区分变量不同版本
使用SSA可以很容易地发现一些可优化项,如死代码优化、常量传播等
SSA中的所有赋值都是针对不同名的变量,对于同一个变量在不同路径中定值的情况,可以使用φ函数来合并不同的定值,如:
1
2
3
4
5
if (flag)
x = -1;
else
x = 1;
y = x*a
改写为:
1
2
3
4
5
6
if (flag)
x1 = -1;
else
x2 = 1;
x3=φ(x1,x2);
y = x3*a
φ 函数
- 数学意义:一个“多路选择器”(类似 switch)
- 语义:在控制流合流点,根据 控制路径 决定选哪个值
- $x_{n+1} = \phi(x_1, x_2, \dots, x_n)$
- φ 不是 CPU 指令,而是编译器 IR 的“抽象伪指令”。在生成汇编代码时,必须把它消除(φ-elimination)
代码层实现策略
- 插入并行赋值(idealized semantics):在 IR 层面,可以把 φ 看作所有赋值同时发生
- 寄存器重命名 / 移动指令:在真实机器代码生成时,常见做法是在合流点前,插入 move 指令,保证合流点有正确的版本

类型和声明
类型检查
静态:编译期完成(C、Java 强类型系统)
动态:运行期完成(Python、JavaScript)
声明
如何管理局部变量名的存储布局?
变量的类型可以确定变量需要的内存 — 可变大小的数据结构只需要考虑指针
| 变量类型 | 内存大小是否固定 | 存储位置 | 例子 |
|---|---|---|---|
| 基本类型 | 是(编译时已知) | 栈(通常) | int, double, bool |
| 可变大小数据结构 | 否 | 堆上数据 + 栈上指针 | string, slice, array |
函数的局部变量总是分配在连续的区间
因此给每个变量分配一个相对于这个区间开始处的相对地址
变量的类型信息保存在符号表中
如何计算类型和宽度的SDT?
综合属性:type, width
1
2
3
E → E1 + E2
E.type = 类型合并(E1.type, E2.type)
E.width = 根据E.type查表
举个🌰,考虑:
\[\begin{array}{r@{\;}l@{\qquad}l} T & \to B & \{ t = B.\text{type};\ w = B.\text{width}; \} \\ & & \{ T.\text{type} = C.\text{type};\ T.\text{width} = C.\text{width} \} \\[6pt] B & \to \text{int} & \{ B.\text{type} = \text{integer};\ B.\text{width} = 4; \} \\[4pt] B & \to \text{float} & \{ B.\text{type} = \text{float};\ B.\text{width} = 8; \} \\[6pt] C & \to \varepsilon & \{ C.\text{type} = t;\ C.\text{width} = w; \} \\[6pt] C & \to [\ \text{num}\ ]\ C_1 & \{ C.\text{type} = \text{array}(\text{num}.\text{value}, C_1.\text{type}); \\ & & \qquad C.\text{width} = \text{num}.\text{value} \times C_1.\text{width}; \} \end{array}\]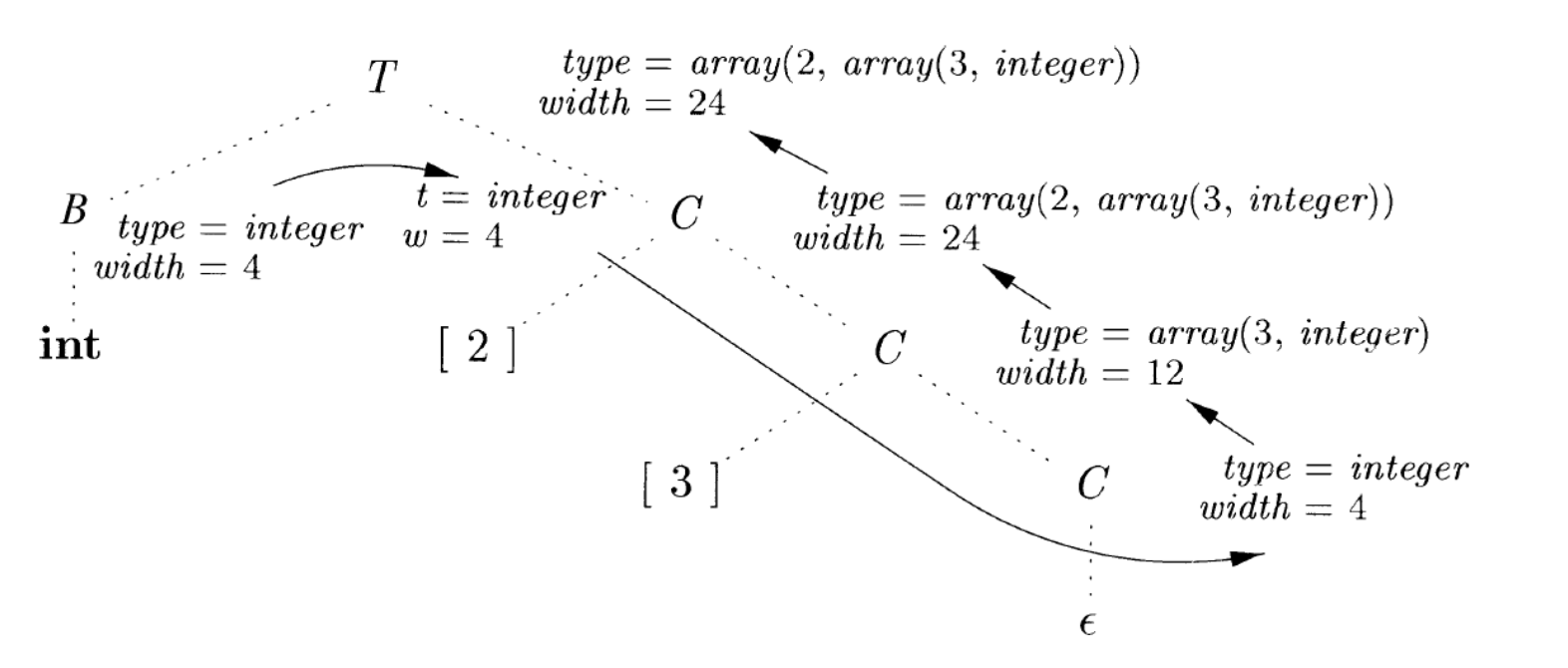
除了确定类型和类型宽度,还有什么语义需要处理?
符号表中的位置!
- 在处理一个过程/函数时,局部变量应该放到单独的符号表中去,这些变量的内存布局独立
- 相对地址从0开始
- 假设变量的放置和声明的顺序相同
- SDT的处理方法:变量offset记录当前可用的相对地址,每“分配”一个变量,offset的值增加相应的值
- top.put(id.lexeme, T.type, offset):在当前符号表(位于栈顶)中创建符号表条目,记录标识符的类型,偏移量
可以把offset看作D的继承属性
- D.offset表示D中第一个变量的相对地址
- P→ {D.offset =0} D
- D → T id; {D1.offset = D.offset + T.width;} D1
如何处理记录字段?
如何处理表达式
将表达式翻译成三地址指令序列
表达式的SDD:
- 属性code表示代码
- addr表示存放表达式结果的地址(临时变量)
- new Temp()可以生成一个临时变量
- gen(…)生成一个指令

必考:翻译if-else和while
需要将语句的翻译和布尔表达式的翻译结合在一起
布尔表达式是被用作语句中改变控制流的条件表达式,通常用来
- 改变控制流。布尔表达式的值由程序到达的某个位置隐含地指出。
- 计算逻辑值。可以使用带有逻辑运算符的三地址指令进行求值。
布尔表达式的使用意图要根据其语法上下文确定
- 跟在关键字if后面的表达式用来改变控制流
- 一个赋值语句右部的表达式用来计算一个逻辑值
- 可以使用两个不同的非终结符号或其它方法来区分这两种使用
短路求值:
This post is licensed under CC BY 4.0 by the author.