Self-attention
解决的问题:network的input一直是一个向量,输出可能是一个数值(regression)或者一个类别(classification),那么,如果输入长度是一个sequence,而且长度不一样呢
例子:文字处理
输入是句子,把每一个词汇看成一个向量,句子里词汇的长度不一样
怎么看成向量?
One-hot Encoding:开一个很长很长的向量,向量的长度和世界上存在的词汇的数目是一样多的,但是它假设所有的词汇之间是没有关系的,这个向量就失去了语义信息
Word Embedding:给每一个词汇一个向量,包含语义资讯
// TODO :怎么做到的
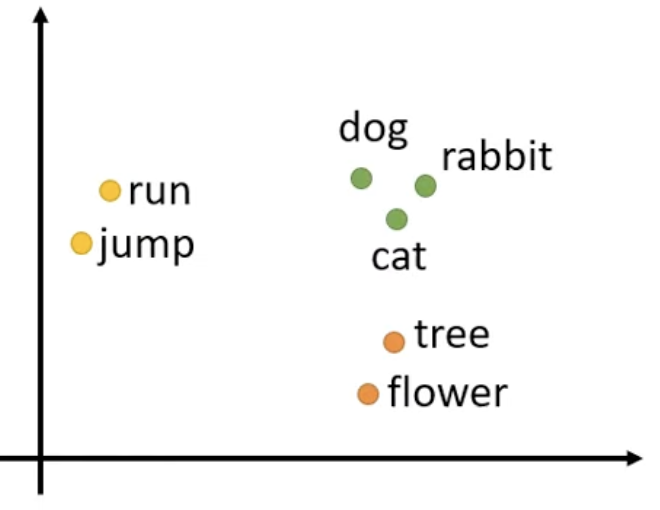
输出
情况1:n个输入,n个输出 — 例子:词性分析
情况2:n个输入,1个输出 — 例子:情绪极性分析
情况3(seq2seq):不定个输出 — 例子:翻译
我们聚焦于情况1,又称为Sequence Labeling
以词性分析举例,如果采用各个击破的方式,对于句子I saw a saw,他就没有理由把第二个saw看成名词“锯子”;于是我们可以给fc的network一个窗口的资讯,这样就知道他的前后的词语的信息。
但是这样仍然有局限,如果有些任务必须要考虑整个sequence才能解决呢?开一个比最大的sequence还要大的window会出现诸多问题,如:需要非常多参数,运算量大,可能会overfitting
self-attention
本质:对于输入序列中的每个元素,计算它与序列中所有元素的相关性,然后基于这些相关性加权聚合所有元素的信息
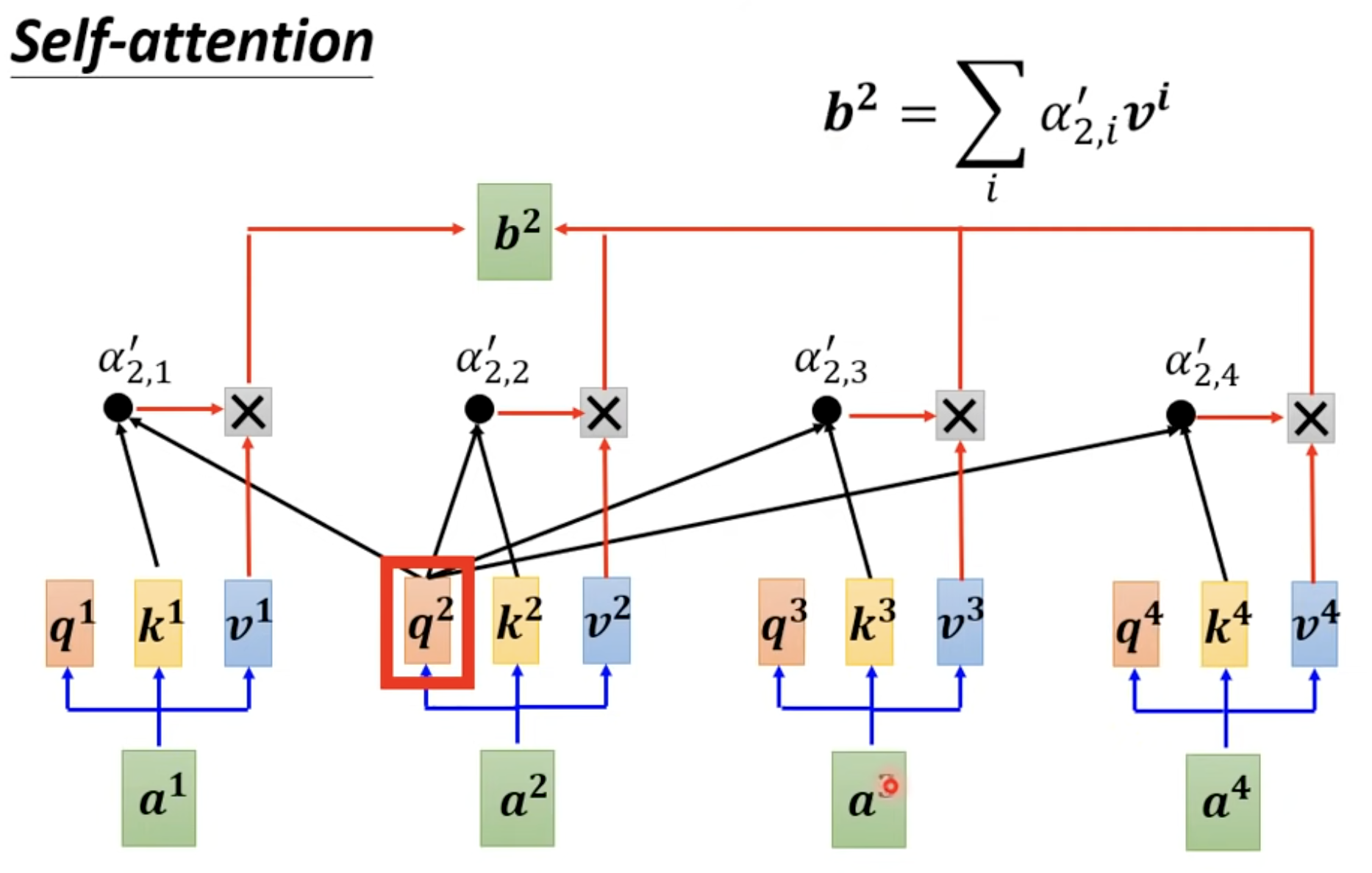
运作方式:吃一整个sequence的资讯,我input几个vector,就output几个vector,而这几个vector都是考虑整个sequence才输出的,再把这几个资讯丢进fully connected的network,再来决定说他应该是什么样的东西
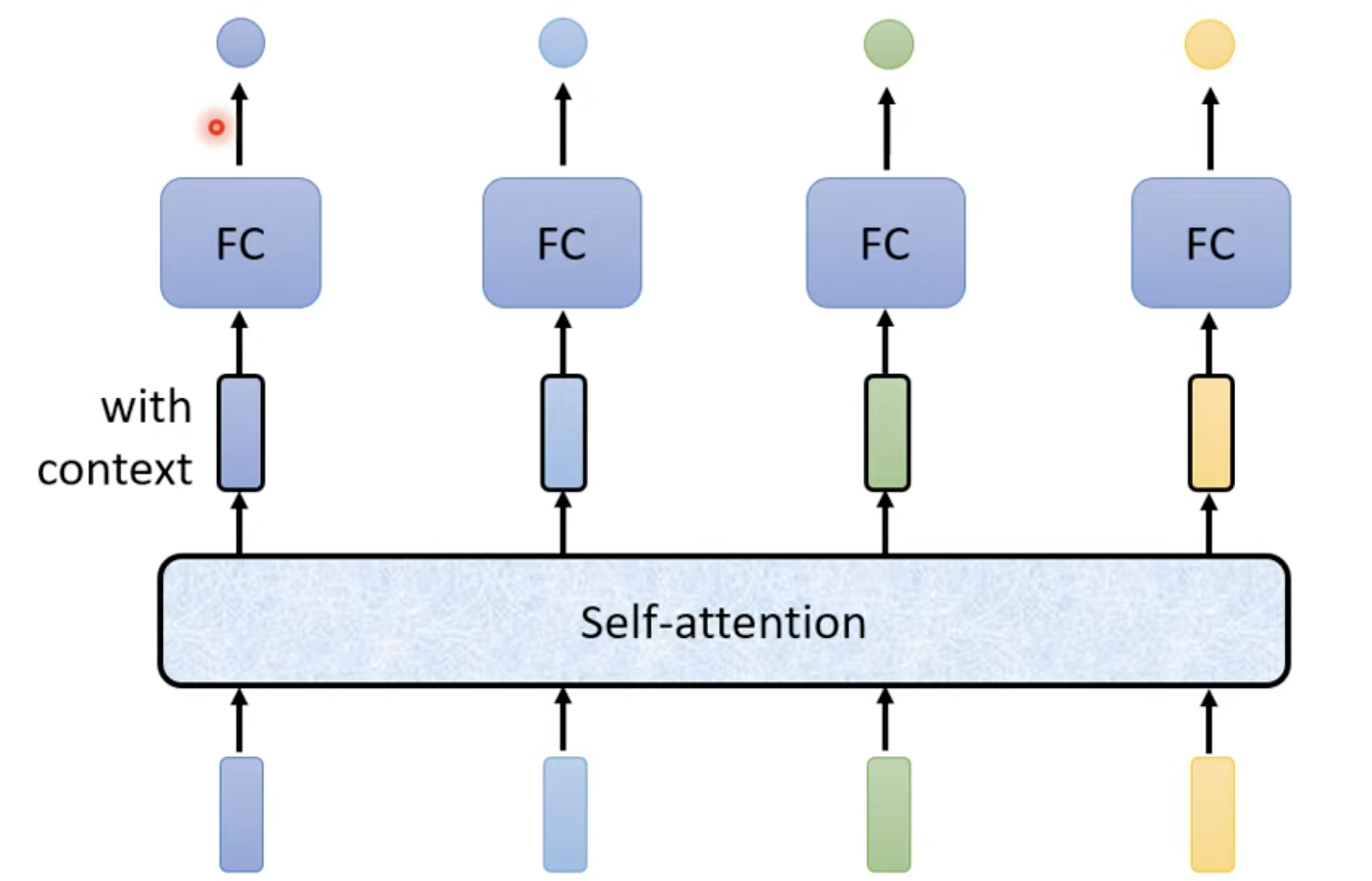
当然,self-attention可以叠加很多次
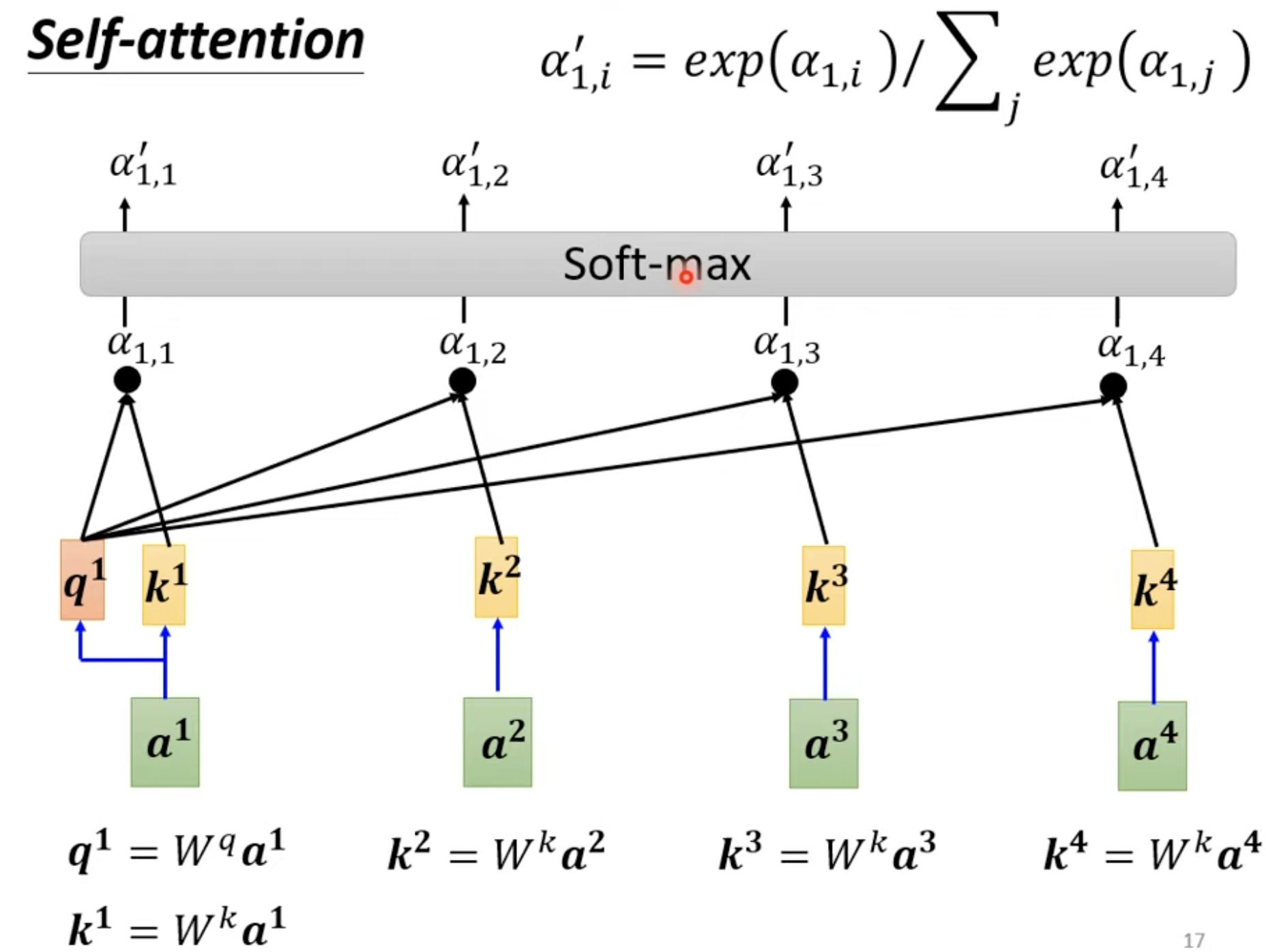
关联度
两个向量作为输入,输出两个向量的关联度alpha
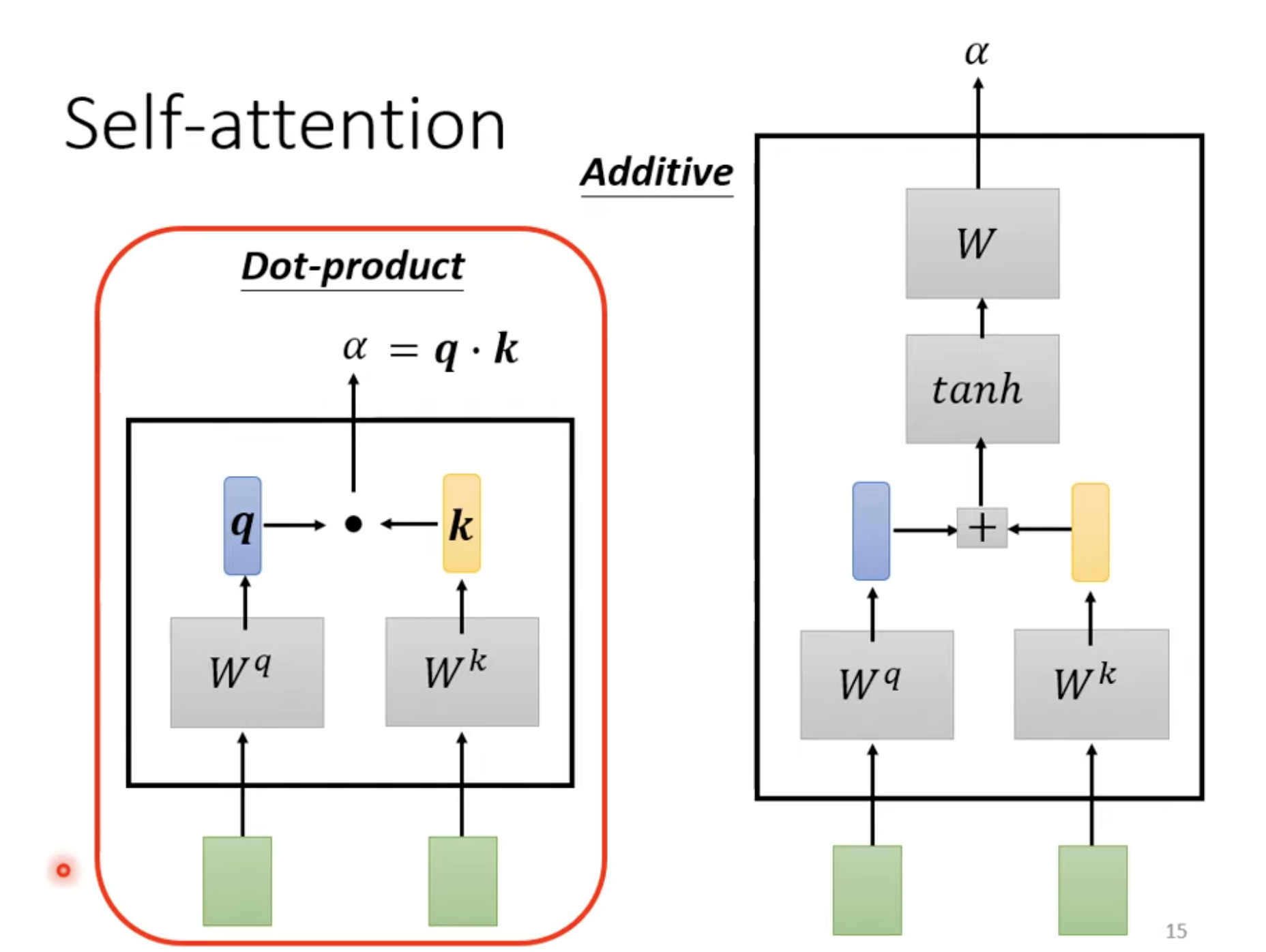
Dot-product
把输入的两个向量分别乘上两个不同的矩阵,得到q和k两个向量,alpha就等于q·k
自己和自己计算关联性重要吗?为什么?
运作机制
模型为每个输入向量(比如一个单词的 Embedding)生成了三个不同的向量:
- Query (查询项 - $Q$):意为“我正在寻找什么?”
- Key (键值项 - $K$):意为“我能提供什么信息?”
- Value (数值项 - $V$):意为“我实际包含的信息内容。”
可以理解成:
1
2
Query 去匹配 Key
匹配成功后,取对应 Value
假设我们要处理一句话:“The cat sat on the mat”。当模型处理到 “sat” 这个词时,Self-attention 是这样工作的:
1. 生成向量
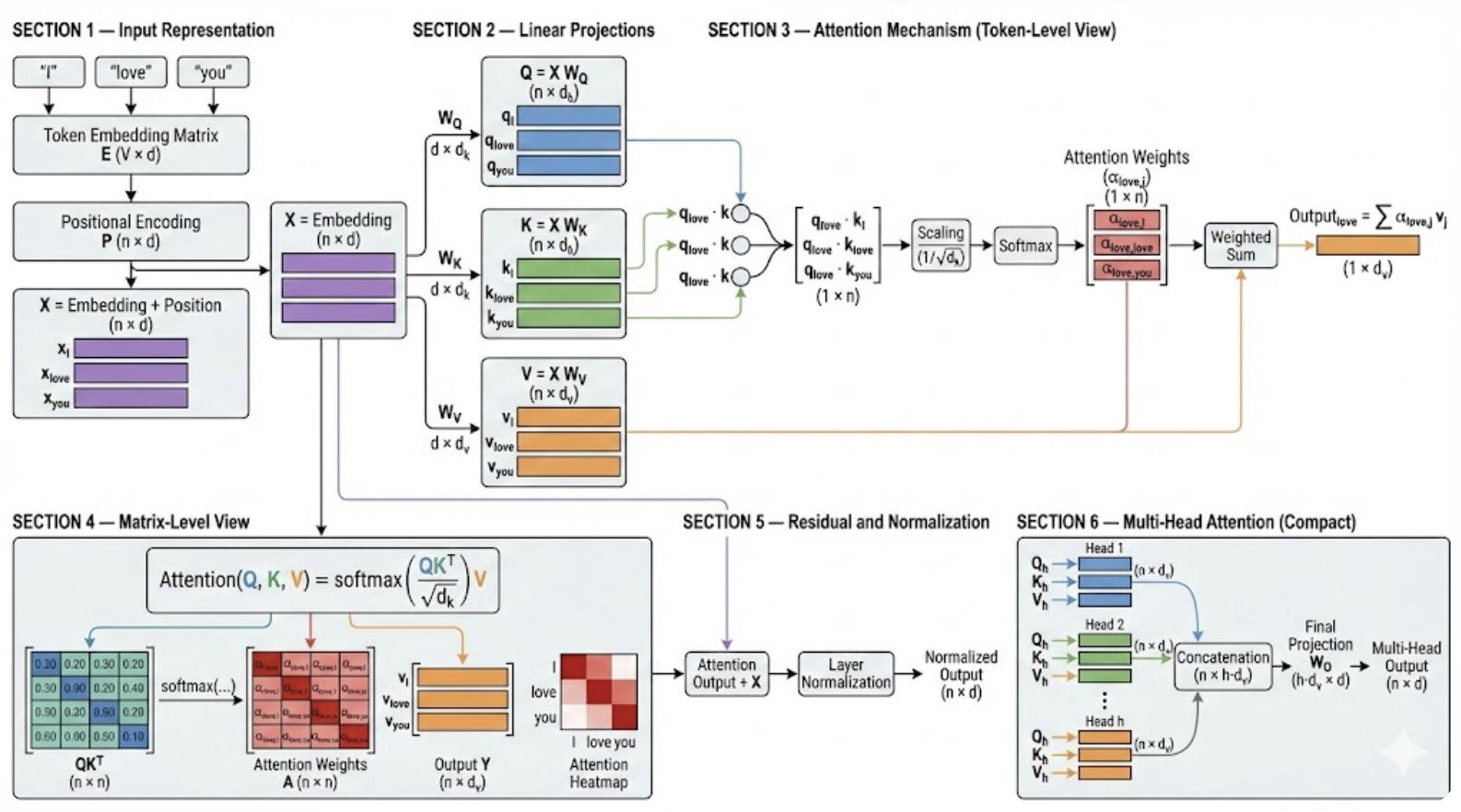
通过三个可学习的权重矩阵 $W^Q, W^K, W^V$,将输入的词向量转换成对应的 $Q, K, V$。
2. 计算打分 (Scores)
将当前词的 $Q$ 与序列中所有词的 $K$ 进行点积(Dot Product)。
直观理解:点积越大,说明两个向量越相似,当前词对那个词的“关注度”就越高。
3. 缩放 (Scaling)
为了防止点积数值过大导致梯度消失,我们会除以一个缩放因子(通常是 $\sqrt{d_k}$,即 Key 向量维度的平方根)。
4. 归一化 (Softmax)
通过 Softmax 函数将分数转换成概率分布(总和为 1)。这决定了在处理当前词时,每个单词所占的“权重”。
5. 加权求和 (Weighted Sum)
将上一步得到的权重乘以对应的 $Value (V)$,并累加起来。
结果:这一步产生的输出向量,不仅包含了当前词的信息,还融合了上下文中所有重要的信息。
用一个简单的图例表示,就是这样的:
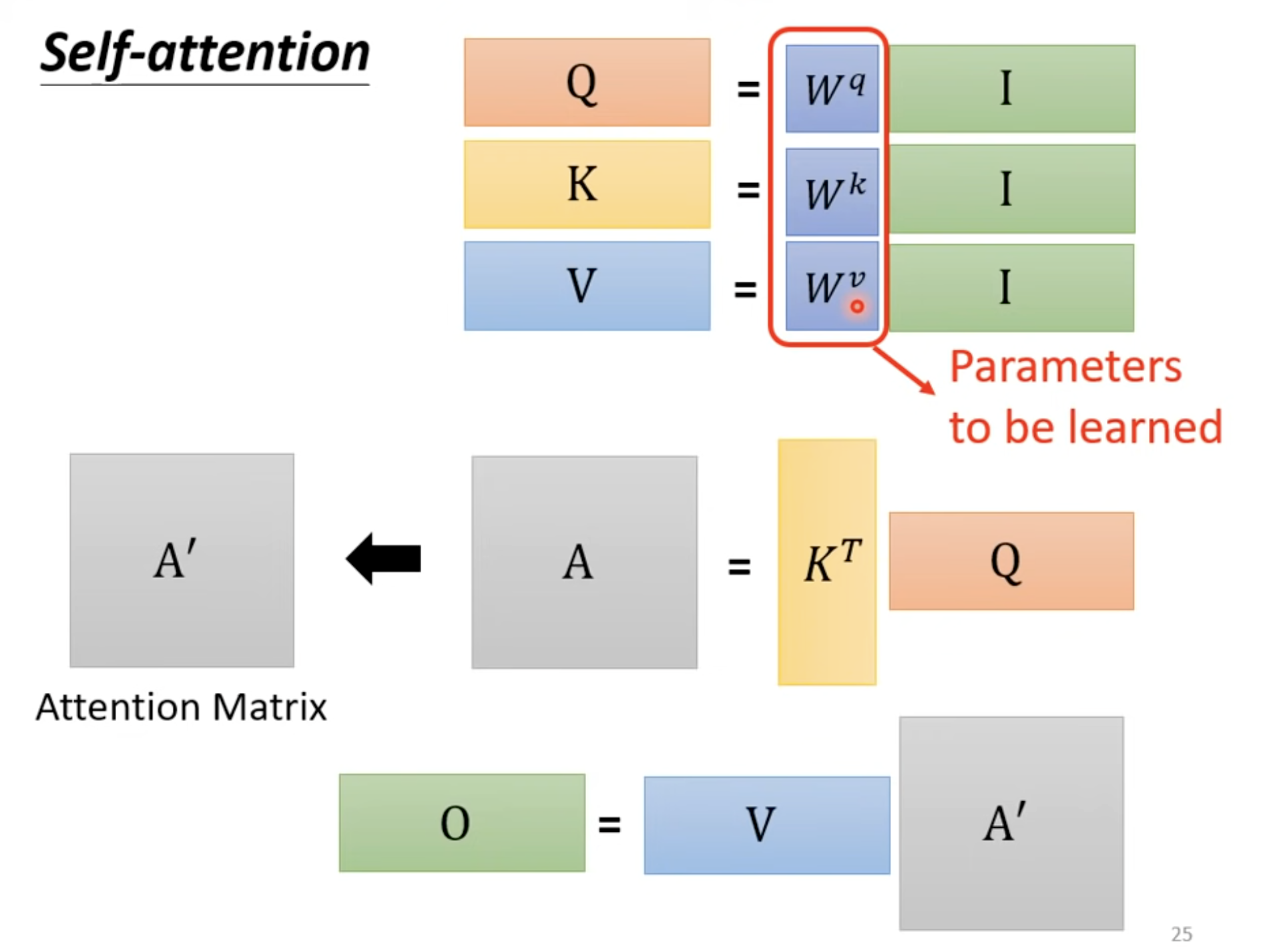
而这个过程可以总结为一个公式: \(\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\)
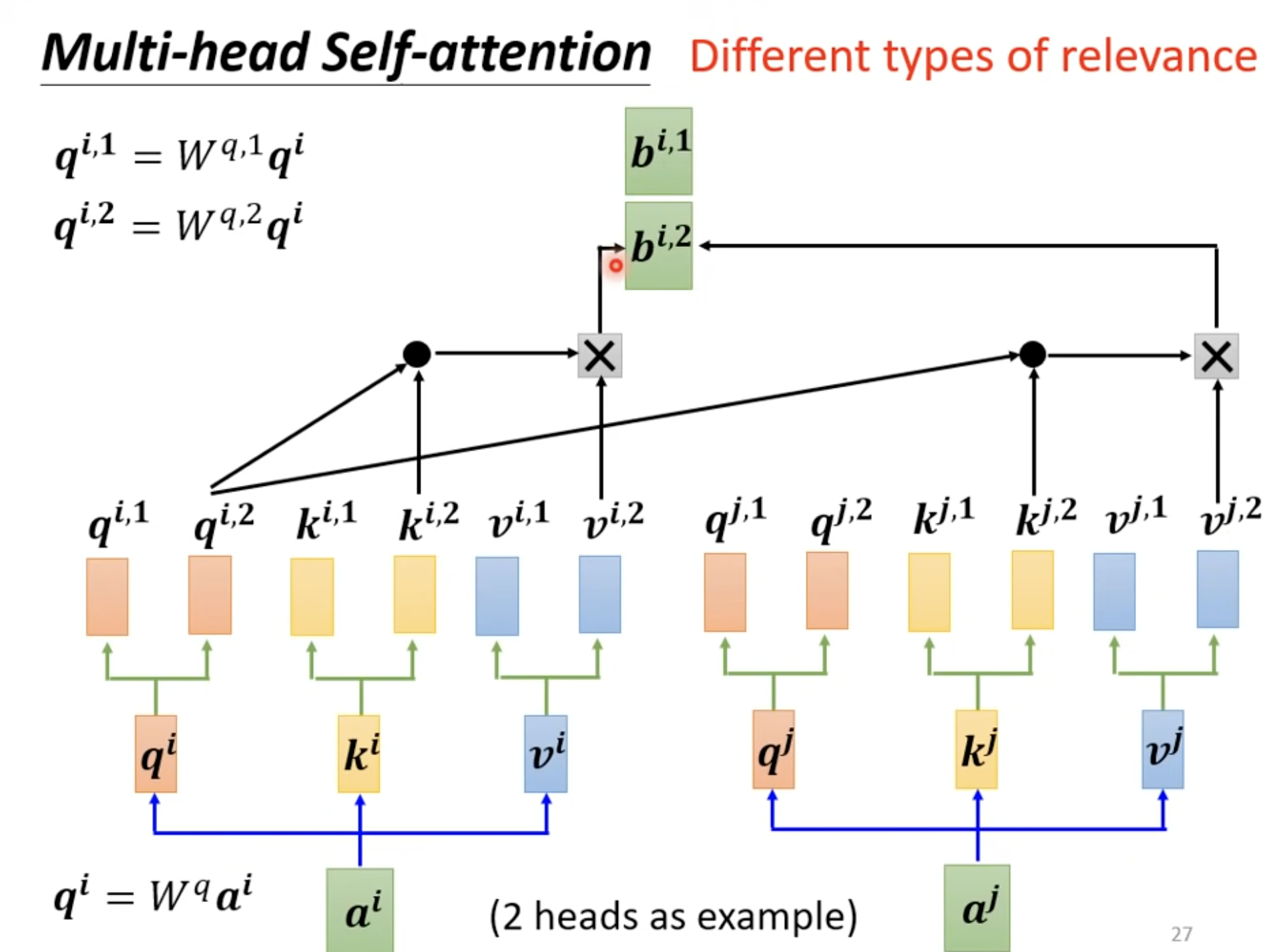
Multi-head Self-attention
Positional Encoding
| Token Embedding | Positional Encoding | |
|---|---|---|
| 作用 | 表示语义 | 表示顺序 |
| 是否可训练 | 是 | 可以是固定或可训练 |
| 维度 | d | d |
| 获取方式 | 查 embedding 表 | 查位置表或公式生成 |