OVERVIEW
下棋AI:在树上找必胜路径
数据:信息的载体,数字、字符或者其他符号组成的集合
可以分为数值型数据和非数值型数据
数据结构:数据对象+数据对象之间的关系的统称 Data_Structure={D,R}
分为线性数据结构和非线性数据结构
分层
数据结构涉及三个方面:
- 逻辑结构:从用户视图看,面向问题
- 物理结构:从具体实现视图看,面向计算机
- 相关的操作及其实现
一、 用“分层”思想理解数据结构的三个方面
我们可以把这三个方面想象成一栋大楼的设计和建造:
- 逻辑结构(用户视图/设计蓝图)
- 比喻:这是建筑师绘制的蓝图。它只关心房间的布局(哪个客厅连着哪个卧室)、空间的功能,而不关心墙壁是用砖头还是混凝土砌成的。
- 核心:它描述了数据元素之间的抽象关系。比如是线性的(一对一)、树形的(一对多)还是图状的(多对多)。
- 例子:
线性表就是一个逻辑结构。它只规定数据元素是一个接一个排列的,就像一队人。至于这队人是站成一排(顺序表)还是手拉手但站得乱七八糟(链表),它不关心。
- 物理结构(实现视图/建筑材料与施工)
- 比喻:这是施工队根据蓝图,用具体的建筑材料(砖、钢筋、混凝土)把大楼盖起来的过程。
- 核心:它描述了数据在计算机内存中具体的存储方式。这是连接逻辑世界的抽象关系和物理世界的硬件实现的桥梁。
- 例子:实现
线性表这个逻辑结构,有两种经典的物理结构:- 顺序存储(数组):在内存中找一块连续的空间,把所有数据元素一个挨一个地放进去。
- 链式存储(链表):在内存中随便找地方存数据元素,同时用一个指针(地址)指向下一个元素的位置,把它们“链”起来。
- 操作及其实现(使用大楼/功能实现)
- 比喻:大楼盖好了,人们要使用它(进门、上楼、开灯)。这些操作的具体实现取决于大楼的结构(比如旋转门怎么转、电梯怎么运行)。
- 核心:基于某种物理结构,如何实现逻辑结构所要求的各种操作(增、删、改、查等)。同一操作,在不同物理结构上实现的效率天差地别。
- 例子:在
线性表中“获取第5个元素”:- 在顺序存储(数组) 中实现:因为内存是连续的,可以直接通过“首地址 + 4 * 每个元素大小”直接计算出第5个元素的内存地址,一步就能找到(随机访问,速度快)。
- 在链式存储(链表) 中实现:因为元素是分散的,必须从第一个元素开始,顺着指针一个一个地“走”,走4步才能找到第5个元素(顺序访问,速度慢)。
分层的好处:这种分层思想实现了抽象和实现的分离。我们在思考问题时,可以先专注于逻辑结构(我要解决什么问题),然后再选择最合适的物理结构(怎么在计算机里高效实现)。比如,我需要频繁随机访问,就选数组;我需要频繁插入删除,就选链表。
二、 与内存知识的紧密结合
物理结构是数据结构和内存知识交汇的地方。所有物理结构的实现,最终都归结为如何在内存中摆放和访问数据。
1. 内存的核心特征:地址
计算机内存被划分为无数个小的单元(通常是字节),每个单元都有一个唯一的地址,就像小区里每个房间都有一个门牌号。CPU通过地址来访问内存中的数据。
2. 两种物理结构的内存视角
a) 顺序存储结构(如数组)
- 内存布局:申请一大块连续的内存空间。
- 如何工作:
- 系统会分配一个基地址(首地址),也就是第一个元素的内存地址。
- 每个元素占用的字节数(
sizeof(int)等)是固定的。 - 要访问第
i个元素,CPU可以通过一个简单的公式直接计算出它的地址:元素i的地址 = 基地址 + i * 每个元素的大小。
- 优点:
- 随机访问效率极高:计算地址是O(1)时间复杂度,非常快。
- 缺点:
- 需要大块连续内存:如果数据量很大,可能找不到足够大的连续空间。
- 插入删除开销大:在中间插入一个元素,为了保持连续性,后面所有元素都必须向后移动。
b) 链式存储结构(如链表)
- 内存布局:每个元素(节点)可以存放在内存的任何位置,不需要连续。
- 如何工作:
- 每个节点不仅存储数据本身(
data),还额外存储一个指针(next),这个指针的值是下一个节点所在的内存地址。 - 从一个节点出发,通过它存储的地址,就能找到下一个节点。就像寻宝游戏,每个线索告诉你下一个线索在哪里。
- 访问第
i个元素,必须从第一个节点(头节点)开始,顺着指针链一个一个地“遍历”i次才能找到。
- 每个节点不仅存储数据本身(
- 优点:
- 充分利用零散内存:不需要连续空间,只要零散的内存够用,就可以分配。
- 插入删除效率高:只需要修改相关节点的指针指向,不需要移动大量数据。例如,在节点A和B之间插入节点C,只需让A的指针指向C,C的指针指向B。
- 缺点:
- 无法随机访问:必须从头遍历,访问效率低。
- 额外空间开销:每个节点都需要额外的空间来存储指针。
3. 更深一层:缓存与局部性原理
现代计算机为了弥补CPU和内存之间的速度差距,都设置了高速缓存(Cache)。Cache会一次性从内存中加载一块连续的数据(称为Cache Line)。
- 顺序结构(数组) 的优势在此被放大。因为数组元素在内存中是连续的,当你访问
a[0]时,a[1], a[2], a[3]...很可能已经被一起加载到高速缓存里了,接下来访问它们速度会极快。这叫做空间局部性好。 - 链式结构(链表) 的劣势在此也被放大。因为节点在内存中是分散的,访问
node0后,node1很可能不在缓存中,CPU必须去更慢的主内存里找它。跳来跳去地访问,称为缓存不友好,会导致缓存命中率低,虽然理论上操作是O(1)或O(n),但实际常数项时间很大,比理论慢很多。
总结
| 方面 | 核心问题 | 关键内存知识 |
|---|---|---|
| 逻辑结构 | 数据元素之间是什么关系?(线性、树、图) | 无直接关系,是抽象概念 |
| 物理结构 | 数据如何存储在内存中?(连续 or 分散) | 内存地址、连续性、指针(地址) |
| 操作实现 | 如何基于物理结构实现增删改查? | 地址计算、指针操作、缓存局部性 |
你老师的“分层”讲解,正是希望你能够先脱离具体的计算机限制去思考问题(逻辑结构),再结合计算机的物理特性去寻求最高效的解决方案(选择物理结构并实现操作)。理解了内存是如何工作的,你才能真正理解为什么不同的物理结构会有巨大的性能差异,从而在将来设计程序时做出最明智的选择。
ADT and OO
数据类型:数据集+操作集
ADT
好的,我们来详细介绍一下 ADT(抽象数据类型,Abstract Data Type)。它是计算机科学中一个极其重要的基础概念,与你老师讲的数据结构的三个方面紧密相关,是“分层”思想的完美体现。
一、ADT 是什么?—— 核心思想:分离“是什么”和“怎么做”
ADT 是一种数学模型,它只定义了一组数据以及对这些数据所能进行的操作,而并不涉及这些操作在计算机内部如何具体实现。
你可以把它理解为一个 “使用说明书” 或 “契约(Contract)”。
- 它定义了“做什么”(What):说明了有哪些操作可用(例如,一个“栈”ADT 会有
push(压入)、pop(弹出)操作)。 - 它隐藏了“怎么做”(How):完全不关心这些操作底层是用数组实现的还是用链表实现的。
一个简单的比喻: 想象一个电视机。
- ADT 就是电视机的遥控器。遥控器上定义了你可以进行的操作:开机、关机、换台、调音量。
- 你(用户)只需要知道按哪个按钮能实现什么功能,完全不需要关心电视机内部是液晶面板还是显像管,电路是怎么连接的。
- 电视机的内部实现(物理结构)可以不断升级换代,但只要遥控器(ADT 接口)不变,你的使用方式就完全不需要改变。
二、ADT 的三个核心组成部分
一个ADT通常由三部分组成:
- 数据对象(Data Objects):
- 描述了数据的构成元素。例如,“线性表”ADT的数据对象是具有相同特性的n个数据元素的有限序列。
- 数据关系(Relationships):
- 描述了数据元素之间的逻辑关系。这是逻辑结构的体现。例如,线性表中的元素是“一对一”的前后驱关系。
- 基本操作(Operations):
- 定义了能对数据进行的操作集合。这是ADT与用户交互的接口。每个操作通常会被精确定义其前置条件(调用前必须满足的条件)和后置条件(调用后产生的结果)。
三、为什么 ADT 如此重要?—— 四大优点
- 封装与信息隐藏(Encapsulation & Information Hiding)
- 将数据的具体实现细节隐藏起来,只暴露一个清晰的接口。使用者无需关心内部复杂实现,只需知道如何调用接口,降低了程序的复杂度。
- 抽象(Abstraction)
- 让我们可以在更高的逻辑层次上思考问题,而不是纠结于底层细节。我们先设计“需要什么操作”,再考虑“如何实现这些操作”。
- 可维护性与可修改性(Maintainability & Modifiability)
- 只要接口(ADT的定义)保持不变,内部实现可以任意更改和优化,而不会影响使用它的程序。例如,你可以今天用数组实现一个栈,明天发现链表更合适,就直接替换掉实现部分,所有调用栈操作的代码都完全不需要修改。
- 可复用性(Reusability)
- 设计良好的ADT(如栈、队列、链表)是通用的,可以在多个不同的程序或项目中重复使用,避免重复造轮子。
四、一个经典的ADT示例:栈(Stack)
我们来用“栈”这个ADT将所有的概念串联起来。
ADT 定义(逻辑结构 + 操作接口)
- 逻辑结构:一种特殊的线性表,只允许在一端(栈顶)进行插入和删除操作,遵循后进先出(LIFO)的原则。
- 数据对象:一个具有LIFO关系的数据元素集合。
- 基本操作:
InitStack(&S):初始化一个空栈S。Push(&S, e):将元素e压入栈顶。Pop(&S, &e):弹出栈顶元素,并用e返回。GetTop(S, &e):获取栈顶元素,但不弹出。IsEmpty(S):判断栈是否为空。
至此,我们完成了ADT的定义。它只有逻辑和接口,没有任何实现。
物理结构与实现(如何实现接口) 现在,我们选择两种不同的物理结构来实现这个ADT接口:
顺序栈(基于数组):
1 2 3 4 5 6
#define MAXSIZE 100 typedef struct { ElemType data[MAXSIZE]; // 静态数组:连续的内存空间 int top; // 栈顶指针(实际上是数组下标) } SqStack; // Push 操作的实现:将元素放入 data[top] 的位置,然后 top++
链栈(基于链表):
1 2 3 4 5 6 7 8 9 10
typedef struct StackNode { ElemType data; // 数据域 struct StackNode *next; // 指针域:指向下一个节点(内存地址) } StackNode, *LinkStackPtr; typedef struct { LinkStackPtr top; // 栈顶指针:指向链表的第一个节点 int count; // 栈元素计数器 } LinkStack; // Push 操作的实现:创建一个新节点,其 next 指向原栈顶,然后 top 指向这个新节点
用户视图(如何使用) 用户(程序员)在代码中这样使用栈,他完全不知道底层是数组还是链表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
#include "Stack.h" // 包含ADT的接口声明 int main() { Stack S; // 声明一个栈 int e; InitStack(&S); // 初始化栈 Push(&S, 10); // 压入元素 10 -> 底层可能是数组赋值,也可能是链表插入节点 Push(&S, 20); Pop(&S, &e); // 弹出栈顶元素 -> 底层可能是修改下标,也可能是移动指针 printf("Popped element is %d\n", e); // 输出 20 // ... 其他操作 return 0; }
用户代码
main.c只依赖于Stack.h头文件中的接口定义,而不依赖于Stack_array.c或Stack_list.c的具体实现。这就是分层和抽象的威力。
总结
| 概念 | 角色 | 与ADT的关系 |
|---|---|---|
| 逻辑结构 | 问题领域 | ADT 定义了逻辑结构(如栈是LIFO的线性表) |
| 物理结构 | 实现领域 | ADT 隐藏了物理结构(可以用数组或链表等多种方式实现) |
| 操作 | 交互方式 | ADT 公开了操作接口(API),并隐藏了其实现细节 |
ADT 是逻辑结构的抽象定义和物理结构的具体实现之间的一个关键中间层。 它完美地诠释了你老师所说的“分层”思想,是构建大型、复杂、可维护软件系统的基石。几乎所有的数据结构(列表、栈、队列、树、图、字典)都可以并且应该首先被定义为ADT。
OO
object-oriented = object + class + inherit + communicate(面向对象的机制而不是定义)
面向对象:封装、继承、多态
面向对象(Object-Oriented)的核心不是简单地用 class 关键字,而是用 对象(Object) 来组织代码,其思想建立在三大支柱之上:
- 封装 (Encapsulation)
- 是什么:将数据(属性) 和操作数据的方法(函数) 捆绑在一个对象里。
- 为什么:对外隐藏内部实现细节,只暴露一个安全的接口供外界使用。这是 “信息隐藏” 的体现,与 ADT 的思想一脉相承。
- 继承 (Inheritance)
- 是什么:允许一个类(子类)基于另一个类(父类)来构建。
- 为什么:实现代码的复用和扩展。子类自动获得父类的特性,并可以添加或覆盖自己的特性,建立起清晰的层次关系。
- 多态 (Polymorphism)
- 是什么:同一操作(方法)作用于不同的对象,可以有不同的解释,产生不同的执行结果。
- 为什么:允许使用父类接口来操作子类对象。这使得程序更通用、更灵活,实现了 “接口与实现分离”。
面向对象就是通过 封装 来构建独立、安全的模块(对象),通过 继承 来组织和复用代码,通过 多态 来实现基于统一接口的灵活操作。
算法
定义:an operation sequence of soluting a problem
特性:输入确定、输出确定、确定性(Definiteness)、有效性、有限性
确定性算法和非确定性算法–Deterministic/Non-deterministic(含义:对于同样的输入,输出要唯一)
非确定性算法的例子:AI对话,流程中有random随机数
算法 vs 程序
算法是人与人之间用来交流的,可以用不同的方式来完成;程序是算法的一种表达方式
证明与算法思想
数学归纳法
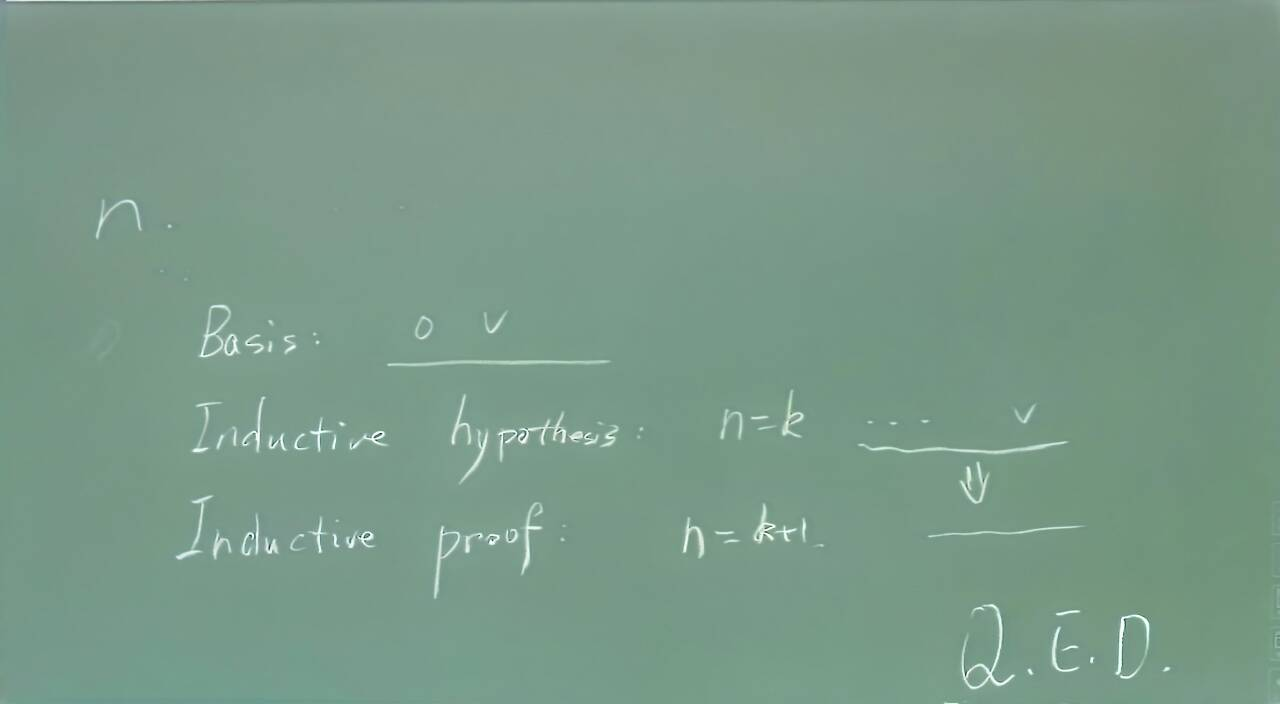
反证法
递归
只要函数调用自己或者调用形成一个“环”
(f->g->h->f),就可以视作递归
逻辑层:递归的思想(用户视图,面向问题)
在逻辑层,递归是一种解决问题的方法论和思维模式。它的核心思想是:
- 分而治之(Divide and Conquer):将一个复杂的大问题,分解成一个或多个规模更小、但结构与原问题相同的子问题。
- 递归定义:问题的解由其子问题的解组合而成。
- 递归出口(Base Case):必须存在一个或多个最简单、不可再分的情况,其解是明确已知的,用于终止递归。
经典例子:阶乘 (n!)
- 递归定义:
n! = n * (n-1)! - 递归出口:
1! = 1或0! = 1代码实现(逻辑视图):
1
2
3
4
5
def factorial(n):
if n == 1: # 递归出口 (Base Case)
return 1
else:
return n * factorial(n-1) # 递归步骤:用同样方法解决更小的子问题
物理层:递归的实现(计算机视图,面向实现)
在物理层,递归是由计算机的函数调用机制和内存布局来实现的。这就引入了复杂性。
核心物理结构:调用栈(Call Stack)
内存模型:程序运行时,操作系统会为其分配一块内存区域称为栈(Stack),专门用于管理函数调用。
每次函数调用会发生什么(物理过程):
- 栈帧(Stack Frame / Activation Record)的压入(Push): 每当调用一个函数(包括递归调用自己),系统就会在调用栈上分配一块连续的内存,称为一个“栈帧”。这块内存用于存储:
- 函数的参数(Parameters)
- 函数的局部变量(Local Variables)
- 返回地址(Return Address):函数执行完后,应该回到调用它的下一条指令的地址。
- 上一栈帧的指针等上下文信息。
函数执行:CPU使用当前栈帧中的参数和局部变量执行函数体。
- 栈帧的弹出(Pop): 当函数执行到
return语句时,系统会:- 将返回值(如果有)保存在指定位置。
- 释放(弹出) 当前函数的栈帧。
- 根据返回地址,跳回到调用者函数继续执行。
递归的物理过程可视化(以 factorial(3) 为例)
| 步骤 | 操作 | 调用栈内容(从底向上) | 说明 |
|---|---|---|---|
| 1 | 调用 factorial(3) | [main()] -> [factorial(3)] | main 函数调用 factorial(3),栈帧入栈 |
| 2 | 在 factorial(3) 中调用 factorial(2) | [main()] -> [factorial(3)] -> [factorial(2)] | 新的栈帧入栈,n=2 |
| 3 | 在 factorial(2) 中调用 factorial(1) | [main()] -> [factorial(3)] -> [factorial(2)] -> [factorial(1)] | 新的栈帧入栈,n=1 |
| 4 | factorial(1) 遇到出口,返回 1 | [main()] -> [factorial(3)] -> [factorial(2)] | factorial(1) 栈帧弹出,返回值 1 传给 factorial(2) |
| 5 | factorial(2) 计算 2 * 1 = 2,返回 2 | [main()] -> [factorial(3)] | factorial(2) 栈帧弹出,返回值 2 传给 factorial(3) |
| 6 | factorial(3) 计算 3 * 2 = 6,返回 6 | [main()] | factorial(3) 栈帧弹出,返回值 6 传给 main |
| 7 | main 函数收到结果 6 | [main()] | 调用结束 |
如何解决物理层的弊端?—— 优化技术
尾递归优化(Tail Recursion Optimization)
逻辑要求:递归调用必须是函数的最后一步操作,且返回值直接是递归调用本身,无其他运算。
物理效果:编译器可以识别尾递归,并复用当前函数的栈帧来进行下一次调用,而不是创建新的栈帧。这样就将递归的物理开销从 O(n) 降到了 O(1),避免了栈溢出。
例子:改写阶乘为尾递归形式:
1 2 3 4 5 6
def factorial_tail(n, accumulator=1): if n == 1: return accumulator else: # 所有运算在递归调用前完成,调用是最后一步 return factorial_tail(n-1, n * accumulator)
(注意:Python默认不支持尾递归优化,但很多函数式语言的编译器(如GCC、Erlang)会做这个优化)
记忆化(Memoization)
- 用于解决重复计算问题。将已计算过的子问题的结果缓存起来,再次遇到时直接查表返回,避免重复递归。
转换为迭代(Iteration)
- 手动使用循环和栈数据结构(如
list或deque)来模拟调用栈的过程。这完全消除了函数调用开销,并允许使用更大的堆(Heap)内存,但代码会失去递归的逻辑清晰性。
- 手动使用循环和栈数据结构(如
int main(int argc, char *argv[])函数这两个参数的设计意图这是一个非常经典且重要的设计,它构成了程序与操作系统(或用户)之间交互的基础桥梁。
核心设计意图
这两个参数的设计意图非常明确:为了让用户能够在启动程序时,通过命令行向其传递信息和指令。
在没有图形用户界面(GUI)的时代,或者为了实现自动化脚本(如Shell脚本、Batch脚本),这是程序接收输入的主要方式。即使在现代GUI程序中,这个机制也依然被广泛使用。
参数详解
1.
argc(Argument Count)
- 含义:参数计数。
- 类型:整型 (
int)- 作用:它告诉程序本次运行一共传递了多少个参数。
- 重要规则:程序自身的名字也被计算在内,并且是第一个参数。因此,
argc的值至少为 1。2.
argv(Argument Vector)
- 含义:参数向量(或参数值)。
- 类型:指向字符指针数组的指针 (
char *argv[]或char **argv)。
- 你可以把它理解为一个字符串数组(
string[])。- 作用:它存储了所有传递进来的参数字符串。
- 重要规则:
argv[0]:永远指向程序本身的名称(路径)。argv[1]:指向命令行中传递给程序的第一个真正的参数。argv[2]:指向第二个参数,以此类推。argv[argc]:是一个空指针 (NULL),用来标记数组的结束。这是一个非常关键的约定,因为它允许代码通过循环安全地遍历所有参数直到遇到NULL。一个简单的例子
假设我们编译了一个名为
myapp的程序,并在命令行中这样调用它:
操作系统会解析这个命令行,并这样为
main函数准备参数:
argc= 5 (一共5个参数:./myapp,-f,input.txt,output.txt,-v)argv是一个包含以下内容的数组:
argv[0]→"./myapp"(程序名)argv[1]→"-f"(第一个参数)argv[2]→"input.txt"(第二个参数)argv[3]→"output.txt"(第三个参数)argv[4]→"-v"(第四个参数)argv[5]→NULL(结束标记)设计意图的深层体现
灵活性与通用性: 这种设计没有预先规定参数的数量、顺序或含义,而是提供了一个通用的“字符串列表”机制。程序可以自由地解析这个列表,赋予每个参数特定的功能(例如,作为选项标志、文件名、用户名、IP地址等)。这使得它可以适应无数种不同的应用场景。
自动化与脚本支持: 由于参数是通过明确的字符串传递的,程序可以很容易地被其他程序(如Shell脚本、Python脚本)调用和配置。这是实现自动化工作流的基础。
- 清晰的约定:
argv[0]作为程序名是一个非常重要的约定。程序可以用它来知道自己是如何被调用的(例如,有些程序通过不同的软链接名来改变行为,如busybox)。- 使用
NULL(argv[argc]) 作为结束符是C语言中处理数组的常见模式(类似于字符串的\0结束符),它简化了遍历过程,防止越界访问。- 轻量级与高效: 在程序启动时一次性传递所有参数,是一种非常高效的数据交换方式,无需复杂的进程间通信(IPC)。
如何在代码中使用
下面是一个典型的代码示例,演示如何解析这些参数:
现代应用中的扩展
虽然
argc和argv是标准,但解析复杂的命令行选项(如--help,--output=file.txt)可能会很繁琐。因此,开发中通常会使用专门的库来简化这个过程,例如:
- GNU
getopt()(C语言,Unix/Linux)- Boost.Program_options (C++)
- 各种语言自带的相关库(如Python的
argparse)这些库的底层最终仍然是在处理
argc和argv,它们提供了更友好、更强大的接口来定义和解析命令行参数。总结
参数 设计意图 关键点 argc告知程序本次运行接收到的参数数量。 数量至少为1(包含程序名本身)。 argv提供一个字符串数组,存储所有参数的具体内容。 argv[0]是程序名;argv[argc]是NULL。总而言之,
argc和argv的设计是Unix哲学“一切皆文件”和“小程序协作”理念的完美体现。它用一种极其简单、统一且强大的方式,实现了程序与外部环境的初始交互,至今仍是命令行程序的基石。
怎么不用递归写汉诺塔?
C++的析构函数
核心概念
析构函数是一个特殊的成员函数,其名称是在类名前加上波浪号
~。它的主要目的是在对象被销毁时自动执行清理工作,例如释放内存、关闭文件、释放网络连接等资源。关键特性
- 自动调用:你不需要手动调用析构函数。当对象离开其作用域或被
delete时,编译器会自动调用它。
- 局部对象:在函数内部创建的对象,当函数执行完毕返回时,其析构函数被调用。
- 动态对象:用
new创建的对象,当使用delete释放它时,其析构函数被调用。- 全局/静态对象:在
main函数结束或程序退出时被调用。- 名称与无返回值:
- 名称固定:
~ClassName()- 没有返回值,甚至没有
void。- 不能接受任何参数,因此不能被重载。一个类有且只有一个析构函数。
- 与构造函数成对出现:
- 构造函数 (
ClassName()):在对象诞生时调用,负责初始化和获取资源(如new内存)。- 析构函数 (
~ClassName()):在对象死亡时调用,负责清理和释放资源(如delete内存)。为什么需要析构函数?
为了防止资源泄漏(Resource Leak)。
如果一个类在构造函数中动态分配了内存(使用了
new)或打开了文件,这些资源不会在对象销毁时自动释放。如果没有析构函数来delete这些内存或关闭文件,这些资源就会一直被占用,导致程序内存泄漏,性能下降甚至崩溃。析构函数确保了对象能“善始善终”,安全地释放其生命周期内所拥有的所有资源。
代码示例
输出结果:
从输出可以看到,析构函数在对象
greeting离开作用域时被自动调用,并成功释放了之前用new[]分配的内存。如果没有这个析构函数,Hello, World!所占用的内存就会泄漏。“三法则”/“五法则”
如果一个类需要自定义以下任何一个特殊成员函数,那么它通常需要自定义所有三个(C++11后是五个):
- 析构函数
- 拷贝构造函数
- 拷贝赋值运算符
(C++11后增加了移动构造函数和移动赋值运算符,合称“五法则”)
这是因为如果一个类需要手动管理资源(需要在析构函数中
delete),那么它的默认拷贝行为(浅拷贝)几乎总是错误的,会导致重复释放等问题。总结
特性 说明 目的 对象销毁时自动进行资源清理,防止内存泄漏。 名称 ~ClassName()调用时机 对象离开作用域或被执行 delete时自动调用。重要规则 不能有参数,无返回值,不可重载。 核心作用 与构造函数配合,管理对象的资源生命周期(RAII理念的核心组成部分)。 简而言之,析构函数是C++中实现资源自动管理、避免泄漏的基石。
指针和引用的区别
变量在运行时对应的是一块内存空间
1. 指针:内存地址的具体化与抽象漏洞
核心本质
指针是一个存储虚拟内存地址的变量。它的值是一个数字,这个数字对应进程地址空间中的一个字节的位置。
深入内存视角
指针自身的内存布局
- 指针本身是一个对象,它在栈或静态存储区占有内存空间。
- 其大小是固定的(通常4字节于32位系统,8字节于64位系统),由机器的寻址范围决定(
sizeof(int*) == sizeof(char*))。- 它存储的值是目标对象的首字节地址。
内存示例:
CPU通过加载
ptr的值(0x7ffd…c3d4),然后通过内存管理单元(MMU)将其转换为物理地址,最终访问到数据42。类型信息的丢失与重建
- 从机器码角度看,一个内存地址就是一堆比特位,没有类型信息。
void*最接近这种原始状态。- 指针的类型系统是编译器施加的静态检查和安全抽象。
int*告诉编译器:“当我解引用时,请将目标内存解释为一个int(通常是4字节)”。- 类型决定了指针算术的步长:
ptr + 1实际增加的字节数是sizeof(*ptr)。这是类型系统在底层的关键作用之一。多级指针与内存间接寻址
- 多级指针(如
int**)引入了多层级的内存间接寻址。
这常用于在函数内部修改外部的指针变量(例如,分配内存并让参数指向它)。
抽象漏洞 (The Abstraction Leak) 指针暴露了内存管理的细节,这就是所谓的“抽象漏洞”。程序员必须亲自处理:
- 生命周期:确保指针指向的内存在其被访问时依然有效。
- 所有权:明确谁负责释放内存,避免双重释放或泄漏。
- 有效性:检查指针是否为
nullptr或是否已成为“悬空指针”。2. 引用:编译器的语法糖与别名约束
核心本质
引用是受严格约束的指针。它本质上是一个在编译期被约定为“必须非空且不可重绑定的指针”。
深入编译器视角
实现方式
在绝大多数编译器的底层实现中,引用就是通过指针来实现的。
当你声明一个引用并初始化时:
编译器会创建一个匿名的、自动解引用的指针常量。这个指针对程序员是不可见的。
为什么没有自己的内存?
- 这个“隐藏的指针”当然需要存储空间(通常在栈上或寄存器中)。所谓“引用不占内存”是一种语言层面的语义承诺,而非物理事实。
- 这个承诺意味着:你不能获取引用自身的地址(
&ref得到的是目标地址),不能定义引用的数组,sizeof(ref)得到的是目标对象的大小。编译器通过语法规则保证了这些行为,强化了其“别名”的抽象。与
const指针的对比
int& ref在底层非常接近于int* const ptr(一个常量指针,但指向的数据可变)。const int& ref则接近于const int* const ptr(一个指向常量数据的常量指针)。 关键区别在于,编译器为引用提供了完全不同的语法,隐藏了所有指针操作,使其用起来像原始变量。编译期的安全性强制 引用之所以比指针安全,是因为编译器强制实施了两条规则:
- 必须初始化:这避免了“未初始化指针”的问题。
- 不可重绑定:这避免了指针的灵活性所带来的潜在错误(意外指向别的对象),并将“赋值操作”的语义固化为“对原目标对象的赋值”,而非“改变指向”。
内存模型与性能的终极对比
方面 指针 (Pointer) 引用 (Reference) 底层实现 显式存储地址的变量。 通常是匿名、自动解引用的 T* const。内存占用 显式存在,占用栈空间存储地址。 语言承诺不占空间,但实现上可能需要栈空间或寄存器存储地址。 汇编代码 生成显式的 LOAD 和 STORE 指令来操作指针本身和其指向的内存。 生成与指针完全相同的 LOAD/STORE 指令,但代码中看不到地址操作。 性能 完全相同。在优化的 Release 构建下,优秀的编译器为两者生成的机器码没有任何区别。任何性能差异都是神话。 完全相同。 示例分析:
两者的核心逻辑完全一致:通过一个存储在寄存器(如
rdi)中的地址来间接修改内存。总结与哲学
- 指针是“地址第一公民”。它将内存地址直接暴露给程序员,提供了最大的灵活性和控制力,用于实现底层数据结构、系统编程和与C的互操作。它要求程序员具备严格的内存管理纪律。
- 引用是“安全抽象第一公民”。它是一种设计模式,通过编译器的语法规则,将一个受限制的指针用法提升为语言特性。它的目的是消除指针的某些特性(可为空、可重绑定)以换取更高的安全性,同时保留其性能优势。
如何选择:
- 当你需要表达 “可选” (Maybe)、“可重置” (Resettable)或 “需要遍历” (Iterate)的语义时,使用指针(或更现代的
std::optional,std::unique_ptr)。- 当你需要表达 “别名” (Alias)、“必选” (Must Bind)且 “终身绑定” (Once Bound)的语义时,使用引用。这是函数参数传递和返回值最常见的场景。
从根本上说,引用是C++为了在不牺牲性能的前提下,推动代码从“C风格”向更安全、更抽象的“现代C++风格”演进的关键工具之一。