ANTLR词法分析器
ANTLR词法分析器
在运行一段程序的时候,发生了什么事情?
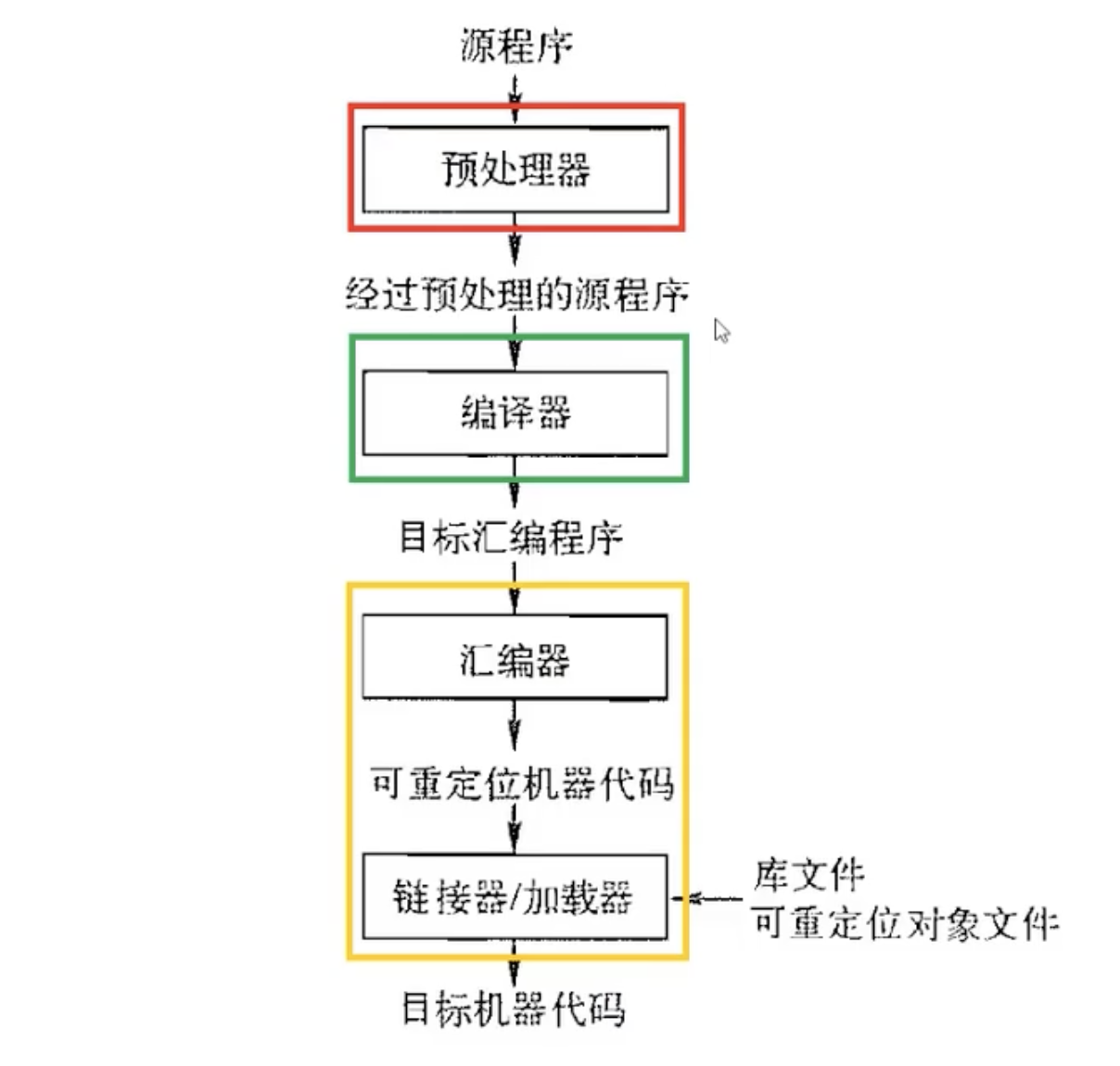
在学习编译原理时,我们主要关注绿色部分
编译器的功能:接受源语言程序,翻译成目标语言程序
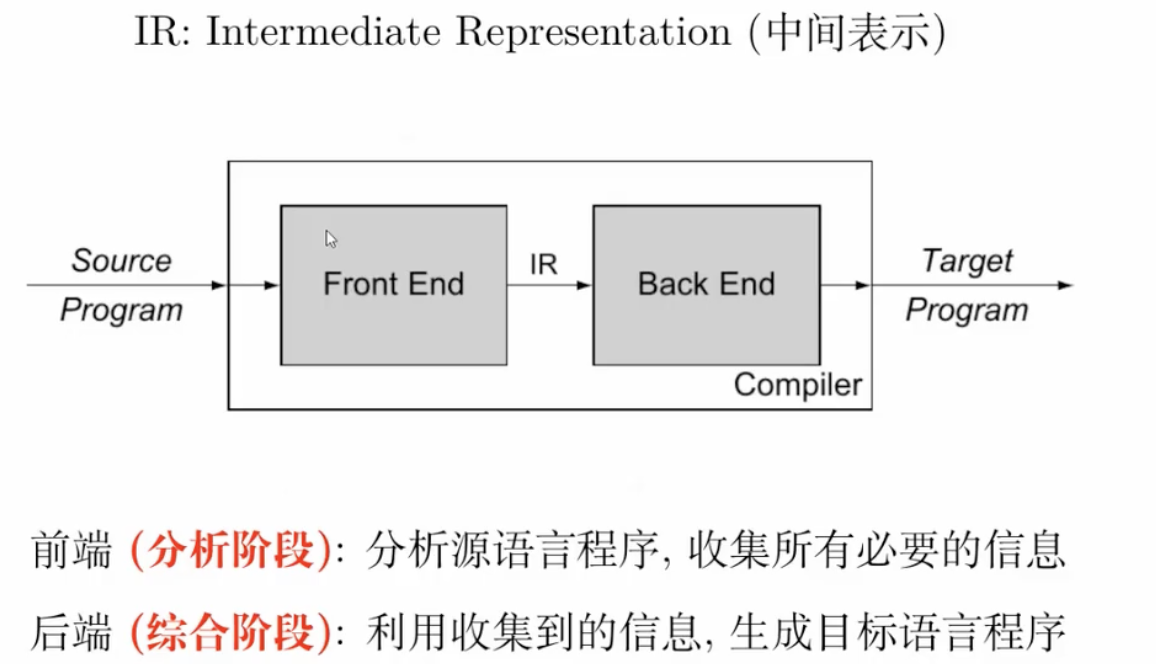
词法分析器的功能
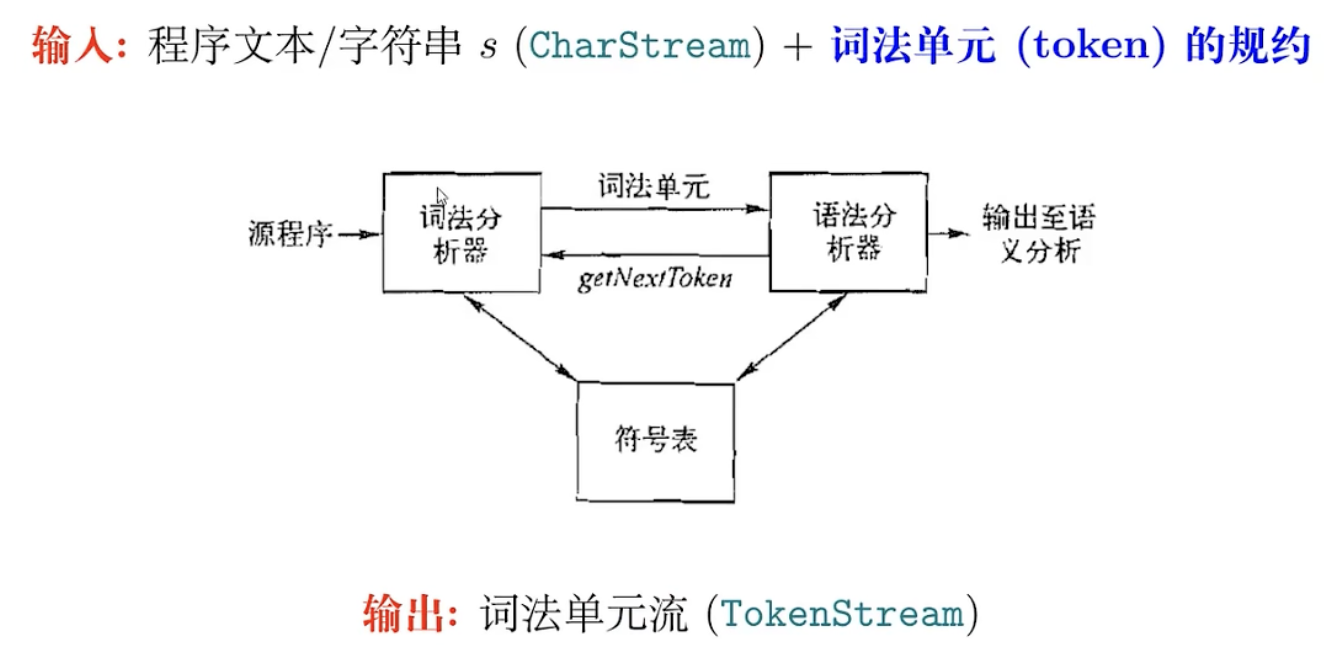
对于ANTLR来说:输入词法单元的规约(.g4),输出词法分析器(.java),当我们输入一个.c给词法分析器,就会输出TokenStream
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
/*
ANTLR4中的冲突解决规则
最前优先匹配 如ML_COMMENT vs DOCS_COMMENT
最长优先匹配 1.23 >=
非贪婪匹配 ()?? ()*? ()+?
*/
grammar SimpleExpr;
/*
程序是由若干个语句构成的,*表示任意多个
EOF表示停止符,表示一个program在碰到文件结束符之前不允许加入任何内容
在最抽象的这条规则上,我们一般都会加EOF
*/
prog : stat* EOF ;
/*
引号内的分号设计的语言的分号,而后面的分号是元(meta)语言的固有设置
'|'表示备选分支
*/
stat : expr ';'
| ID '=' expr ';'
| 'print' expr ';'
;
/*
递归在语言设计里是必然的,否则只会有有限可能个的程序
写成expr ('+' | '-' | '*' | '/') expr,会导致加减乘除优先级一样
.g4 规定:写在前面的规则优先级更高
*/
expr : expr ('*' | '/') expr
| expr ('+' | '-') expr
| '(' expr ')'
| ID
| INT
;
SEMI : ';' ;
ASSIGN : '=' ;
PRINT : 'print' ;
MUL : '*' ;
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
LPAREN : '(' ;
RPAREN : ')' ;
ID : ('_' | LETTER) WORD* ;
INT : '0' | ('+' | '-')? [1-9]NUMBER* ;
FLOAT : INT '.' NUMBER*
| '.' NUMBER+
;
// .* 贪婪匹配 --- 能匹配多长就匹配多长
// .*? 非贪婪匹配 --- 在匹配的各种可能性中找到最短的那种
DOCS_COMMENT : '/**' .*? '*/' -> skip;
SL_COMMENT : '//' .*? '\n' -> skip;
ML_COMMENT : '/*' .*? '*/' -> skip;
WS : [ \t\r\n]+ -> skip;
fragment LETTER : [a-zA-Z] ;
fragment NUMBER : [0-9] ;
fragment WORD : '_' | LETTER | NUMBER ;
This post is licensed under CC BY 4.0 by the author.