ABI与内联汇编
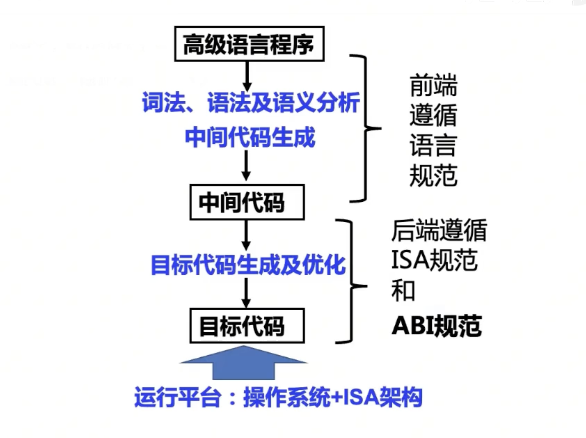
字长
字长:In computing, a word is the natural unit of data used by a particular processor design.
能直接进行整数/位运算的大小
指针的大小(索引内存的范围)
机器有多少字长,就代表着我们能用来索引地址空间的地址有多少位,直接决定了我么能用这个地址索引到的大小
64位地址空间能索引17,179,869,184GiB内存
API和ABI
API - 我们看到的“契约”
API(应用程序编程接口) 就像是你和图书馆管理员之间的对话规则。它定义了你可以说什么,但不关心管理员怎么去内部找书。
在 C 语言中,一个 struct 的 API 就是它的声明。
1
2
3
4
5
6
7
8
9
10
11
12
// student.h
// 这是一个 API 声明
struct student {
int id;
char name[20];
int age;
float score;
};
// 这些是操作该 struct 的 API 函数声明
void init_student(struct student *s, int id, const char *name, int age, float score);
void print_student(const struct student *s);
API 关心什么?
- 存在性:编译器知道有
struct student这个类型。 - 成员:编译器知道它包含
id,name,age,score这些成员。 - 操作:编译器知道可以调用
init_student和print_student这些函数。
只要你包含了 student.h,你的代码就可以编译通过。API 保证了编译时的正确性。
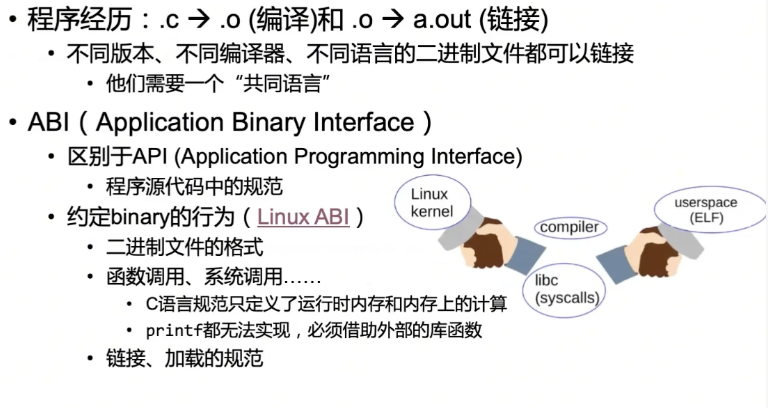
ABI - 系统底层的“实现细则”
ABI(应用程序二进制接口) 就像是图书馆内部的图书编码、上架和搬运规则。它定义了数据在内存中如何布局、函数调用时参数如何传递等底层细节。
当你编译链接一个程序,它需要和操作系统、库以及其他由不同编译器(甚至相同编译器的不同版本)编译的二进制代码进行交互。ABI 保证了这些二进制模块能在运行时正确协作。
现在,让我们通过 struct student 来看 ABI 的几个关键方面。
1. 数据大小和对齐(Data Size and Alignment)
这是 struct 与 ABI 最直接相关的部分。
规则:
- 对齐:每个成员在内存中的地址必须是其类型大小的整数倍(具体规则可能因 ABI 而异)。例如,一个
int(通常为 4 字节)的地址必须是 4 的倍数。 - 填充:编译器为了满足对齐要求,会在成员之间插入无用的“填充字节”。
- 总大小:整个
struct的大小必须是其最宽基本成员大小的整数倍。
我们的例子: 假设在 x86-64 System V ABI(Linux 等系统常用)下:
int: 4 字节,4 字节对齐char[20]: 20 字节,1 字节对齐float: 4 字节,4 字节对齐
1
2
3
4
5
6
7
8
struct student {
int id; // 偏移 0, 占用 [0, 3]
char name[20]; // 偏移 4, 占用 [4, 23] (对齐要求1,4是1的倍数)
int age; // 偏移 24, 占用 [24, 27] (对齐要求4,24是4的倍数)
float score; // 偏移 28, 占用 [28, 31] (对齐要求4,28是4的倍数)
// 总大小 32 字节 (32是 max(4,1,4)=4 的倍数)
};
// 注意:在 `name` 和 `age` 之间没有填充,因为 4 已经满足 age 的对齐要求。
但是,如果换个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
struct example {
char a; // 大小1, 对齐要求1。 偏移 0。
// 编译器需要在这里插入填充,以确保下一个成员 `int b` 对齐到4。
char _pad[3]; // 编译器自动插入的3字节填充 [1, 2, 3]
int b; // 大小4, 对齐要求4。 偏移 4。 (因为 0 + 1 + 3 = 4, 4是4的倍数)
char c; // 大小1, 对齐要求1。 偏移 8。
// 编译器需要在最后插入填充,以确保整个struct的大小是其最宽成员(这里是int,4字节)的倍数。
char _pad2[3]; // 编译器自动插入的3字节填充 [9, 10, 11]
}; // 总大小 12 字节。 (12是4的倍数)
// 内存布局可视化:[a][.][.][.][b][b][b][b][c][.][.][.]
ABI 的影响:
- 内存使用:糟糕的布局会浪费内存。
- 缓存效率:紧凑的布局能更好地利用 CPU 缓存。
- 二进制兼容性:如果两个编译器(或同一编译器的不同设置)对同一个
struct使用不同的对齐规则,它们产生的二进制文件对struct的理解将不一致,导致内存读写错误。这就是 ABI 不兼容。
2. 函数调用约定(Calling Convention)
这规定了函数调用如何发生,是 ABI 的另一个核心。
当我们调用 init_student(&s, 123, "Alice", 20, 95.5); 时:
- 参数如何传递? 是通过 CPU 寄存器还是堆栈?哪些参数用哪些寄存器?
- 在 x86-64 System V ABI 中,前几个整型/指针参数使用
rdi,rsi,rdx,rcx,r8,r9,前几个浮点参数使用xmm0-xmm7。 - 所以
&s(指针) 很可能在rdi,123(整型) 在rsi,"Alice"(指针) 在rdx,20(整型) 在rcx,95.5(浮点) 在xmm0。
- 在 x86-64 System V ABI 中,前几个整型/指针参数使用
- 堆栈谁清理? 调用者(caller)还是被调用者(callee)?
- 返回值放在哪里?
ABI 的影响:
- 如果一个库是用一种调用约定编译的(例如 Windows 的
__vectorcall),而你的主程序用另一种约定(例如__cdecl)去调用它,程序会立刻崩溃,因为它们在“对话”时使用了完全不同的规则。
3. 名称修饰(Name Mangling)
在 C++ 中,因为函数重载的存在,编译器需要将函数名和参数类型信息编码成一个链接器可以识别的唯一名称。这个过程就是名称修饰。
不同的编译器(GCC vs MSVC)甚至同一编译器的不同版本,其修饰规则都可能不同。这就是为什么你通常不能用 MSVC 编译的库去链接 GCC 编译的程序,即使它们在同一个操作系统上。C 语言通常没有这么复杂的修饰,但也是一个 ABI 考虑点。
总结与类比
| 特性 | API(高级契约) | ABI(低级细则) |
|---|---|---|
| 关注点 | 功能、语法、头文件 | 内存布局、函数调用、二进制格式 |
| 稳定性 | 相对稳定,可以版本化 | 非常脆弱,一旦定下极难修改 |
| 影响范围 | 源代码级别 | 二进制级别(.o, .so, .dll, .exe) |
| 例子 | struct student {int id; ...}; | struct 在内存中的精确布局(包含填充) |
| 类比 | 酒店预订网站的界面 | 酒店后厨的工作流程和食材摆放标准 |
实践中的启示
为什么不能混用不同编译器编译的库? 因为它们可能遵循不同的 ABI(例如 MSVC 和 GCC 在 Windows 上的 C++ ABI 不同)。
为什么系统升级(如 glibc 版本升级)有时需要重新编译所有程序? 因为 glibc 的新版本可能引入了 ABI 不兼容的更改。
如何写出 ABI 友好的代码?
- 对于要暴露给外部二进制模块的
struct,明确其内存布局(如使用#pragma pack或__attribute__((packed))),但需谨慎,这可能影响性能。 - 使用稳定的 ABI 作为二进制接口,例如 C 语言接口通常比 C++ 更稳定。
- 通过动态库的版本化来管理 ABI 变更。
- 对于要暴露给外部二进制模块的
API 是程序员之间的约定,而 ABI 是编译器、链接器、操作系统和硬件之间的约定。
汇编
call 指令为何压栈:保留“回家”地址
核心原因:函数是通用代码,不知道自己被谁调用。CPU执行跳转后也会“忘记”来路。因此,必须在跳转前明确保存返回地址(即call后下一条指令的位置),否则函数执行完毕将无法正确返回。
工作机制:
call指令:先将返回地址压入栈,再跳转至函数。ret指令:从栈顶弹出地址,并跳回该处。
为何用栈? 栈的后进先出特性完美匹配函数的调用顺序:最后被调用的函数(call)最先返回(ret),使得函数嵌套、递归调用得以实现。
一句话总结: call压栈是为了给ret留下“回家”的地址,这是实现函数调用和返回的基础机制。