进程的地址空间
1
2
3
4
5
6
struct proc {
struct CPUState cpu; // points to mem[MEM_SIZE]
uint8_t mem[MEM_SIZE];
// OS-internal state (pid, buf, buf_len, ...)
};
注意:进程好像是…有内存的?
这个模型告诉我们: 一个进程 = CPU状态 + 它能访问的内存
进程的地址空间 (Address Space)
操作系统为每个进程提供的一套独立的、连续的虚拟内存地址范围,因此也叫 “虚拟地址空间”。
核心作用
- 隔离与保护:不同进程的地址空间相互独立
- 便于管理与扩展:程序以为自己占有一大片连续内存 (实际按需分配)
- 支持共享在隔离的前提下,允许有限的共享
一个进程的地址空间的典型布局:
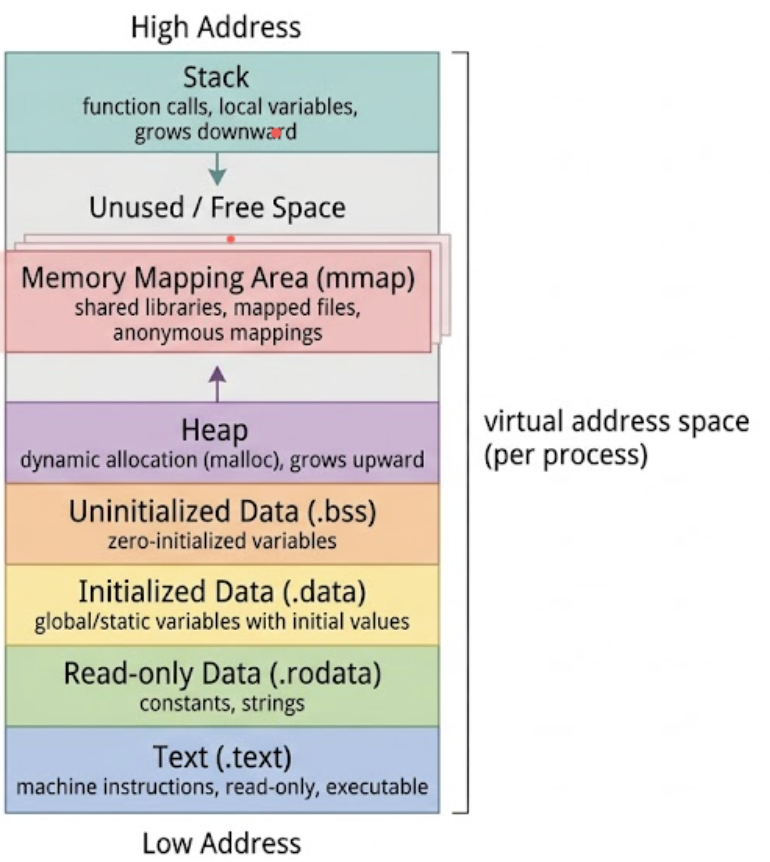
- 字节 “是什么”:本身不带类型,由 CPU 的 ISA 决定
- 字节 “放哪”:由链接与可执行文件格式决定
- 编译/汇编会生成各类段 (.text, .rodata, …),链接器决定布局
- 字节 “初始是什么样”:由 OS 加载器 + ABI 约定决定
- Load 程序段,清零 bss、建立初始 CPU 状态 (PC, SP)、准备运行时栈内容 (argc, argv, enpv, auxv)
- 划定动态区域 (堆、栈……)
我们来举个例子!
🐧我们来看一个小企鹅都会写的C程序:
当我们按下 run code,首先会进入编译期
在编译之后,会被拆成:
段 内容 是否有初值 .text机器指令 ✔ .rodata只读数据(字符串常量) ✔ .data已初始化全局变量 ✔ .bss未初始化全局变量 ❌(默认 0) 我们可以看看每个东西会被放到哪里:
.text:printf("hi");—call printf这些机器指令就会被放在.text区域,显然,这个区域通常是只读不可写、可执行的,同一个程序的多个进程可以共享
.rodata:显然,”hi”会被放在这里(如果有const、全局变量也会被放在这里)于是这也可以顺便解释一个事情:
这个程序是错误的,就是因为我们在尝试修改
.rodata区域
.data:x就放在这里,它可读可写,在程序启动时就有确定值
.bss:那就是y的归宿了,不过注意:.bss在可执行文件里 不占空间(因为没必要存放一堆0)
我们可以引申出一个链条:
变量名(x / y) → 地址 → 地址空间 → mmap → 物理内存 → CPU 访问
仍然放一个例子:
1
2
3
4
5
6
7
int x = 1; // .data
int y; // .bss
int main() {
y = 42;
return x + y;
}
‼️在程序运行的时候,是没有“变量名”的,只有地址+偏移,变量 = 虚拟地址上的一段内存,访问变量本质上是往某个虚拟地址写数据‼️
如:y = 42; 就可能变为:
1
mov DWORD PTR [0x404000], 42
也就是说,y被编译成一个固定地址(或相对地址)
而data_start + offset → 变量地址,当然,这是早期教学的想法,现在实际上是这样的:变量地址 = RIP + offset(RIP是当前指令地址),而在编译期实际上确定的是“段内偏移差”!那后续呢?我们先按下不表
如:
1
mov DWORD PTR [rip + offset], 42 ; 写 y
好了,这里我们要做一个严肃的区分:
| 阶段 | 做什么 | 结果 |
|---|---|---|
| 编译(compile) | 把源代码翻译成汇编 / 机器码 | 指令 + 偏移关系(RIP-relative offset)已经确定,但虚拟地址还没最终定 |
| 链接(link) | 把多个目标文件组合成 ELF 可执行文件 | 每个段的相对地址在 ELF 文件里确定(.text/.data/.bss 的布局、段偏移) |
| 加载(load / execve) | OS 把 ELF 文件映射到进程虚拟地址空间 | 每个段的虚拟基址在运行时确定(ASLR) |
编译器的视角,是单个源文件的视角,它只知道这个函数、这个变量、这个段的 局部位置,不知道整个程序里其他模块(库、函数)的布局
而链接器是全局视角,要做的事情,就是:
合并多个目标文件/静态库
把
.text/.data/.bss合并到一个最终 ELF 文件里分配段内偏移
例如把 main.o 的
.text放在 0x0~0x800,把 utils.o 的.text放在 0x800~0x1000把各个段排布成连续地址空间
修正相对引用
比如全局变量跨模块访问,要把
mov y的偏移改成段内最终位置
那加载期有啥用呢?现代系统有几个原因:
- ASLR(地址随机化)安全
- 每次程序加载,.text/.data/.bss 都可能映射到不同虚拟地址
- 防止攻击者预测地址
- 共享库 / 动态库
- libc.so、libm.so 等库在多个程序之间共享
- 不同程序的加载地址可能不同
- 编译期无法知道最终加载地址
- 虚拟内存映射(mmap)
- 堆、栈、匿名 mmap 页都是加载期分配的
- 编译期根本无法决定这些区域的虚拟地址
在程序运行execve时,OS不会“复制变量”,而是利用mmap去做一个映射!
1
2
mmap(.data) → 0x403000
mmap(.bss) → 0x404000(匿名 + 清零)
当 OS 执行 execve:
随机选择虚拟基址(ASLR):
1 2 3
.text → 0x7f100000 .data → 0x7f102000 .bss → 0x7f102800
mmap 把 ELF 文件映射到这个地址
RIP-relative 指令仍然有效,因为:
1
实际地址 = RIP(runtime address) + 编译/链接确定的 offset
- 虚拟地址变了,但 offset 保持不变
- 因为两者整体平移,RIP-relative 地址自动指向正确变量
回到offset的问题,如果变量跨模块引用(比如 main.o 访问 utils.o 的 y),链接器会 修正 offset
对于 单文件引用本地变量,offset 不会变
对于 跨模块 / 跨目标文件,链接器可能修改 offset
修改后指令里写的 RIP-relative offset 就是链接后的正确偏移
自此,offset才会保持不变,因为在加载期,`实际虚拟地址 = RIP(runtime) + offset,指令和目标变量整体搬到新地址,所以 offset 永远正确
这里又来引申了:函数调用为什么也能用 RIP-relative?
很简单,假设我们有调用
foo();,编译后会变为call foo,而foo和call都在.text,链接器保证它们的相对距离固定,所以offset = foo - call指令位置,解释完毕!
未来的难点:动态链接
mmap
1
2
3
4
5
6
7
// 映射
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
int munmap(void *addr, size_t length);
// 修改映射权限
int mprotect(void *addr, size_t length, int prot);
所谓进程的地址空间,就是一块一块可以访问的内存,而mmap所做的,就是从地址空间里去指定大小、用途、权限,本质上就是在“虚拟地址空间”中建立一段映射规则
mmap做了三件事:找一段虚拟地址,设定权限(PROT_READ 、PROT_WRITE),建立映射来源
我们来简单“建立映射来源”:
情况1:匿名映射(malloc 背后)
1
mmap(NULL, size, ..., MAP_ANONYMOUS, -1, 0);
这表示这块地址映射到物理内存页(懒分配)
情况2:文件映射
1
mmap(fd=文件)
这表示这块地址映射到 文件内容
Example 1: 申请大量内存空间
- 瞬间完成内存分配
mmap/munmap 为 malloc/free 提供了机制
为什么能“瞬间”?很简单,mmap 根本没分配内存!它只是画了个大饼,记录这段地址以后需要内存,这就是延迟分配
1 2
p = mmap(...); p[0] = 1; // ← 这里才真正分配物理页
Example 2: Everything is a file
- 映射大文件、只访问其中的一小部分
1
2
3
4
with open("/dev/sda", "rb") as fp:
mm = mmap.mmap(fp.fileno(),
prot=mmap.PROT_READ, length=128 << 30)
hexdump.hexdump(mm[:512])
这个例子的意思是,我把一个128GB的文件,当成内存数组用
malloc
malloc 不是“向 OS 要内存”,malloc 是:在已有地址空间里做管理,只有在不够时才调用 mmap / brk
情况 1:小 malloc
1
2
3
4
5
6
7
8
9
10
p = malloc(64);
malloc:
free list 有 → 直接给
没有:
brk 扩展 heap
切一块给 p
访问 p:
page fault → 分配物理页
情况 2:大 malloc
1
2
3
4
5
6
p = malloc(1MB);
malloc:
mmap 一块区域
访问 p:
page fault → 分配物理页