软工一复习
题型
• 单项选择题、判断题(Java语法)
• 编程题:看程序写结果、改写代码(递归、类的初始化、Lambda演算)
• 问答、简答题(结构化编程、面向对象编程(封装、继承、多态)、字节码基础)
知识点
String
字符串创建与存储机制
- 字符串字面量赋值:
- 当使用
String str = "test"时,JVM会:- 在类加载的”加载”阶段将”test”放入运行时常量池
- 在”解析”阶段创建对应的String对象并存入字符串常量池
- 相同字面量的字符串变量会指向常量池中的同一个对象引用
- 当使用
- new String()创建:
String str = new String("test")会在堆中创建新对象- 虽然value字段可能引用相同的底层数组,但对象本身不同
- 与字面量创建的字符串对象不相等(==比较为false)
字符串拼接
- 编译期确定的拼接:
- 如
"test" + "test"会被编译器直接合并为”testtest” - 结果会放入字符串常量池,相同字面量会引用同一对象
- 如
- 运行期拼接:
- 如
str1 + str2会被转换为new StringBuilder().append(str1).append(str2).toString() - 会在堆中创建新String对象,不与常量池中的对象共享
- 如
- final变量的拼接:
- 使用final修饰的字符串变量拼接会触发”常量折叠”优化
- 效果等同于字面量直接拼接
字符串相关类比较
| 特性 | String | StringBuilder | StringBuffer |
|---|---|---|---|
| 可变性 | 不可变 | 可变 | 可变 |
| 线程安全 | 是(因不可变) | 否 | 是(同步方法) |
| 性能 | 低(频繁创建对象) | 高(无锁) | 中等(有锁) |
| 适用场景 | 常量字符串 | 单线程字符串拼接 | 多线程字符串拼接 |
intern()方法
- 功能:
- 如果常量池中存在相同内容的字符串,返回其引用
- 如果不存在,JDK6会在永久代创建新对象,JDK7+会将堆中引用存入常量池
- 版本差异:
- JDK6:
intern() ==比较可能为false(永久代与堆地址不同) - JDK7+:
intern() ==比较可能为true(常量池引用堆中对象)
- JDK6:
Lambda演算
现代数字计算机可以计算的本质上都是递归函数(图灵可计算函数);非递归函数则是计算机不可计算的。
1、lambda项
- 所有的变量都是 𝜆 项(名为原子)
- 若 𝑀 和 𝑁 是 𝜆 项,那么 (𝑀 𝑁 ) 也是 𝜆 项(名为应用)
- 若 𝑀 是 𝜆 项而 𝜙 是一个变量,那么 (𝜆𝜙.𝑀) 也是 𝜆项(名为抽象)
2、α变换
设 𝜆𝜙.𝑀 出现在一个 𝜆 项 𝑃 中,且设 𝜓 ∉ FV(𝑀),那么把 𝜆𝜙.𝑀 替换成𝜆𝜓.[𝜓/𝜙] 𝑀 的操作被称为 𝑃 的 𝛼 变换。(即把其中的自由变量替换成不属于M的其他符号)
3、β规约
形如(𝜆𝜙.𝑀) 𝑁 的 𝜆 项被称为 𝛽 可约式,对应的项[𝑁/𝜙] 𝑀则称为 𝛽 缩减项。(也就是把N作为Φ代入到M 中去)
4、括号的省略规则
- 最外层的括号可以省略,(\x.x)可以写成\x.
- 左结合的应用型的lambda项,如(((MN)P)Q),括号可以省略,表示为M N P Q(这个规则十分重 要)
- 抽象型的lambda项,(𝜆𝜙.𝑀)的M里最外层的括号可以省略,如\x.(xy)可以写成\x.xy
- 一个函数抽象的函数体将尽最大可能向右扩展,即: λx.M N 代表的是一个函数抽象λx.(M N) 而非函数应用(λx.M) N 。 省略规则的具体应用(关键是找\x.的抽象,\x.后面必然有相关的表达式和其一起作为一个抽 象): SUCC ZERO \n.\f.\x.f (n f x) \f.\x.x 不妨先看到最右边的,x旁边有个\x.这两者为一个抽象,应该加括号,再左边是\f.,(\x.x)本 身是个λ项,所以和\f.构成了一个抽象,故(\f.(\x.x)) 再看到左边的式子,f (n f x)均不为抽象,而是满足第3种情况,在在抽象种的M的括号可以 省略,因此(f (n f x))要括起来,旁边还有\x.,\f.和\n.因此都要逐一括起来,(\n.(\f.\x.(f (n f x))))。所以(((\n.(\f.\x.(f (n f x)))))(\f.(\x.x)))
5、具体例子
lambda演算中常用的λ项:(为了简便,一般用\来代替λ)
𝐙𝐄𝐑𝐎 = 𝜆𝑓.𝜆𝑥.𝑥
𝐒𝐔𝐂𝐂 = 𝜆𝑛.𝜆𝑓.𝜆𝑥.𝑓 (𝑛 𝑓 𝑥)
TRUE:⇔ λ xy.x
FALSE :⇔ λ xy.y
𝐏𝐋𝐔𝐒 = 𝜆𝑚.𝜆𝑛.𝑚 𝐒𝐔𝐂𝐂 𝑛
𝐌𝐔𝐋𝐓 = 𝜆𝑚.𝜆𝑛.𝜆𝑓.𝑚 (𝑛 𝑓)
𝐏𝐎𝐖 = 𝜆𝑏.𝜆𝑒.𝑒 𝑏
𝐏𝐑𝐄𝐃 = 𝜆𝑛.𝜆𝑓.𝜆𝑥.𝑛 (𝜆𝑔.𝜆𝑒.𝑒 (𝑔 𝑓)) (𝜆𝑢.𝑥) (𝜆𝑢.𝑢)
𝐒𝐔𝐁 = 𝜆𝑚.𝜆𝑛.𝑛 𝐏𝐑𝐄𝐃 𝑚
软件工程建模
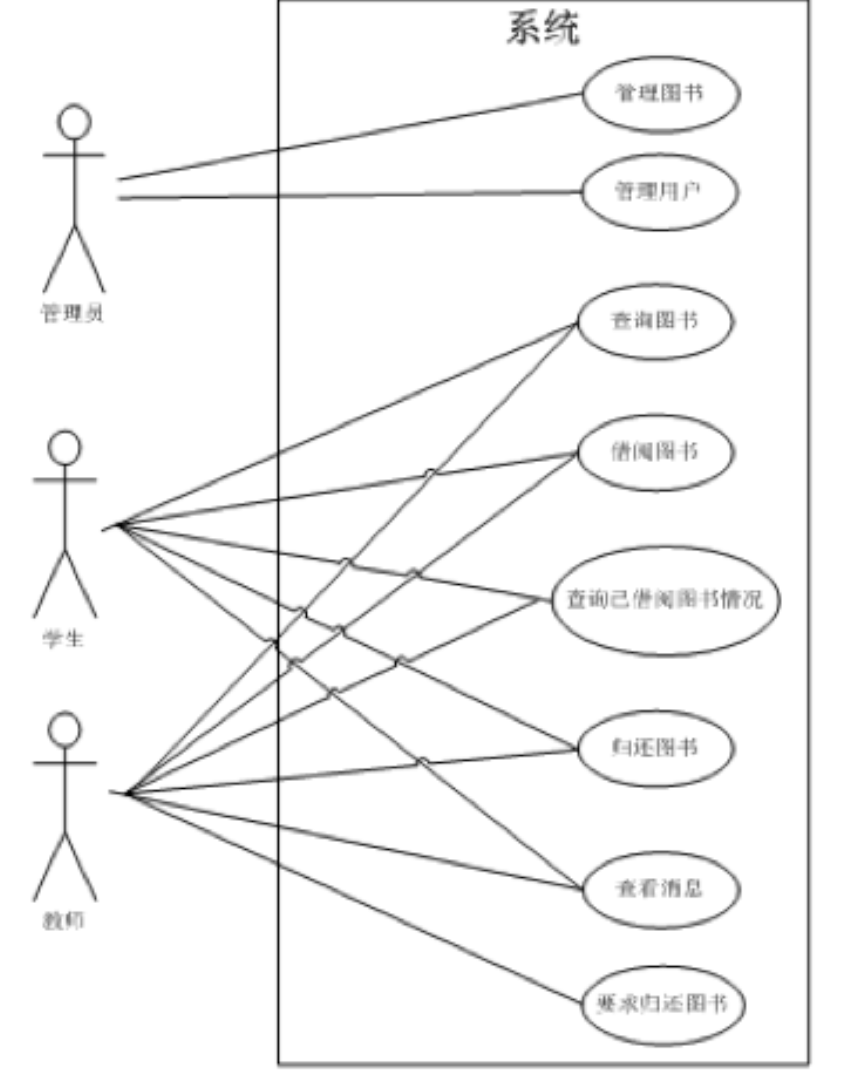
用例图
软件开发生命周期
指软件产品从开发到报废的生命周期,通常周期中包括了需求分析、软件设计、实现与调试、测试与验 收、部署、维护等活动。【问题定义,需求分析,软件设计,程序编码,软件测试,运行维护】
面向对象编程
结构化编程和面向对象编程:以前是函数之间的调用,现在是有职责的对象之间的交互
行为视角——结构化方法 数据视角——数据为中心方法 职责视角——面向对象方法
职责:
数据职责和行为职责 所谓职责,我们可以理解它为功能,每个类应当只有单一职责
寻找职责 • 寻找数据职责:找名词 • 寻找行为职责:找动词 • 确定职责 • 去除冗余、无关 • 检查是否满足“封装”的条件
数据职责 • 表征对象的本质特征 • 行为(计算)所需要的数据 • 教务系统中学生对象:计算年龄 • 税务系统中纳税人:计算所得税 行为职责 • 表征对象的本质行为 • 拥有数据所应该体现的行为 • 出生年月 • 个人收入
类
职责的抽象(抽象),每个类应当只有单一职责
类是一个描述或蓝图(被表示成一段代码),用于定义组成某类特定对象的所有特性。
类这个术语被用来描述相同事物的集合。它以概要的方式描述了相同事物集合中的所有元素,但却允许类中的每个实体元素可以在非本质特征上变化。

创建类的原因 对现实世界中的对象建模 对抽象对象建模 降低复杂度 隔离复杂度 隐藏实现细节 限制变化所影响的范围 创建中心控制点
对象
职责的实现(具体)–有职责对象之间的交互
对象包括属性(Properties)和方法(Methods),属性就是需要记忆的信息,方法就是对象能够提供的服务。
每个对象都保存着描述当前特征的信息。 对象状态的改变必须通过调用方法实现。 每个对象的标识永远是不同的,状态常常也存在着差异。
封装
它有两个核心目的:
- 隐藏实现细节:将对象的内部状态和行为细节隐藏起来
- 暴露必要接口:只提供必要的访问和修改方式
封装的三大规则
- 数据与行为结合:将数据和对该数据进行操作的行为放在同一个类中
- 示例:
Dog类包含size属性和bark()方法
- 示例:
- 职责驱动设计:根据类的职责确定数据和行为如何组合
- 职责完整性:类应该提供完整的操作,不能只有”半套”功能
构造方法
• 构造方法的关键特性是:它在对象被赋值给引用之前运行。 • 构造方法让你有机会介入new 操作的中间过程。
构造方法没有返回值
static
Java 是面向对象的,但有一种特殊情况不需要创建类的实例。 关键字static 允许一个方法在没有类实例的情况下运行。 静态方法的含义是:行为不依赖于实例变量,因此不需要实例或对象,只需要类本身。
静态变量初始化 • 静态变量在类被加载时初始化。 • 类之所以被加载,是因为JVM 决定现在是加载它的时候。 • 关于静态变量初始化,有两个规则:
- 在创建该类的任何对象之前,类中的静态变量会被初始化;
- 在运行该类的任何静态方法之前,类中的静态变量也会被初始化。
对象初始化初步 • 变量会在任何方法被调用之前初始化,甚至在构造方法之前; • 静态数据先初始化,然后是非静态数据; • 静态数据的初始化和静态代码块的执行按照代码中的书写顺序进行。
初始化顺序
- 静态成员变量和静态代码块:
- 在类加载时初始化
- 按照它们在代码中出现的顺序执行
- 实例成员变量和实例初始化块:
- 在创建对象实例时初始化
- 按照它们在代码中出现的顺序执行
- 构造函数:
- 最后执行
垃圾回收机制
Java的垃圾回收器要负责完成3件任务:
• 分配内存
• 确保被引用的对象的内存不被错误回收
• 回收不再被引用的对象的内存空间。
- 垃圾回收是一个复杂而且耗时的操作。如果JVM花费过多的时间在垃圾回收上,则势必会影响应用的运行性能。一般情况下,当垃圾回收器在进行回收操作的时候,整个应用的执行是被暂时中止(stop-the-world)的。这是因为垃圾回收器需要更新应用中所有对象引用的实际内存地址。不同的硬件平台所能支持的垃圾回收方式也不同。比如在多CPU的平台上,就可以通过并行的方式来回收垃圾。而单CPU平台则只能串行进行。不同的应用所期望的垃圾回收方式也会有所不同。服务器端应用可能希望在应用的整个运行时间中,花在垃圾回收上的时间总数越小越好。而对于与用户交互的应用来说,则可能希望所垃圾回收所带来的应用停顿的时间间隔越小越好。对于这种情况,JVM中提供了多种垃圾回收方法以及对应的性能调优参数,应用可以根据需要来进行定制。
- Java 垃圾回收机制最基本的做法是分代回收。
• 内存中的区域被划分成不同的世代,对象根据其存活的时间被保存在对应世代的区域中。
• 一般的实现是划分成3个世代:年轻、年老和永久。
• 内存的分配是发生在年轻世代中的。当一个对象存活时间足够长的时候,它就会被复制到年老世代中。对于不同的世代可以使用不同的垃圾回收算法。进行世代划分的出发点是对应用中对象存活时间进行研究之后得出的统计规律。一般来说,一个应用中的大部分对象的存活时间都很短。比如局部变量的存活时间就只在方法的执行过程中。基于这一点,对于年轻世代的垃圾回收算法就可以很有针对性。年轻世代的内存区域被进一步划分成
(1) 伊甸园(Eden)
(2) 两个存活区(survivor space)。
• 伊甸园是进行内存分配的地方,是一块连续的空闲内存区域。在上面进行内存分配速度非常快,因为不需要进行可用内存块的查找。
• 两个存活区中始终有一个是空白的。在进行垃圾回收的时候,伊甸园和其中一个非空存活区中还存活的对象根据其存活时间被复制到当前空白的存活区或年老世代中。经过这一次的复制之后,之前非空的存活区中包含了当前还存活的对象,而伊甸园和另一个存活区中的内容已经不再需要了,只需要简单地把这两个区域清空即可。下一次垃圾回收的时候,这两个存活区的角色就发生了交换。一般来说,年轻世代区域较小,而且大部分对象都已经不再存活,因此在其中查找存活对象的效率较高。
• 而对于年老和永久世代的内存区域,则采用的是不同的回收算法,称为“标记-清除-压缩(Mark-Sweep-Compact)”。
• 标记的过程是找出当前还存活的对象,并进行标记;清除则遍历整个内存区域,找出其中需要进行回收的区域;而压缩则把存活对象的内存移动到整个内存区域的一端,使得另一端是一块连续的空闲区域,方便进行内存分配和复制。
final
• 使用final 方法的原因有两个。 • 第一个原因是把方法锁定,以预防任何继承类修改它的意义。这是出于设计的考虑:你想要确保在继承中方法行为保持不变,并且不会被重写。 • 使用final方法的第二个原因是效率。如果你将一个方法指明为final,就是同意编译器将针对该方法的所有调用都转为内嵌(inline)调用。
被标记为final 的变量表示:一旦初始化,就永远不能被改变。
协作
基本问题求解的原则:分解与抽象
面向对象方法的原则:职责与协作
软件=一组相互作用的对象
对象= 一个或多个角色的实现(状态+行为)
责任= 执行一项任务或掌握某种信息的义务
角色= 一组相关的责任
协作= 对象或角色(或两者)之间的互动
协作模型描述的是一些关于“如何做”,“何时做”和“与谁工作”的动态行为。
抽象对象之间的协作 • 1. 从小到大,将对象的小职责聚合形成大职责; • 2. 从大到小,将大职责分配给各个小对象。 这两种方法,一般是同时运用的,共同来完成对协作的抽象。
可以协作对象 • 该对象自身 • 任何以参数形式传入的对象 • 被该对象直接创建的对象 • 其所持有的对象引用
迪米特法则:只与最直接的朋友交流
A与B协作— 情形1 • B拥有实现职责的所有数据 • 1. A计算(A先去拿B的数据,再计算) × • 2. B计算( A直接调用B的计算方法) √ A与B协作— 情形2 • A和B各拥有实现职责的一部分数据 • 1. A计算(A先去拿B的数据,再计算) • 2. B计算( A调用B的计算方法,通过参数将数据传给B)
评判标准 • 看A、B拥有数据的多少 • 看A、B谁拥有职责更合适 • 结构化编程范式偏向1、面向对象编程范式偏向2
类之间的关系

依赖
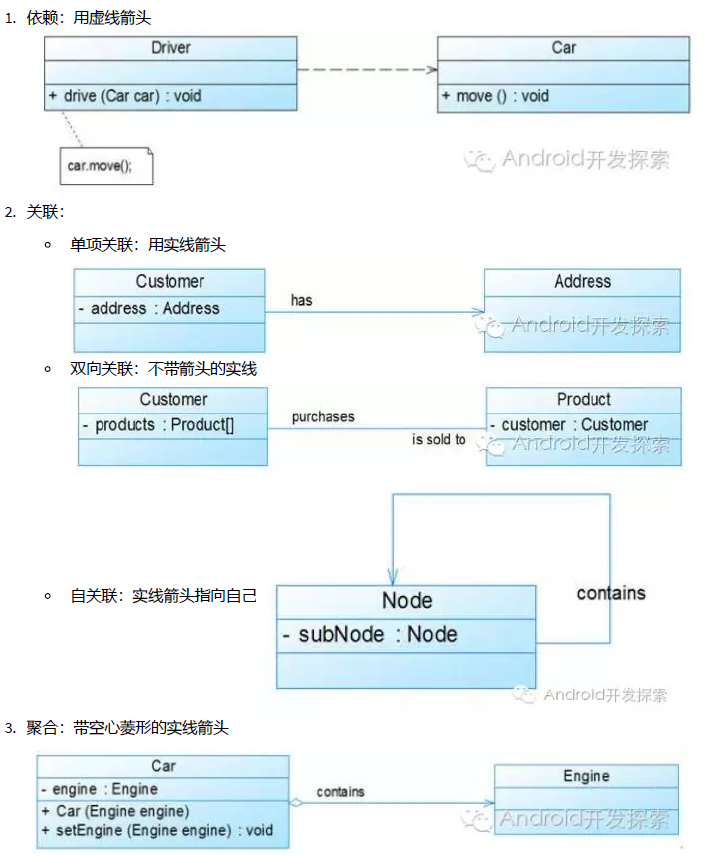
• 关系:” … uses a …” • 所谓依赖就是某个对象的功能依赖于另外的某个对象,而被依赖的对象只是作为一种工具在使用,而并不持有对它的引用。
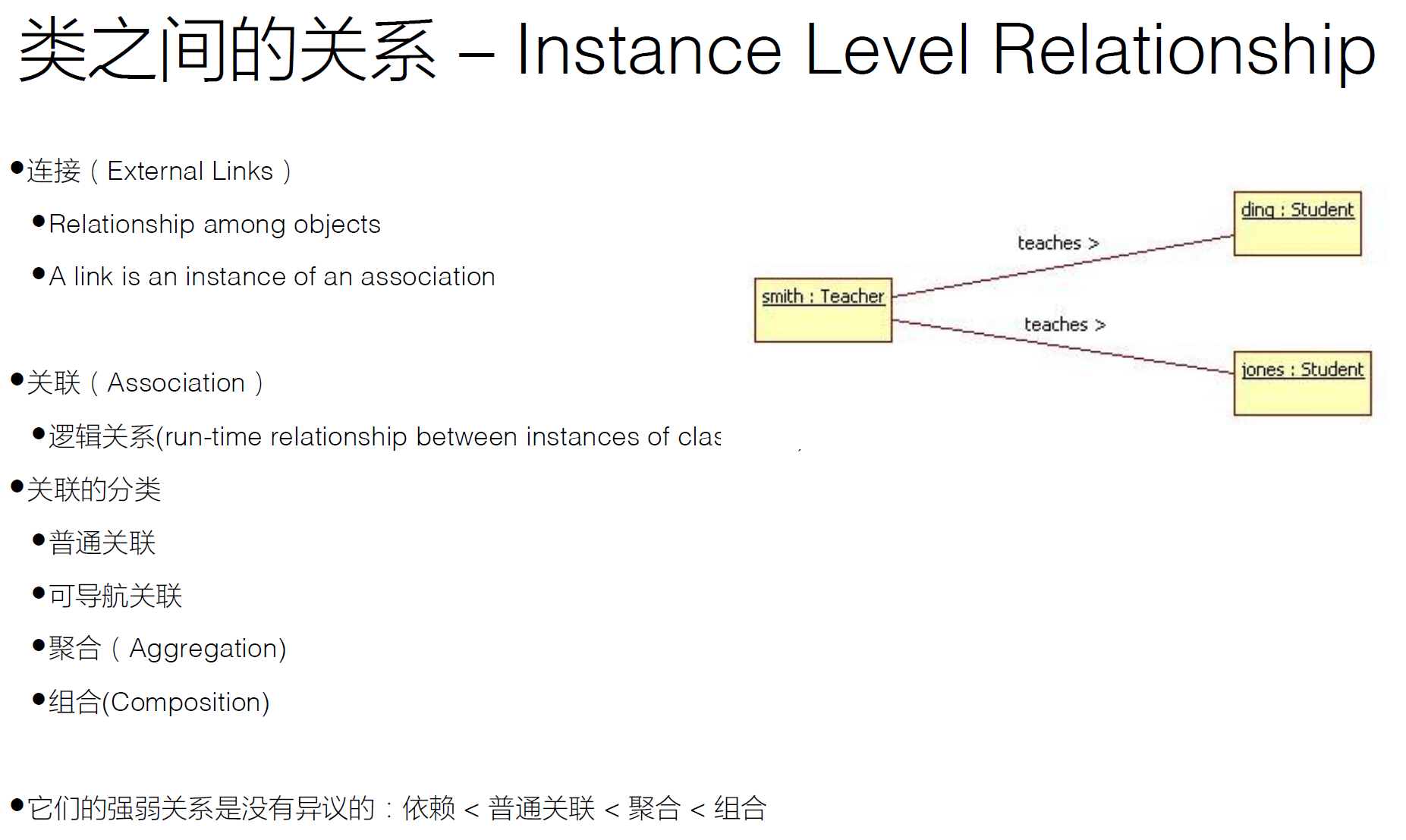
关联
• 关系:” … has a …” • 所谓关联就是某个对象会长期的持有另一个对象的引用,而二者的关联往往也是相互的。关联的两个对象彼此间没有任何强制性的约束,只要二者同意,可以随时解除关系或是进行关联,它们在生命期问题上没有任何约定。被关联的对象还可以再被别的对象关联,所以关联是可以共享的。
聚合 • 关系:” … owns a …” • 聚合是强版本的关联。它暗含着一种所属关系以及生命期关系。被聚合的对象还可以再被别的对象关联,所以被聚合对象是可以共享的。虽然是共享的,聚合代表的是一种更亲密的关系。
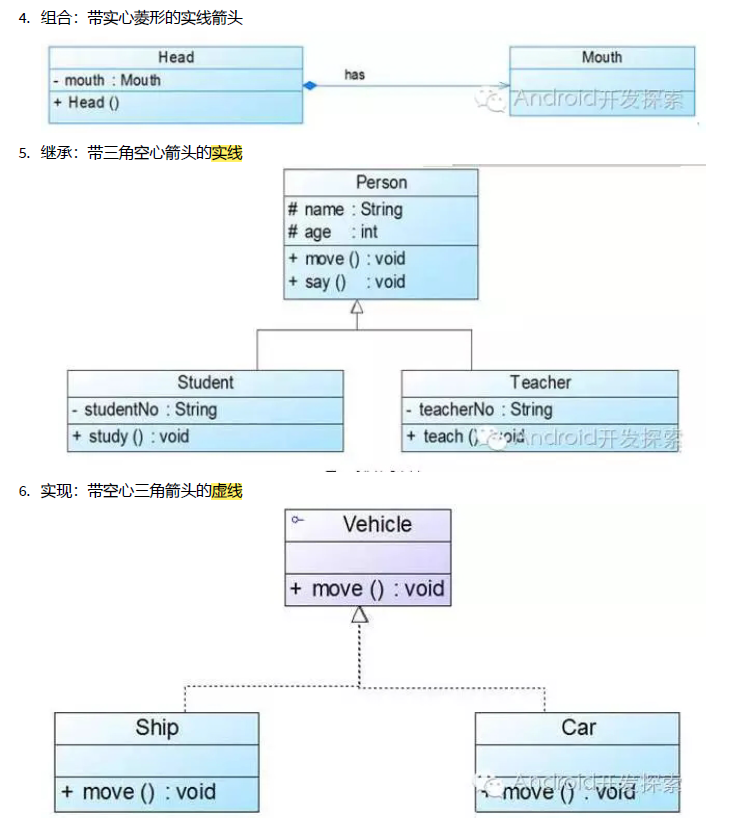
组合 • 关系:” … is a part of …” • 组合是关系当中的最强版本,它直接要求包含对象对被包含对象的拥有以及包含对象与被包含对象生命期的关系。被包含的对象还可以再被别的对象关联,所以被包含对象是可以共享的,然而绝不存在两个包含对象对同一个被包含对象的共享。
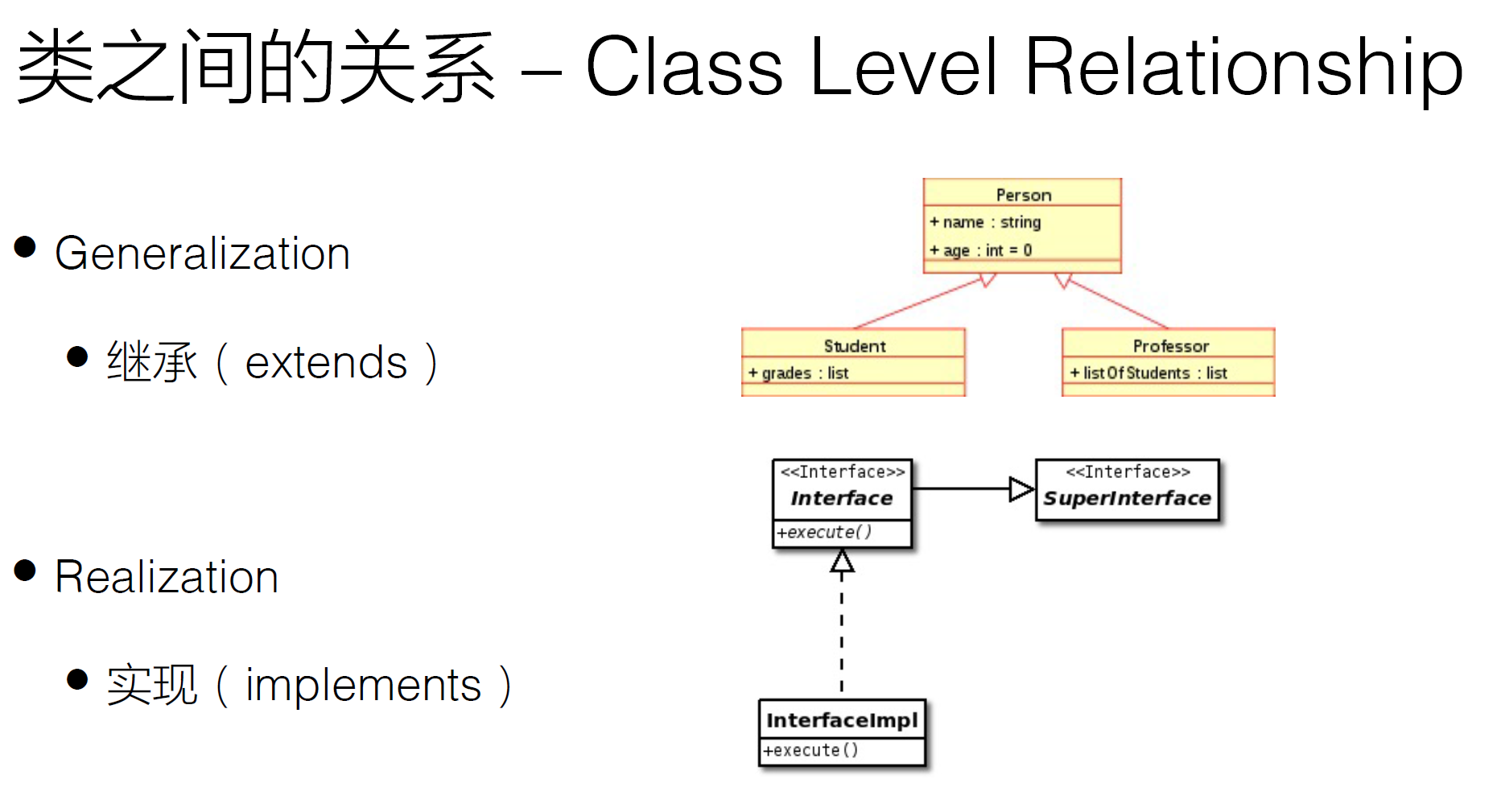
继承
extends:子类继承了父类所有的成员变量和方法
• 子类继承了父类所有的成员变量和成员方法 • 可以增加成员变量和成员方法 • 可以覆盖父类的成员方法 • 不可以覆盖父类的成员变量
• When you call a method on an object reference, you’re calling the most specific version of the method for that object type. • “Lowest” on the inheritance tree.
IS-A • When one class inherits from another, we say that the subclass extends the superclass. • When you want to know if one thing should extend another, apply the IS-A test. • 三角形是一种形状 • 猫是一种猫科动物 • 外科医生是一种医生
多态
多态的思想 • 多态通过分离“做什么”和“怎么做”,从另一角度将接口和实现分离开来。 • 而多态的作用则是消除类型之间的耦合关系多态方法调用允许一种类型表现出与其他相似类型之间的区别,只要它们都是从同一基类导出而来的。这种区别是根据方法行为的不同来而表示出来的,虽然这些方法都可以通过同一个基类来调用。 • 多态可以表达不同的计算类型,并且在运行的时候动态的确定正确的计算。 • 多态是指多个方法使用同一个名字有多种解释,当使用这个名字去调用方法时,系统将选择重载自动的选择其中的一个方法。在多态中只关心一个对象做什么,而不关心如何去做。
Abstract
抽象类本身没有用,除非他被继承,有了子类。抽象类的子类可以实例化。
非抽象类中不可以有抽象方法 抽象类中可以有非抽象方法
实现抽象方法 • 抽象方法的存在就是为了多态 • 具体的子类必须实现所有父类的抽象方法 • 实现抽象方法就像子类覆盖父类方法一样
Java.lang.Object
多态的代价 • 使用Object List
ArrayList<Object> myDogArrayList = new ArrayList<Object>();Dog aDog = new Dog();myDogArrayList.add(aDog);Dog d = myDogArrayList.get(0);无法通过编译!
多态的理解 • 一个对象包含了从每一个超类(父类)中继承的所有东西。 • 也意味着每一个对象实际也是其超类的类型的对象。 • 每个对象都是Object类的对象。
• 编译时,编译器决定你是否能调用某个方法 • 依据引用变量的类型,而不是引用变量指向的对象的类型 • 执行时,JVM虚拟机决定实际哪个方法被调用 • 依据实际引用变量指向的对象的类型
Overriding vs Overloading
Overriding的规则 • 条件: • 在不同类(父类和子类)、同一个方法、方法名字相同 • 参数必须一致,返回值必须兼容 • 例如:父类返回Animal,子类返回dog • 方法的可达性不能降低。 • 例如:父类是缺省的,子类是public
Overloading的规则 • 条件: • 同一个类中,不同方法,恰好名字相同 • 参数不同(类型、个数、顺序) • 返回值可以不同,但是不能知识返回值不同 • 方法的可达性提高降低都行。
陷阱:“overriding”私有方法
Overriding private methods in Java is invalid because a parent class’s private methods are “automatically final, and hidden from the derived class”.
这两个例子展示了Java中关于私有方法的一个重要特性:私有方法不能被重写(override)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class PrivateOverride {
private void f() {
System.out.println("private f()");
}
public static void main(String[] args) {
PrivateOverride po = new Derived();
po.f();
}
}
class Derived extends PrivateOverride {
public void f() {
System.out.println("public f()");
}
}
输出结果是:
1
private f()
PrivateOverride中的f()是private方法Derived类中的f()是一个public方法- 虽然看起来像是在重写,但实际上:
- 私有方法自动是final的,且对子类不可见
Derived.f()是一个全新的方法,与父类的f()无关
- 编译时类型是
PrivateOverride,所以调用的是PrivateOverride.f()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Base {
public void callFoo() {
foo();
}
private void foo() {
System.out.println("Base foo()");
}
}
class Child extends Base {
private void foo() {
System.out.println("Child foo()");
}
}
// 使用方式
Child c = new Child();
c.callFoo();
输出结果是:
1
Base foo()
Base.callFoo()调用的是Base.foo(),因为:foo()在Base中是private的Child.foo()是一个完全独立的新方法
- 即使实际对象是
Child类型,callFoo()方法内部仍然调用Base类的foo() - 这不是多态行为,因为私有方法不参与多态
结论:
- 私有方法不能被重写:子类中的同名方法实际上是新方法,与父类方法无关
- 方法调用取决于编译时类型:对于私有方法,调用在编译时就静态绑定到定义它的类
- 这不是真正的多态:多态只适用于非私有、非静态、非final的方法
要正确实现方法重写,应该:
- 使用protected或public访问修饰符
- 确保方法签名完全匹配
- 使用
@Override注解来让编译器检查是否真的重写了方法
方法调用的字节码
• Java虚拟机里面提供四种方法调用字节码指令 • invokestatic:静态方法 • invokespecial:实例构造器
overloading匹配优先级(略)
继承中的成员变量
这两个代码示例展示了Java中字段隐藏(field hiding)和方法重写(method overriding)的重要区别。
1
2
3
4
5
6
7
8
9
10
11
12
class A {
public String flag = "Father";
public void showFlag() {
System.out.println(flag);
}
}
class B extends A {
public String flag = "Son";
}
new B().showFlag();
输出结果: Father
- 子类
B声明了一个与父类A同名的flag字段,这称为字段隐藏(field hiding) - 当调用继承的
showFlag()方法时:- 方法是在
A类中定义的 - 方法内部的
flag引用的是A类的flag字段 - 因此输出的是”Father”而不是”Son”
- 方法是在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class A {
public String flag = "Father";
public void showFlag() {
System.out.println(flag);
}
}
class B extends A {
public String flag = "Son";
public void showFlag() {
System.out.println(flag);
}
}
new B().showFlag();
输出结果: Son
- 子类
B不仅隐藏了flag字段,还重写(override)了showFlag()方法 - 当调用
showFlag()时:- 调用的是
B类中重写的方法 - 方法内部的
flag引用的是B类的flag字段 - 因此输出的是”Son”
- 调用的是
| 特性 | 第一个示例 | 第二个示例 |
|---|---|---|
| 字段 | 子类隐藏了父类字段 | 子类隐藏了父类字段 |
| 方法 | 继承父类方法 | 重写了父类方法 |
| 方法调用行为 | 使用父类方法,访问父类字段 | 使用子类方法,访问子类字段 |
| 输出结果 | “Father” | “Son” |
总结:
- 字段隐藏:子类声明与父类同名的字段时,父类字段不会被覆盖,而是被隐藏
- 方法重写:子类可以重写父类方法,调用时会根据运行时类型决定调用哪个版本
- 字段访问:字段访问是静态绑定的(编译时决定),而方法调用是动态绑定的(运行时决定)
最佳实践是:
- 避免隐藏字段,容易引起混淆
- 使用方法访问字段而不是直接暴露字段
- 使用
@Override注解明确表示方法重写
这个例子清晰地展示了Java中成员变量(字段)在继承关系中的访问规则,这是与方法调用行为完全不同的重要特性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class A2 {
public String flag = "Father";
public void showFlag() {
System.out.println(flag);
}
}
class B2 extends A2 {
public String flag = "Son";
public void showFlag() {
System.out.println(flag);
}
}
public static void main(String[] args) {
A2 a = new B2(); // 父类引用指向子类对象
System.out.println(a.flag); // 输出: Father
A2 a2 = new A2(); // 纯父类对象
System.out.println(a2.flag); // 输出: Father
B2 b = new B2(); // 纯子类对象
System.out.println(b.flag); // 输出: Son
}
- 字段隐藏(Field Hiding):
- 当子类声明与父类同名的字段时,父类的字段不会被覆盖,而是被隐藏
- 子类对象实际上包含两个同名的
flag字段:一个来自父类,一个来自子类
- 字段访问规则:
- 字段访问是静态绑定的(编译时决定)
- 访问哪个字段完全取决于引用变量的声明类型,而不是实际对象的类型
- 这就是为什么
A2 a = new B2(); a.flag输出”Father”
- 与方法重写的对比:
- 方法调用是动态绑定的(运行时决定,基于实际对象类型)
- 如果调用
a.showFlag(),会输出”Son”,因为方法被重写了
| 代码片段 | 输出 | 解释 |
|---|---|---|
A2 a = new B2(); a.flag | Father | 引用类型是A2,访问A2的flag字段 |
A2 a2 = new A2(); a2.flag | Father | 纯A2对象,访问A2的flag字段 |
B2 b = new B2(); b.flag | Son | 纯B2对象,访问B2的flag字段 |
A2 a = new B2(); a.showFlag() | Son | 方法调用基于运行时类型(B2) |
结论:
- 字段没有覆盖(override)的概念,只有隐藏(hiding)
- 字段访问只看左边(引用类型),方法调用看右边(实际对象类型)
- 每个对象都包含它自己类和所有父类中定义的所有字段
- 最佳实践:
- 尽量避免隐藏字段
- 使用getter/setter方法访问字段
- 如果需要多态行为,使用方法而不是直接访问字段
这种设计是Java有意为之的,目的是保持字段访问的明确性和可预测性,与方法调用的多态行为形成对比。
成员变量没有覆盖 • 成员变量能不能访问是跟随引用变量的类型。 • 实际调用也是引用变量的类型。 • 因为两个flag根本就是不同的变量 • 变量没有覆盖的说法 。
解释Java继承中的字段隐藏和方法重写访问权限问题
这个例子展示了Java中字段隐藏和方法重写时访问修饰符变化的特殊情况。相比之前的例子,这里有一个重要变化:子类B2中showFlag()方法的访问修饰符从public改为了protected。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class A2 {
public String flag = "Father";
public void showFlag() {
System.out.println(flag);
}
}
class B2 extends A2 {
public String flag = "Son";
protected void showFlag() { // 注意:访问权限从public改为protected
System.out.println(flag);
}
public static void main(String[] args) {
A2 a = new B2();
System.out.println(a.flag); // Father
A2 a2 = new A2();
System.out.println(a2.flag); // Father
B2 b = new B2();
System.out.println(b.flag); // Son
}
}
- 字段隐藏仍然有效:
- 子类
B2隐藏了父类A2的flag字段 - 字段访问规则不变:取决于引用变量的类型
- 所以输出结果与之前相同(Father/Father/Son)
- 子类
- 方法重写的访问权限问题:
- 父类方法
showFlag()是public - 子类试图将其改为
protected(缩小了访问权限) - 这在Java中是编译错误,违反了方法重写的规则
- 父类方法
方法重写的访问权限规则:
Java规定:
- 子类重写方法时不能缩小访问权限
- 可以保持相同或扩大访问权限
- 合法的权限变化方向:
private→ 默认 →protected→public
如果要重写showFlag()方法,应该保持或扩大访问权限:
1
2
3
4
5
6
7
// 正确的方式(保持public)
public void showFlag() {
System.out.println(flag);
}
// 或者(如果父类不是public,可以这样)
protected void showFlag() { /*...*/ } // 仅当父类方法是protected或更宽松时才合法
Java这样设计是为了确保:
- 里氏替换原则:子类应该可以替换父类而不破坏程序行为
- 多态安全:通过父类引用调用方法时,不能因为子类缩小权限而导致不可访问
总结:
- 字段隐藏规则不受影响(仍取决于引用类型)
- 方法重写时不能缩小访问权限(本例会导致编译错误)
- 实际开发中应保持重写方法的访问权限不变(通常都是public)
可修改性
可修改性 • (狭义)可修改性:对已有实现的修改 • 可扩展性:对新的实现的扩展 • 灵活性:对实现的动态配置
继承vs组合
组合和继承都允许你在新的类中设置子对象(sub-object),组合是显式地这样做的,而继承则是隐式的。
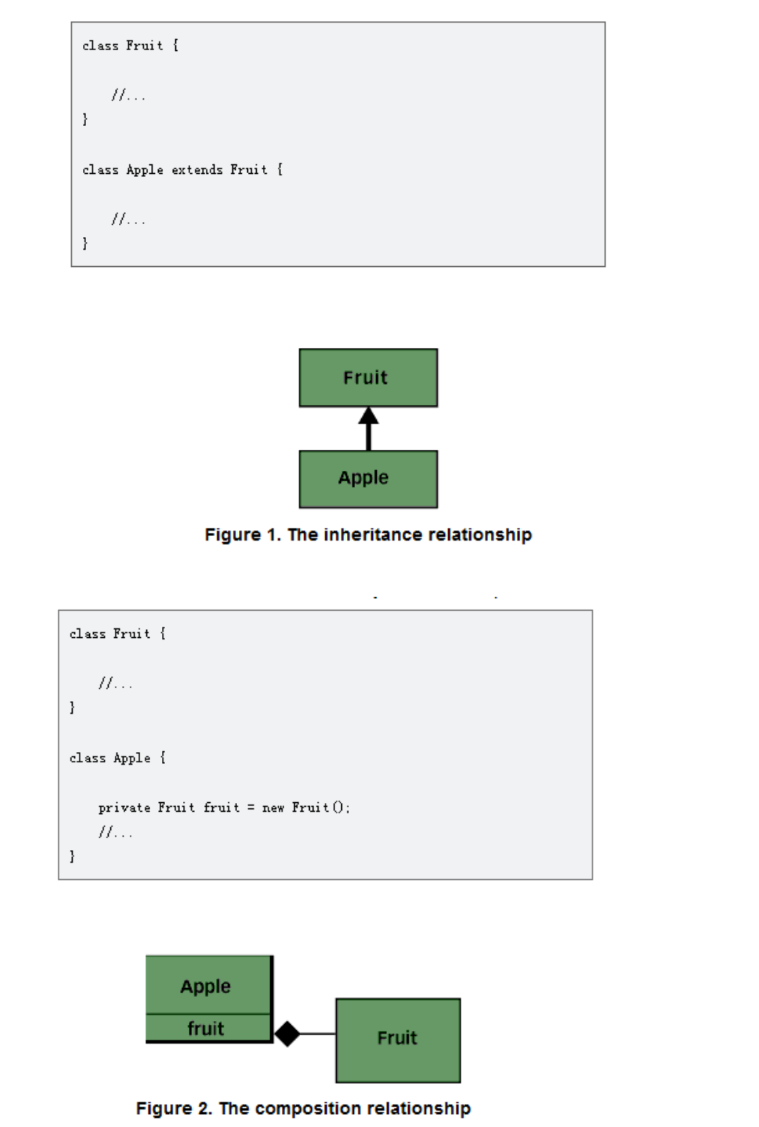
• Adding a new subclass : Inheritance helps make code easier to change • Changing the superclass interface : one little change to a superclass can ripple out and require changes in many other places in the application’s code
组合比继承更容易修改后端类的接口。如前例所示,后端类接口的变更只需要修改前端类的实现,而不一定需要改变前端接口。只要前端接口保持不变,依赖前端接口的代码仍能正常工作。相比之下,超类接口的变更不仅会沿着继承层次向下影响子类,还可能影响仅使用子类接口的代码。
组合比继承更容易修改前端类的接口。正如超类可能脆弱一样,子类可能很僵化。你不能随意更改子类的接口,必须确保子类的新接口与其超类型的接口兼容。例如,你不能在子类中添加与继承自超类的方法签名相同但返回类型不同的方法。而组合允许你更改前端类的接口而不影响后端类。
组合允许你延迟后端对象的创建(直到需要时才创建),并可以在前端对象的生命周期内动态更改后端对象。而继承在子类创建时就立即将超类映像包含在子类对象中,并在子类的整个生命周期中保持不变。
继承比组合更容易添加新的子类,因为继承具有多态性。如果有一段代码仅依赖于超类接口,那么这段代码可以不加修改地适用于新的子类。除非使用基于接口的组合,否则组合不具备这种特性。组合与接口结合使用时,是一种非常强大的设计工具。
与继承中直接调用继承的超类方法实现相比,组合中显式的方法调用转发(或委托)通常会有性能开销。之所以说”通常”,是因为实际性能取决于许多因素,包括JVM如何优化执行程序。
无论是组合还是继承,更改任何类的实现(而非接口)都很容易。实现变更的连锁效应仅限于同一个类内部。
| 特性 | 组合(Composition) | 继承(Inheritance) |
|---|---|---|
| 接口变更灵活性 | 更高 - 前后端接口可独立修改 | 较低 - 超类变更会影响子类 |
| 对象创建 | 可延迟创建,可动态替换后端对象 | 创建子类时即包含超类,不可动态变更 |
| 扩展性 | 需显式定义接口才能实现多态 | 天然支持多态,易于扩展新子类 |
| 性能 | 可能有方法转发开销 | 方法调用更直接高效 |
| 实现变更 | 都容易,影响范围限于单个类 | 都容易,影响范围限于单个类 |
- 优先使用组合:当需要灵活性、动态行为或避免继承的脆弱性时
- 合理使用继承:当需要利用多态性或存在明确的”is-a”关系时
- 最佳实践:组合+接口可以同时获得组合的灵活性和继承的多态优势
类的初始化
一个类的初始化包括3个步骤: • 加载(Loading),由类加载器执行,查找字节码,并创建一个Class对象(只是创建); • 链接(Linking),验证字节码,为静态域分配存储空间(只是分配,并不初始化该存储空间),解析该类创建所需要的对其它类的应用; • 初始化(Initialization),首先执行静态初始化块static{},初始化静态变量,执行静态方法(如构造方法)。
下面列出了可能造成类被初始化的操作 • 创建一个Java类的实例对象 • 调用一个Java类的静态方法 • 为类或接口中的静态域赋值 • 访问类或接口中声明的静态域,并且该域的值不是常值变量 • 在一个顶层Java类中执行assert语句 • 调用Class类和反射API中进行反射操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class A{
static int value = 100;
static {
System.out.println("类A初始化");
}
}
class B extends A{
static {
System.out.println("类B初始化");
}
}
public class StaticFieldInit{
public static void main(String[] args){
System.out.println(B.value);
}
}
当访问一个Java类或接口的静态域时,只有真正声明这个域的类或接口才会被初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class StaticBlock {
static final int c = 3;
static final int d;
static int e = 5;
static {
d = 5;
e = 10;
System.out.println("Initializing");
}
StaticBlock() {
System.out.println("Building");
}
}
public class StaticBlockTest {
public static void main(String[] args) {
System.out.println(StaticBlock.c);
System.out.println(StaticBlock.d);
System.out.println(StaticBlock.e);
}
}
输出c时,由于c是编译时常量,不会引起类初始化,因此直接输出,输出d时,d不是编译时常量,所以会引起初始化操作,即static块的执行,于是d被赋值为5,e被赋值为10,然后输出Initializing,之后输出d为5,e为10。
1
2
3
4
5
6
7
8
9
10
11
12
class Const{
public static final String NAME = "我是常量";
static {
System.out.println("初始化Const类");
}
}
public class FinalTest{
public static void main(String[] args){
System.out.println(Const.NAME);
}
}
常量在编译阶段会存入调用它的类的常量池中,本质上没有直接引用到定义该常量的类,因此不会触发定义常量的类的初始化。虽然程序中引用了 const 类的常量 NAME,但是在编译阶段将此常量的值“我是常量”存储到了调用它的类 FinalTest 的常量池中,对常量Const.NAME 的引用实际上转化为了 FinalTest 类对自身常量池的引用。也就是说,实际上 FinalTest 的 Class 文件之中并没有 Const 类的符号引用入口,这两个类在编译成 Class 文件后就不存在任何联系了。
1
2
3
4
5
6
7
8
9
10
11
class Const{
static {
System.out.println("初始化Const类");
}
}
public class ArrayTest{
public static void main(String[] args){
Const[] con = new Const[5];
}
}
通过数组定义来引用类,不会触发类的初始化
但这段代码里触发了另一个名为“LLConst”的类的初始化,它是一个由虚拟机自动生成的、直接继承于java.lang.Object 的子类,创建动作由字节码指令 newarray 触发,很明显,这是一个对数组引用类型的初初始化,而该数组中的元素仅仅包含一个对 Const 类的引用,并没有对其进行初始化。
接口的初始化
• 接口也有初始化过程,上面的代码中我们都是用静态语句块来输出初始化信息的,而在接口中不能使用“static{}”语句块,但编译器仍然会为接口生成类构造器,用于初始化接口中定义的成员变量(实际上是 static final 修饰的全局常量)。 • 二者在初始化时最主要的区别是:当一个类在初始化时,要求其父类全部已经初始化过了,但是一个接口在初始化时,并不要求其父接口全部都完成了初始化,只有在真正使用到父接口的时候(如引用接口中定义的常量),才会初始化该父接口。这点也与类初始化的情况很不同,回过头来看第 2 个例子就知道,调用类中的 static final 常量时并不会 触发该类的初始化,但是调用接口中的 static final常量时便会触发该接口的初始化。
接口

接口基础
- 接口定义:
- 使用
interface关键字定义,是一种完全抽象的类 - 所有方法默认是
public abstract的(Java 8前) - 所有字段默认是
public static final的
- 使用
- 接口实现:
- 类使用
implements关键字实现接口 - 实现类必须实现接口中所有抽象方法(Java 8前)
- 一个类可以实现多个接口
- 类使用
- 接口继承:
- 接口可以继承其他接口,使用
extends关键字 - 支持多重继承(一个接口可继承多个接口)
- 接口可以继承其他接口,使用
接口与抽象类的比较
| 特性 | 接口 | 抽象类 |
|---|---|---|
| 实例化 | 不能 | 不能 |
| 方法实现 | Java 8前不能,之后可以有默认方法 | 可以有具体方法 |
| 字段 | 只能是常量 | 可以有实例变量 |
| 继承 | 支持多重继承 | 单继承 |
| 构造函数 | 无 | 有 |
| 设计理念 | “like-a”关系 | “is-a”关系 |
| 状态保存 | 不能 | 能 |
Java 8接口新特性
默认方法(default method):
使用
default关键字定义提供方法实现,实现类可以不重写
解决接口演化问题,保持向后兼容
示例:
1 2 3 4 5
interface MyInterface { default void myMethod() { System.out.println("Default implementation"); } }
静态方法(static method):
接口中可以定义静态方法
必须提供实现,通过接口名直接调用
示例:
1 2 3 4 5
interface MyInterface { static void utilityMethod() { System.out.println("Utility method"); } }
方法调用机制
- invokevirtual vs invokeinterface:
invokevirtual用于调用类方法,可优化(基于虚方法表)invokeinterface用于调用接口方法,性能略低(需搜索方法表)- 基准测试显示
invokeinterface比invokevirtual慢约38%
- 方法分派:
- 静态分派(编译期):方法重载(overloading)
- 动态分派(运行期):方法重写(overriding)
设计原则
- 优先使用接口:
- 提高灵活性,降低耦合
- 支持多实现,避免”脆弱基类”问题
- 示例:
List list = new ArrayList()优于ArrayList list = new ArrayList()
- 避免过度继承:
- 组合优于继承
- 接口可定义角色,类可实现多个角色
- 默认方法冲突解决规则:
- 类中方法优先于接口默认方法
- 子接口默认方法优先于父接口
- 必须显式解决冲突(通过
InterfaceName.super.methodName())
实际应用
- 集合框架:
- 基于接口设计(
Collection,List,Set,Map等) - Java 8新增的
forEach等方法是默认方法
- 基于接口设计(
- 函数式编程:
- Java 8通过接口默认方法支持Lambda表达式
- 示例:
Iterable接口的forEach方法
- API设计:
- 使用接口定义契约
- 通过默认方法提供常用实现
- 通过静态方法提供工具函数
异常
异常基础概念
- 异常定义:
- 异常是程序运行时发生的非正常情况,会中断正常指令流
- 所有异常都继承自
Throwable类,主要分为Exception和Error
- 异常分类:
- Checked Exception(检查型异常):必须处理或声明的异常,如
IOException - Unchecked Exception(非检查型异常):
RuntimeException及其子类,不强制处理 - Error:严重系统错误,如
OutOfMemoryError
- Checked Exception(检查型异常):必须处理或声明的异常,如
异常处理机制
- try-catch-finally:
try块包含可能抛出异常的代码catch块捕获并处理特定类型的异常finally块无论是否发生异常都会执行,常用于资源清理
- 异常声明(throws):
- 方法可以通过
throws声明可能抛出的异常 - 调用者必须处理或继续声明这些异常
- 方法可以通过
- 异常抛出(throw):
- 使用
throw关键字主动抛出异常对象 - 抛出的异常必须是
Throwable或其子类的实例
- 使用
异常处理规则
- 捕获顺序:
- 多个
catch块必须从最具体到最通用排列 - 子类异常必须排在父类异常之前
- 多个
- 方法重写中的异常:
- 子类方法可以抛出与父类相同的异常或其子类
- 可以缩减异常范围或不抛出任何检查型异常
- 不能抛出比父类方法更宽泛或无关的检查型异常
- try-with-resources:
- Java 7引入,自动管理实现了
AutoCloseable接口的资源 - 资源在
try块结束后自动调用close()方法
- Java 7引入,自动管理实现了
异常处理最佳实践
- 异常使用原则:
- 优先使用条件测试替代异常捕获
- 避免过度细化的异常捕获
- 合理利用异常层次结构,选择最匹配的异常类型
- 异常处理准则:
- 禁止异常压制(空的
catch块) - 严格错误检测原则,尽早暴露问题
- 抛出语义明确的异常,避免传递底层非语义化异常
- 合理传递异常,在具备完整上下文信息的层级处理异常
- 禁止异常压制(空的
- 自定义异常:
- 精心设计异常的层次结构
- 异常类应包含足够的信息
- 提供清晰的错误提示
Java 7异常处理新特性
- 多异常捕获:
- 单个
catch块可以捕获多种异常类型,用|分隔 - 捕获的异常类型不能有继承关系
- 单个
- 精确的异常抛出:
- 编译器能更精确地识别抛出的异常类型
- 避免捕获不可能发生的异常类型
- try-with-resources:
- 简化资源管理代码
- 自动处理资源关闭,减少资源泄漏风险
特殊场景处理
- finally中的return:
- 如果
finally块有return语句,会覆盖try或catch中的返回值
- 如果
- 异常消失问题:
finally块中的异常可能掩盖try块中的原始异常- 解决方案:
- 优先保留原始异常
- 使用
addSuppressed()方法记录所有异常
- 异常包装:
- 将底层异常包装为更高层次的业务异常
- 保留原始异常信息,便于问题追踪
底层实现
- athrow指令:
- JVM使用
athrow指令实现异常抛出 - 涉及异常对象创建、初始化和抛出过程
- JVM使用
- 异常表:
- 每个方法都有一个异常表,定义异常处理的范围和处理程序
通过系统化的异常处理,可以提高程序的健壮性和可维护性,同时提供更好的错误诊断信息。
字节码、JVM
详见软工一“JVM和字节码基础”笔记 :
[JVM和字节码基础 HEYWEEN](https://heyween.github.io/posts/JVM和字节码基础/)
结构化编程
自顶向下逐步求精
算法+数据结构
[!Note]
自顶向下逐步求精:
- 从总体到局部:先考虑整体问题,再逐步分解为更小、更具体的子问题
- 层次化分解:将复杂问题分解为多个层次,每一层次都比上一层次更详细
- 逐步细化:通过多次迭代,逐步增加细节,直到问题可以被直接解决
• 树状结构
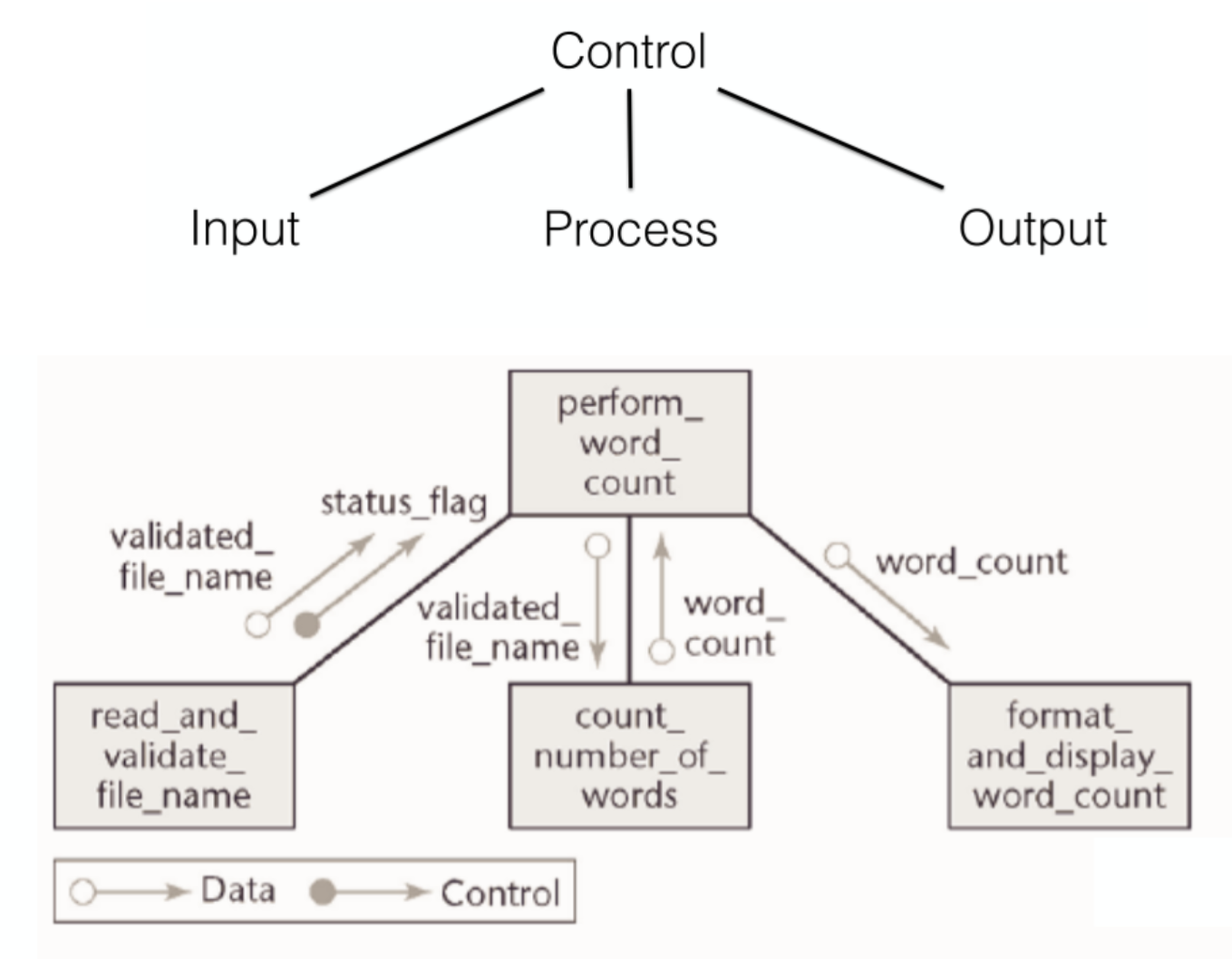
数据流图和结构图
数据流图
将系统看做是过程的集合; 过程就是对数据的处理;
基本符号(一定要标准!!!第一第二种均可)
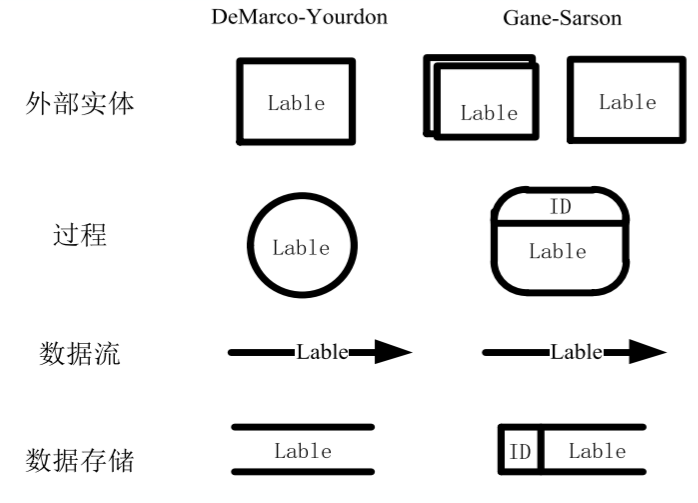
外部实体:数据的生产者或者消费者
过程:数据的处理转换
数据流:通过过程是数据流从输入转换为输出
数据存储:数据有时会被存储起来为以后使用
语法规则
过程是对数据的处理,必须有输入,也必须有输出,输⼊数据集应该和输出数据集存在差异
数据流是必须和过程(必须有过程参与)产生关联的,它要么是过程的数据输入,要么是过程的 数据输出
 过程不一定是程序,可以是任何的能够处理的模块,甚至是人工处理 数据存储不一定是一个文件,可能是文件的一部分,或者是数据库元素等等,它代表静态的数据 数据流代表动态的数据
过程不一定是程序,可以是任何的能够处理的模块,甚至是人工处理 数据存储不一定是一个文件,可能是文件的一部分,或者是数据库元素等等,它代表静态的数据 数据流代表动态的数据
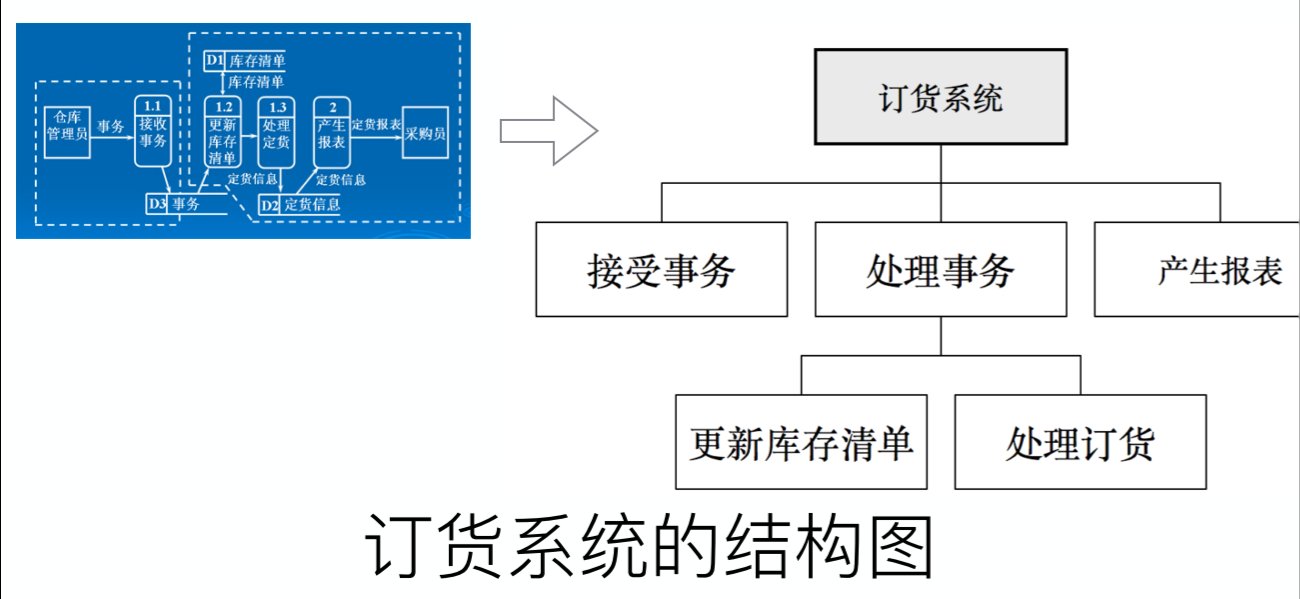
案例一 订货系统
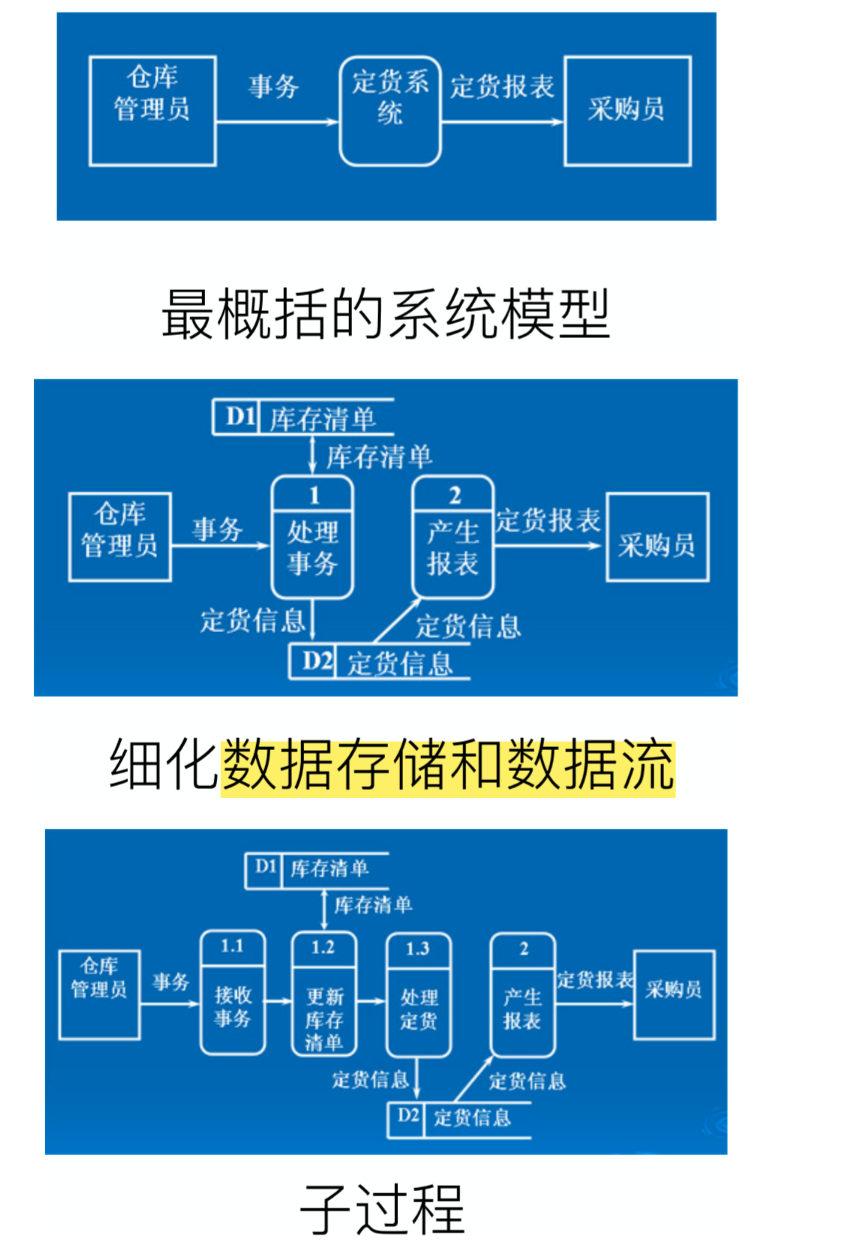
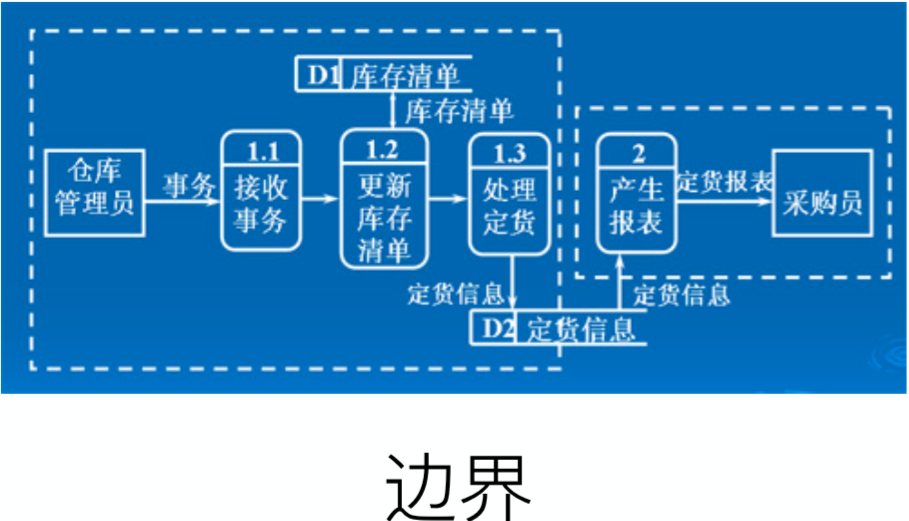
结构图(均使用方框和短线,短线上标注数据的流动)
主要结构为最上层的控制中心,两边的处理所有的输入和所有的输出和中间的处理过程(3个里面需要 具体再细分):