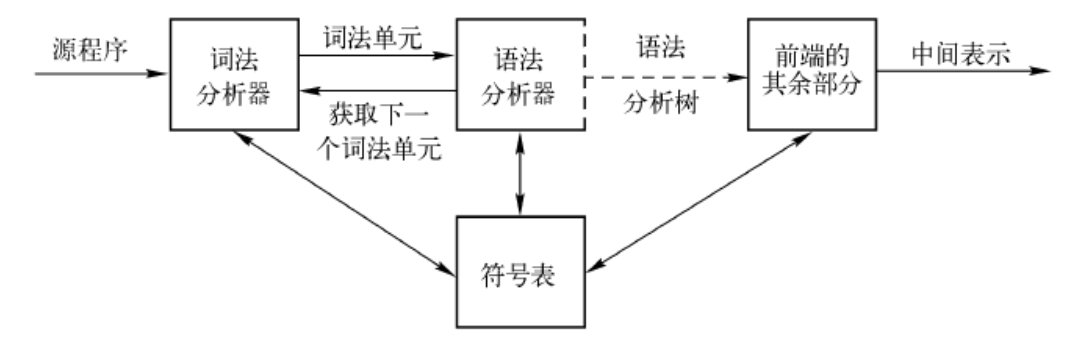
语法分析
语法分析要做什么事?
在词法分析的时候,我们的output是词法单元序列
在语法分析的时候,我们就需要以这种词法单元序列作为input,判断这个由词法单元token作为“字符”的“字符串”能不能由文法生成,如果可以,用生产式把字符串还原成一棵语法树【这棵树就是语法分析的output】
🌰举个栗子:
original input :
a + b * 3— 实际上是字符流output of lexer :
(id, a) (+) (id, b) (*) (num, 3)output of parser :
+ / \ a * / \ b 3
上下文无关文法
语法(syntax):程序的合法结构规则
文法(grammar):用形式化语言来描述这些结构规则
上下文无关文法(Context Free Grammar, CFG)是一种四元组形式的形式文法,通常记作 \(G=(V,Σ,P,S)\)
- $V$ 为非终结符(变量)的有限集合
- $Σ$ 为终结符的有限集合,且 $V∩Σ=∅$
- $S∈V$ 为开始符号
- $P$ 为产生式的有限集合,每个产生式形如 $A→α, A∈V, α∈(V∪Σ)∗$
在 CFG 中,每条产生式的左部只能是单个非终结符,而右部可以是任意长度的终结符与非终结符串
最后,我们就是要把tokens转化为只有终结符的语法树
上下文:在应用一个产生式进行推导时,前后已经推导出的部分结果就是上下文
无关:如果有产生式是$A → γ$,只要看到单个的非终结符A,就可以替换,而不是非得A 处于特定上下文 α、β 之中时,才能被替换为 γ
分析基础
最左推导(Leftmost Derivation):每一步总是展开最左边的非终结符 — 自顶向下
最右推导(Rightmost Derivation):每一步总是展开最右边的非终结符 — 自底向上是最右推导的逆过程
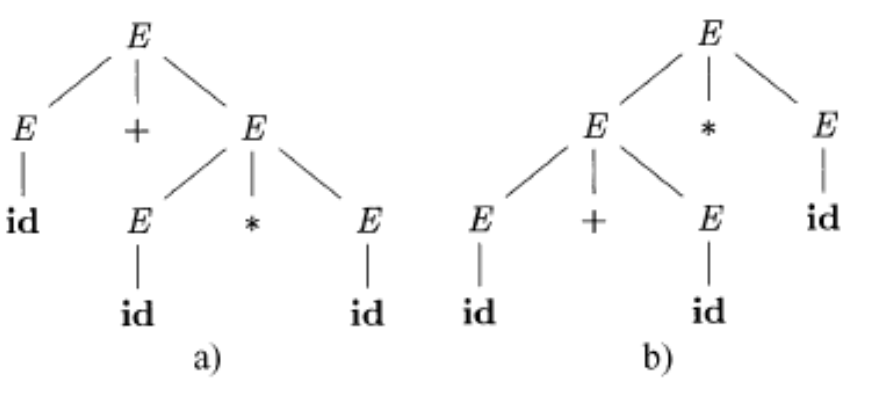
消除二义性
二义性,即文法可以为一个句子生成多棵不同的树
如 id + id * id
消除左递归
左递归:文法中一个非终结符号A使得对某个串α,存在一个推导$A \xrightarrow{+} A \alpha$,则称这个文法是左递归的
在自顶向下的分析中,左递归会导致无限递归!
直接(立即)左递归
即直接存在A → A α
直接左递归改写方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
A → Aα1 | Aα2 | … | Aαm | β1 | β2 | … | βn
step1:分组
A → Aα1 | Aα2 | … | Aαm | β1 | β2| … | βn
--------组1--------- -----组2--------
step2:替换
A → β1 A’ | β2 A’ | … | βn A’
A’ → α1A’ | α2A’ | … | αmA’ | ε
本质上就是:
A → A α | β 替换成:
A → β A'
A' → α A' | ε
注意:必须要有ε,否则无法匹配β
间接左递归
如:
1
2
A → B α
B → A β
算法:
1
2
3
4
5
将非终结符排序 A₁, A₂, ..., Aₙ
for i = 1 to n:
for j = 1 to i-1:
替换 Aᵢ → Aⱼ γ
消除 Aᵢ 的直接左递归
其实就是先消除间接,然后再处理直接
🌰举例:id + id * id
规则:
\[\begin{aligned} E &\to T \, E' \\ E' &\to + \, T \, E' \mid \epsilon \\ T &\to F \, T' \\ T' &\to * \, F \, T' \mid \epsilon \\ F &\to (E) \mid id \end{aligned}\]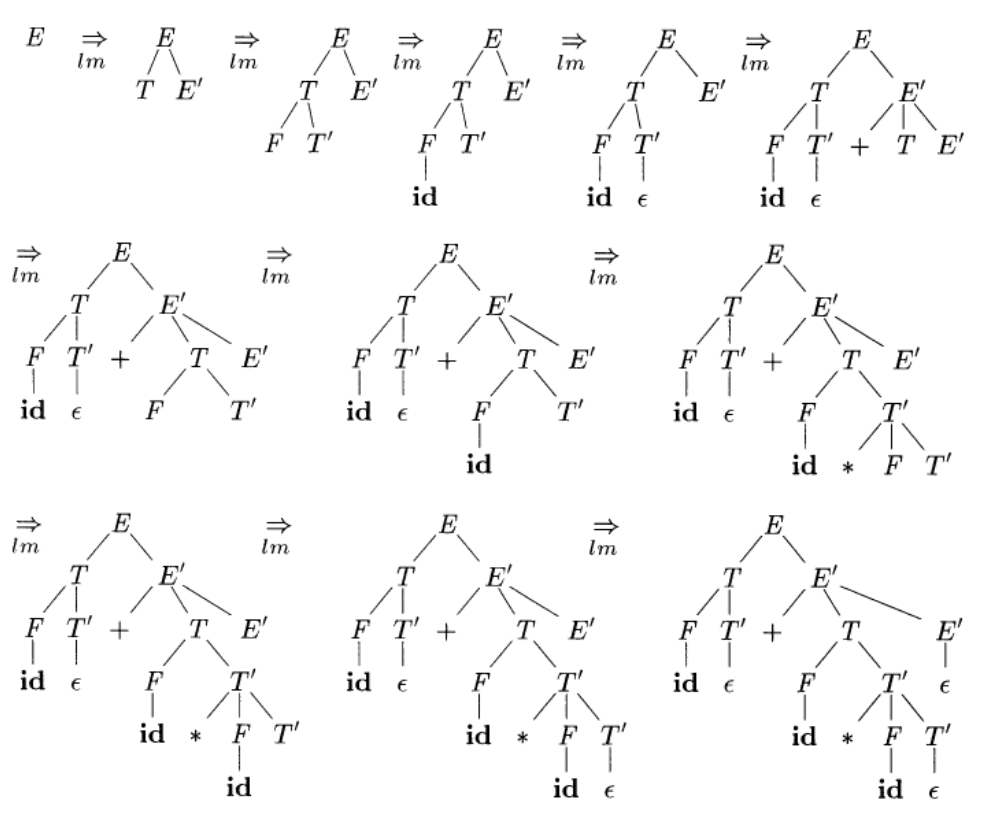
提取左公因子
消除左递归解决的是死循环问题,而提取左公因子解决的是“选不出来”的问题
如果 A → a b | a c,我该怎么判断到底应该选择ab还是ac呢?
很简单,改写一下就好了:
1
2
A → a A'
A' → b | c
本质上就是分层判断
🌰举个例子(dangling else):
1
2
S → if E then S else S
| if E then S
提取后:
1
2
S → if E then S S'
S' → else S | ε
自顶向下的语法分析技术
自顶向下分析可以被看作是为输入串构造语法分析树的问题,也可以看作一个寻找输入串的最左推导的过程
问题: 在推导的每一步,对非终结符号A,应用哪个产生式,以可能产生于输入串相匹配的终结符号串
通用的递归下降分析框架
1
2
3
4
5
6
7
8
9
10
void A() {
选择一个 A 产生式,A → X1 X2 ... Xk;
for ( i = 1 to k ) {
if ( Xi 是一个非终结符号 )
调用过程 Xi();
else if ( Xi 等于当前的输入符号 a )
读入下一个输入符号;
else /* 发生了一个错误 */;
}
}
预测分析法Predictive Parsing — 无回溯!
核心:根据当前输入符号和预测表(Parsing Table,由FIRST + FOLLOW 构造),唯一确定使用哪条产生式
基本要求:文法必须是 LL(1) 文法
有多个可能的产生式时预测分析法无能为力,即:在任意一个非终结符的选择分支中,前瞻符号能唯一确定选择的产生式
LL(1):
第一个L:从左到右扫描输入(Left-to-right)
第二个L:最左推导(Leftmost derivation)
1:只需要一个前瞻符号 Lookahead
核心结构:二维表M[A,a] ,含义:当栈顶为A,当前input为a,该用哪个产生式呢?
三种情况:
1
2
栈顶 X
输入 a
- X是终结符 — X == a → match — 栈弹出,输入前进
- X是非终结符A — 查 M[A, a],如果M[A, a] = A → α — 弹出 A,压入 α(逆序)
- 查不到 — 语法错误
FIRST
对符号串 $ \alpha \in (V \cup \Sigma)^* $:
\[FIRST(\alpha) = \{ a \in \Sigma \mid \alpha \Rightarrow^* a\beta \} \cup \{ \epsilon \mid \alpha \Rightarrow^* \epsilon \}\]特例:
终结符a:FIRST(a)={a}
空串 ϵ:FIRST(ϵ)={ϵ}
递推规则:
- FIRST(a)={a}(a 为终结符);FIRST(ϵ)={ϵ}
- FIRST(A)(A 为非终结符):对每个产生式 A→α,把 FIRST(α)- {ϵ}加入FIRST(A);若 α⇒∗ϵ,再把 ϵ 加入
FOLLOW
对非终结符 ( A ): \(FOLLOW(A) = \{ a \in \Sigma \mid \exists S \Rightarrow^* \alpha A a \beta \} \cup (\{ \$ \} \text{ 若 } A \text{ 能出现在句子末尾})\)
直观理解:能紧跟在A之后出现的终结符集合;起始符号S的FOLLOW 集含输入结束标记 $
递推规则:
- 将 $ 加入 FOLLOW(S)(S 为开始符号)
- 对每个产生式 A→αBβ:
- 把 FIRST(β)- {ϵ} 加入 FOLLOW(B)
- 若 ϵ∈FIRST(β) 或 β=ϵ,把 FOLLOW(A) 加入 FOLLOW(B)
构造预测表
\[SELECT(A \to \alpha) = FIRST(\alpha) \cup \begin{cases} FOLLOW(A) & \text{if } \epsilon \in FIRST(\alpha) \\ \varnothing & \text{otherwise} \end{cases}\]对于一个产生式 A→α,SELECT(A→α)含义:在什么情况下,预测分析表会用这条产生式
为什么用SELECT?
- 在构造预测分析表 M[A, a] 时:对于每一条产生式 A→α,对于所有 a∈SELECT(A→α),填入 M[A,a]=A→α;换句话说,SELECT 集合决定了“当下一个输入符号是 a 时,要不要选择这条产生式”
- LL(1) 的判别条件:文法是 LL(1) 的条件之一就是:对于同一非终结符 A的不同产生式,它们的SELECT集合必须两两不相交,这样,当下一个输入符号是 a 时,表格里只有唯一一条产生式,没有冲突
‼️如果 SELECT 集合有交集 ⇒ 预测表冲突 ⇒ 不是 LL(1)‼️
用 FIRST/FOLLOW 构造 LL(1) 预测表
- 对每个产生式 A→α:
- 对所有 a∈FIRST(α)- {ϵ} :填入 M[A,a]=A→α
- 若 ϵ∈FIRST(α) ,则对所有 b∈FOLLOW(A) :填入M[A,b]=A→α
- 若某表项出现冲突(同一格两条以上产生式),文法非 LL(1)
- 对于LL(1)文法,预测表中每个条目都唯一地指定了一个产生式,或者标明Error
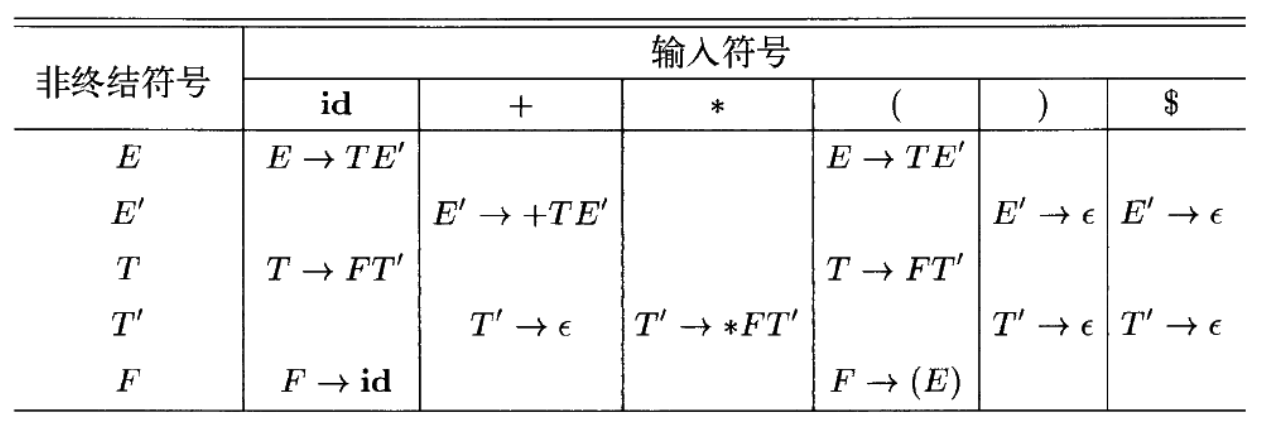
🍐一个完整的例子:
