访问操作系统对象;文件描述符
Everything is a file
文件系统可以用于构建任何信息系统,我们可以把“file” 当作一个可以顺序读写的字节流对象,而不仅仅是磁盘上的文件
FHS
Filesystem Hierarchy Standard FHS: enables software and user to predict the location of installed files and directories
| 路径 | 含义 |
|---|---|
/bin | 基本命令 |
/etc | 配置 |
/home | 用户目录 |
/dev | 设备 |
/proc | 进程信息(虚拟文件系统!) |
文件描述符:访问操作系统对象的 “指针”
我们可以这样简单地去想象一个file:
1
2
3
4
struct FILE {
char *data;
size_t offset;
}
我们可以类比成在 CrazyOS 里允许多个 buffer
- open: f = malloc(sizeof(struct FILE));
- close: free(f);
- read/write: *(f->data++);
- lseek: f-> += offset;
- dup: f_new = f; 👉 dup = 创建一个新的 fd,但指向同一个 file(打开实例)【共享offset和flags】
内核里实际上差不多长这样:
1
2
3
4
5
struct file {
inode *inode;
off_t offset;
int flags; // in which way to operate this file
}
1
int fd = open("a.txt", flags, mode);
fd(file descriptor)实际上不是指针,而是一个整数索引!(当然,我们可以用指针去类比)
在 Unix 和类 Unix 操作系统中,文件描述符是一个非负整数,用于表示一个打开的文件、管道、网络连接或其他类似的资源。当一个程序打开一个文件或创建一个数据流时,操作系统会返回一个文件描述符,程序可以通过这个描述符来读取、写入或操作对应的文件或资源。
1
2
3
4
5
6
fd table (per-process)
fd=0 ──→ file*
fd=1 ──→ file*
fd=2 ──→ file*
fd=3 ──→ file*
所以,read(3, buf, 100);就可以想象成是:fd=3 → 找到 file* → 操作它
当我想要去访问一个file的时候:
1
2
3
4
5
6
7
user: open("a.txt")
↓
kernel: 创建 file 对象
↓
kernel: 找一个 fd(比如 3)
↓
返回 fd=3 给用户
“The open() system call opens the file specified by pathname.”
总结一下,我们获得了这个模型:
1
2
3
4
5
6
7
8
9
10
11
fd(用户态整数)
↓
fd table(进程私有) // 也就是同一个fd,在不同进程里会对应不同file
↓
file*(内核对象:状态 + offset)
↓
具体资源(inode / socket / pipe) // 统一接口,支持不同类型资源
↓
数据来源(page cache / buffer / device)
↓
byte stream
fd = handle(句柄)
如果没有fd,而是直接拿到了struct file *f;,那就完蛋了:
- 可以随便改内核数据
- 可以伪造指针
- 进程之间完全不隔离
file = open instance(打开实例)
file是“一次 open 调用产生的上下文对象”,里面包含:
- 当前读写位置(offset)
- 打开模式(读/写)
- 指向资源的指针(inode/socket)
那为什么不能 fd → resource呢,这是因为“打开”本身是有状态的!“读文件”不是一次性行为,而是一个持续过程(有进度),失去了结构体维护的信息,要么从头读,要么用户自己管理offset!所以offset就是这个“状态”的关键!
stateful就是:输入 + 当前状态 → 输出 + 新状态
fd = open(“a.txt”);,本质上就是在创建一个“读取状态机”(file)!
resource = actual data source(真实资源)
resource是对各种资源的一个抽象,否则将会有很多很多API
另一个 “地址空间”
0 (stdin), 1 (stdout), 2 (stderr), …【每个进程一启动,就已经“自带”了 3 个打开的 fd】
fd 名字 含义 0 stdin 标准输入 1 stdout 标准输出 2 stderr 标准错误 1 2 3 4 5
fd table: 0 ──→ file(stdin) ──→ 键盘 / 输入流 1 ──→ file(stdout) ──→ 终端(屏幕) 2 ──→ file(stderr) ──→ 终端(屏幕)
open() 总是分配最小的未使用描述符
- 新打开的文件从 3 开始分配
- 文件关闭后,编号可以重复利用
fork()
没错,又是fork()!如果我们考虑到fork(),事情就复杂起来了!假设我先fork(),然后再write(),那么到底会运行出一个什么样的结果呢?
为了防止各种诡异的结果出现,设计者选择了浅拷贝:子进程复制 fd table,但 fd 指向的 file(打开实例)是共享的,包括offset!而我们之前说了,offset是决定状态的关键要素,因此,当我们执行:
1
2
3
4
5
6
7
8
9
int fd = open("a.txt", O_RDONLY);
if (fork() == 0) {
// 子进程
read(fd, buf, 5);
} else {
// 父进程
read(fd, buf, 5);
}
实际上的结果是,两个进程共享offset,谁先读,谁推进offset
操作系统的真正复杂性
API 之间会产生互相影响
- fork() 以后,offset 会发生什么?
- 这就是 fork() 看似优雅,实际复杂的地方
- 软件系统的每一处设计都要小心考虑和其他部分的交互
Windows Handle API
- 默认 handle 是不继承的 (和 UNIX 默认继承相反)
- 可以在创建时设置 bInheritHandles,或者运行时修改
- “最小权限原则”
- lpStartupInfo 用于配置 stdin, stdout, stderr
- Linux 引入了 O_CLOEXEC
管道
1
fd → file(pipe) → kernel buffer → file(pipe) → fd
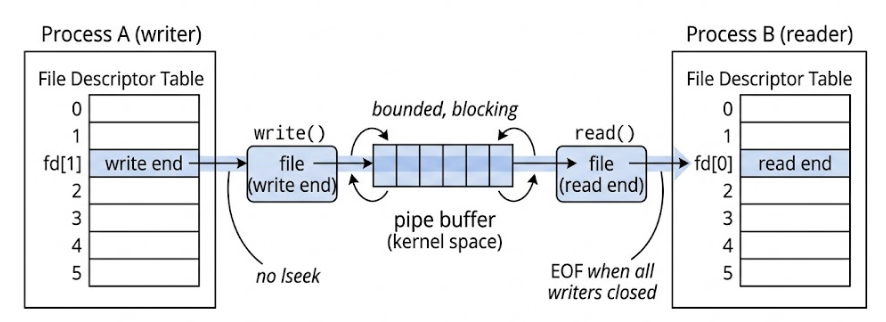
管道 = 内核中的一个“带缓冲区的文件对象”,提供了进程之间通信的机制
- 两边各有一个
file(open instance) - 中间是同一个 buffer(资源)
互相等待(blocking / 阻塞)与同步
写者等待
1
2
3
4
5
6
7
int fd[2];
pipe(fd);
// 父进程写
while (1) {
write(fd[1], buf, 4096);
}
- 如果缓冲区满了,
write会阻塞 - 阻塞时间 = 直到有读端读取数据
读者等待
1
2
3
4
5
int fd[2];
pipe(fd);
// 子进程读
read(fd[0], buf, 1024);
- 如果缓冲区为空,
read阻塞 - 阻塞时间 = 直到写端写入数据 或 所有写端关闭
写者遇到无读者
1
write(fd[1], ...)
- 如果管道的读端全都关闭:
- 内核触发 SIGPIPE
- write 返回错误
EPIPE
- 这是 Unix 的设计保证:不允许写“无人接收的数据”
读者遇到无写者
1
read(fd[0], ...)
- 如果缓冲区空且写端都关闭:
- read 返回 0(EOF)
- 阻塞不会永远等待
普通文件 fork 后的竞争问题
怎么又是你?
1
2
3
4
5
int fd = open("a.txt", O_RDONLY); // 内容:"ABCDEFGHIJ"
fork();
// 子进程:read(fd, 5) → "ABCDE", offset 变为 5
// 父进程:read(fd, 5) → "FGHIJ" (因为 offset 已是 5)
问题:读写顺序取决于进程调度,结果不确定
管道的本质
| 特性 | 普通文件 | 管道 |
|---|---|---|
| offset 共享 | ✅ 是 | ❌ 无 offset 概念 |
| 数据流向 | 双向 | 单向 |
| 数据消费 | 可重复读 | 读一次即删除 |
| 用途 | 持久化存储 | 进程间通信 (IPC) |
1
2
父进程 fd[1] (写) → 内核缓冲区 → 子进程 fd[0] (读)
(数据读完即消失)
因此我们就知道了:
| 问题 | 答案 |
|---|---|
| 管道数据会回流到父进程吗? | ❌ 不会,单向流动 |
| 管道解决文件共享竞争吗? | ❌ 不是,它是 IPC 机制 |
| fork 后 fd 共享导致什么问题? | offset 竞争,结果不确定 |
| 管道如何避免这个问题? | 无 offset 概念,数据单向流动 |