计组概述
什么是计算机?
“通用电子数字计算机”
数字:离散的,非连续的
组织与结构
组织:对编程人员不可见(如:是如何实现乘法指令的,包括控制信号、存储技术)
结构:对编程人员可见(如:字长是16位还是32位;是否有乘法指令【而不是要使用加法指令和循环】)
组织相同,结构不同?—提供不同的指令集
结构相同,组织不同?—提供相同的指令,但实现不同
计算机pick shit
第一代:真空管
冯诺依曼结构:存储程序的思想
基本原则
计算机由运算器、存储器、控制器、输入设备、输出设备组成
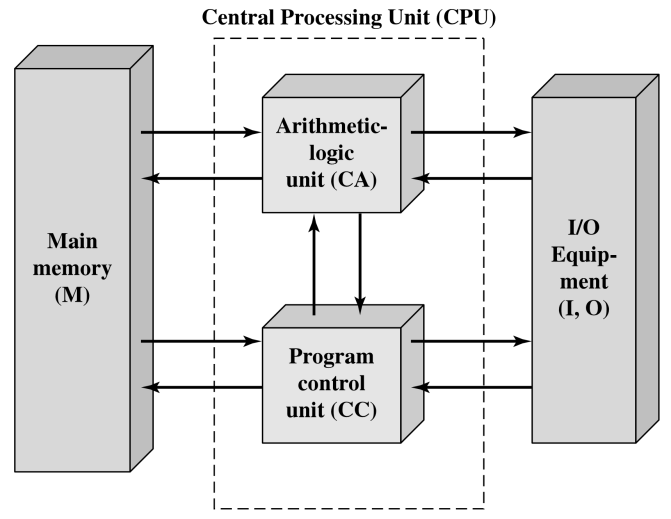
主存储器:地址和存储的内容
算术逻辑单元 / 处理单元:执行信息的实际处理
程序控制单元 / 控制单元:指挥信息的处理【时钟周期 and 取指-译码-执行】
输入设备:将信息送入计算机中
输出设备:将处理结果以某种形式显示在计算机外
存储程序思想(Stored-Program Concept)
一、核心思想:什么是“存储程序思想”?
存储程序思想的精髓可以概括为一句话:
将程序指令和数据一起存储在同一个存储器中,计算机通过自动依次执行存储器中的指令来处理数据。
让我们来拆解这个定义中的几个革命性要点:
- 程序像数据一样被存储:
- 在早期的计算机(如ENIAC)中,程序是通过物理方式(如插拔线缆、设置开关)来设定的,改变程序意味着重新布线,非常麻烦。
- 冯·诺依曼结构下,程序被转换成二进制代码,和待处理的数据一样,被存入内存。这意味着程序变成了可动态改变的“软件”,而不再是固定的“硬件”。
- 指令和数据地位等同:
- 在内存里,你无法从外表区分一段二进制代码到底是指令(告诉CPU做什么)还是数据(被操作的对象)。
- 它们都被一视同仁地存储,都可以被读写。
- 按地址寻址:
- 内存被划分为许多单元,每个单元都有一个唯一的地址。
- CPU通过地址来访问内存,要么取出一条指令,要么读写一个数据。
- 顺序执行(核心执行模式):
- CPU内部有一个关键的寄存器——程序计数器(PC, Program Counter)。
- PC总是保存着下一条要执行的指令的地址。
- CPU的工作流程是一个循环(取指-译码-执行-回写循环):
- 取指(Fetch):根据PC中的地址,从内存中取出指令。
- 译码(Decode):分析这条指令,知道要做什么操作(如加法),操作数在哪里。
- 执行(Execute):执行这个操作(如从内存取数据,在ALU中计算)。
- 回写(Write-back):将结果写回寄存器或内存。
- 执行完一条指令后,PC通常会自动加1,指向下一条指令的地址,从而实现顺序执行。跳转指令(如if、循环)会改变PC的值,打破顺序。
二、如何区分指令和数据?
这是一个非常经典的问题。既然指令和数据混在一起存储,CPU怎么知道它从内存里取出来的是指令还是数据呢?
答案是:由上下文和CPU的执行状态决定,而不是由二进制代码本身决定。
在伟大的PA里,我们说最简单的计算机TRM的工作方式是:
plain text while (1) { 从PC指示的存储器位置取出指令; 执行指令; 更新PC; }
- 取指阶段:
- 当CPU将程序计数器(PC) 中的地址发送到内存时,它期望从该地址取回的是指令。
- 在这个时刻,从数据总线传来的二进制流被CPU当作指令送入指令寄存器(IR),然后进行译码。
- 执行阶段(访存):
- 当CPU执行一条需要从内存读写数据的指令(如
LOAD R1, [1000],意思是将内存地址1000的数据加载到寄存器R1)时,它会将地址1000发送到内存。 - 在这个时刻,从数据总线传来的二进制流被CPU当作数据来处理,并放入指定的寄存器。
- 当CPU执行一条需要从内存读写数据的指令(如
关键区别在于:
- 是PC指向的地址,还是指令中指定的操作数地址?
- CPU在取指周期取回的就是指令,在执行周期的访存操作中取回的就是数据。 同一段二进制数,如果被PC指向,它就是指令;如果被一条指令的操作数指向,它就是数据。
三、冯·诺依曼结构的五大部件
存储程序思想体现在一个由五大部件组成的结构模型中:
运算器(ALU, Arithmetic Logic Unit):负责执行所有的算术和逻辑运算。
控制器(CU, Control Unit):指挥协调其他部件工作,核心是解释执行指令。
注:控制单元在冯·诺伊曼结构中控制的是:
- 指令执行流程(取指、译码、执行)。
- 各部件的协同工作(ALU、寄存器、内存、I/O设备)。
- 数据的流动路径和时机。
- 整个系统的操作时序。
- 对内部异常和外部请求的响应。
存储器(Memory):核心部件,用于统一存储程序和数据。
输入设备(Input Device):将程序和数据输入计算机。
输出设备(Output Device):将处理结果输出。
数据流和指令流都通过同一组总线(Bus)在存储器和CPU之间传输,这也是该结构有时被称为“冯·诺依曼瓶颈”的原因。
四、历史意义与局限性
意义:
- 通用性:使计算机成为通用机器,只需更换存储器中的程序就能解决不同问题,无需重新设计硬件。
- 自动化:实现了程序的自动执行,奠定了软件产业的基础。
- 里程碑:明确了计算机的基本结构,此后的计算机基本都是“冯·诺依曼机”。
局限性(冯·诺依曼瓶颈):
- 共享通路:指令和数据共享同一套总线(数据/地址总线)和存储器。这意味着CPU在一个时钟周期内,不能同时取指令和取数据。
- 性能限制:高速的CPU常常需要等待相对慢速的内存传输指令和数据,限制了系统性能的进一步提升。
现代演变:
为了解决瓶颈,现代计算机采用了大量改进技术,但其核心思想仍未改变:
- Cache(缓存):在CPU和主存之间增加高速小容量缓存,存放最常用的指令和数据。
- 哈佛架构(Harvard Architecture):在核心层面(如CPU内部)使用独立的指令总线和数据总线,可以同时取指和取数。这是冯氏结构的重要演变。很多现代处理器(如ARM)采用了一种“改进型哈佛架构”,在CPU外部共享总线,在内部核心使用独立总线。
第二代:晶体管
把所有真空管换成晶体管,改变的是组织而不是结构
但是组织上的改变会促使结构上的改变
第三代及后续几代:集成电路
摩尔定律(目标而不是规律)
单芯片上所能包含的晶体管数量每年翻一番 (1965-1969)/1970 年起减慢为每 18 个月翻一番
为什么摩尔定律对于软院同学来说很重要?
计算机发展:不变与变
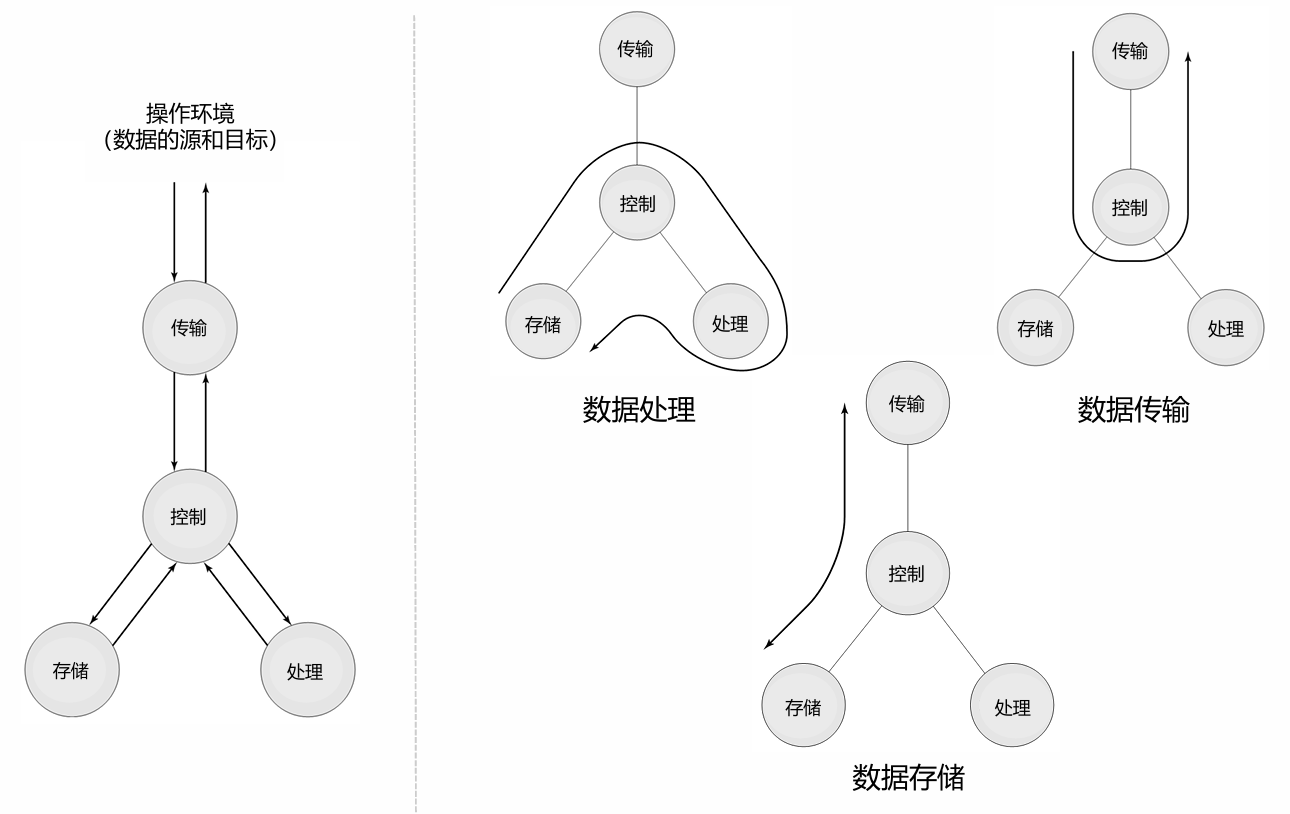
1. 基本功能(不变)
计算机的基本功能始终包括:
- 数据处理:对数据进行运算和转换。
- 数据传输:在计算机内部或与外部设备之间传输数据。
- 数据存储:将数据保存在存储器中供后续使用。
- 控制:协调各个部件的工作。
- 操作环境:提供数据的输入和输出接口。
这些功能是计算机系统的核心,不随技术发展而改变。
2. 运算速度(变化)
计算机的运算速度随着技术的发展显著提升。以下是各发展阶段及其典型速度:
| 发展阶段 | 时间 | 技术 | 典型速度(操作次数/秒) |
|---|---|---|---|
| 1 | 1946–1957 | 真空管 | 40,000 |
| 2 | 1958–1964 | 晶体管 | 200,000 |
| 3 | 1965–1971 | 小/中规模集成电路 | 1,000,000 |
| 4 | 1972–1977 | 大规模集成电路 | 10,000,000 |
| 5 | 1978–1991 | 超大规模集成电路 | 100,000,000 |
| 6 | 1991–现在 | 巨大规模集成电路 | 1,000,000,000 |
计算机性能评价
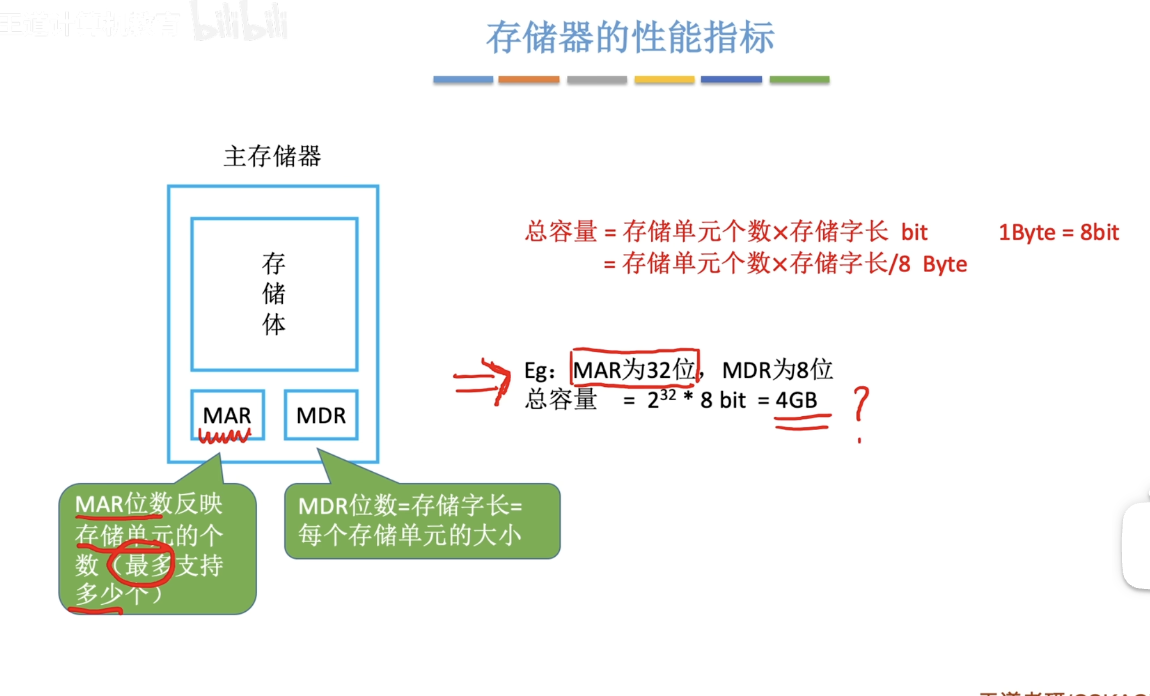
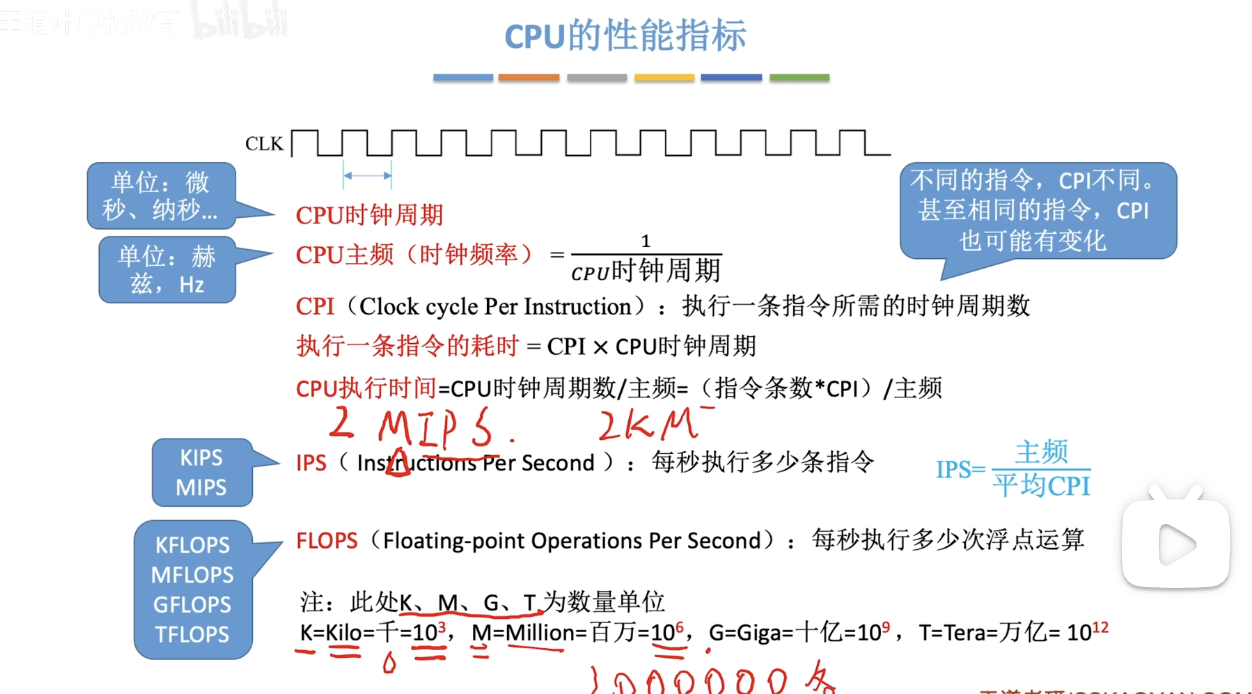
(补充:P:1015)
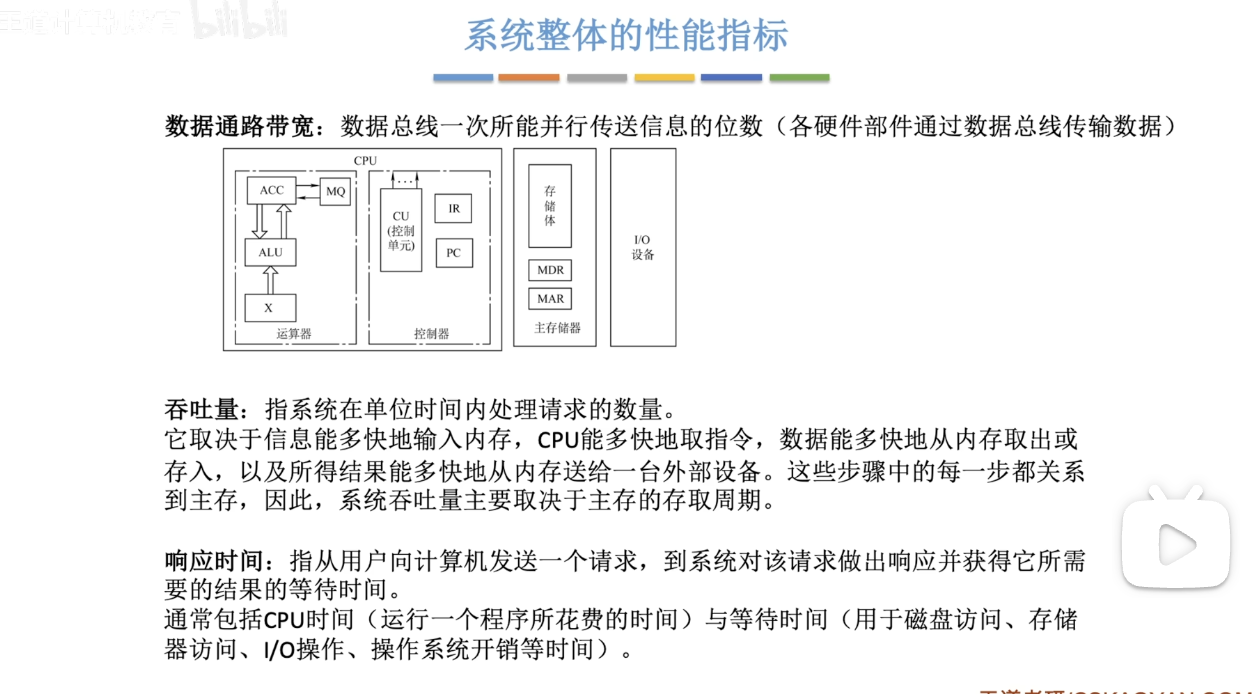
1. 关键性能参数
- 性能:执行任务的速度
- 成本:硬件和软件的成本
- 尺寸:物理大小
- 安全性:系统安全等级
- 可靠性:系统稳定运行的能力
- 能耗:功耗效率
2. CPU性能评价指标
a. 时钟频率与时钟周期
时钟频率(f):单位赫兹(Hz),表示每秒的时钟周期数。
时钟周期(t):每个周期的时间,单位为秒(s),满足: \(t = \frac{1}{f}\)
时钟周期(Clock Cycle)
一、核心概念:什么是时钟周期?
想象一下乐团演奏。指挥家以稳定的节奏挥舞指挥棒,每个节拍都告诉乐手们何时开始演奏下一个音符。时钟周期就是计算机中这个“节拍”。
- 定义:
- 时钟周期是CPU中最小、最基本的时间单位。
- 它是系统时钟(System Clock)发出两个相邻电子脉冲之间的时间间隔。
- 你可以把它理解为CPU工作的“心跳”或“节奏”。
- 单位:
- 通常以纳秒(ns) 或皮秒(ps) 为单位。
- 例如,一个时钟周期为 0.5 ns。
- 与时钟频率的关系:
- 时钟周期(
t)和时钟频率(f,即我们常说的主频,如 3.5 GHz)是互为倒数的关系。二、时钟周期的作用:同步
CPU由数百万甚至数十亿个晶体管组成。为了完成一条指令(比如加法),需要多个部件(取指令、解码、执行、写回结果)协同工作。
- 时钟周期提供了同步信号:它确保所有部件都按照统一的步调操作。在一个时钟周期内,每个部件完成自己那部分微小的、预先设计好的任务。
- 类似于工厂流水线:传送带每移动一次(一个时钟周期),每个工位上的工人就完成一道工序。没有这个统一的节奏,整个流水线就会陷入混乱。
三、时钟周期与指令执行
这是理解CPU性能的核心。
CPI(Cycles Per Instruction):
- 不同的指令需要的工作量不同,因此所需的时钟周期数也不同。
- CPI 就是指执行一条指令平均需要的时钟周期数。
- 例如,一个简单的加法指令可能在1个周期内完成,而一个复杂的除法指令可能需要10个甚至更多周期。
程序执行时间公式: 要计算一个程序运行了多久,可以使用这个核心公式:
T = I_c × CPI × t
T:程序执行的总时间(秒,s)I_c:程序需要执行的指令总条数CPI:执行这些指令的平均时钟周期数t:时钟周期(秒,s)这个公式告诉我们,CPU的性能(程序执行时间
T)由三个关键因素决定:
I_c:软件算法和编译器的影响。好的算法和编译器能生成更短的指令序列。 *CPI:CPU指令集架构(ISA) 和微架构设计的影响。设计高效的CPU核心可以降低CPI。t:半导体工艺和电路设计的影响。工艺越先进,时钟周期t越短,主频f越高。四、举例说明
假设我们有两台电脑,运行同一个程序(
I_c = 10亿条指令)。
- CPU A:主频
f_A = 4 GHz,平均CPI_A = 1.5- CPU B:主频
f_B = 3 GHz,平均CPI_B = 1.0问:哪个CPU更快?快多少?
计算过程:
- 计算时钟周期
t:
t_A = 1 / 4GHz = 0.25 ns
t_B = 1 / 3GHz ≈ 0.333 ns- 计算执行时间
T:
T_A = I_c × CPI_A × t_A = 1e9 × 1.5 × 0.25e-9 = 0.375 秒
T_B = I_c × CPI_B × t_B = 1e9 × 1.0 × 0.333e-9 ≈ 0.333 秒结论:虽然CPU A的主频更高,但因为CPU B的架构更高效(平均每条指令只需1个周期,即CPI更低),所以CPU B的性能反而更好,程序运行时间更短。
这个例子清晰地表明,不能只看主频(时钟频率)来评判CPU性能,必须结合CPI和指令条数综合考量。这就是时钟周期
t在性能模型中的核心意义。总结
概念 定义 符号 单位 意义 时钟周期 CPU工作的基本时间单位 t秒(s), ns, ps CPU的“心跳”,同步所有操作 时钟频率 每秒的时钟周期数 fHz(赫兹) 常说的“主频”, f = 1/tCPI 每条指令所需的平均周期数 CPI周期数/指令 衡量CPU架构效率的关键指标 程序执行时间 运行完程序所需的总时间 T秒(s) T = I_c × CPI × t,性能的最终体现以一个加法操作举例子:
时钟周期 阶段 核心操作 控制单元发出的关键信号 T1 取指 PC -> MAR “地址总线有效” T2 取指 内存读 “内存读”信号 T3 取指 内存 -> 数据总线 (内存控制,CPU等待) T4 取指 数据总线 -> IR, PC+1 “IR写入”, “PC递增” T5 译码 译码指令 (内部逻辑解析) T6 执行 R2, R3 -> ALU输入 “打开R2到ALU通路”, “打开R3到ALU通路” T7 执行 ALU执行加法 “ALU模式=加法” T8 执行 ALU结果 -> R1 “打开ALU到R1通路”, “R1写入”
- 原子性: 每个时钟周期完成一个最基础的、不可再分的硬件操作(如“传送一个数据”、“发出一个信号”)。
- 同步: 所有部件(寄存器、ALU、内存)都在时钟信号的边沿(如上升沿)同步地更新自己的状态。这确保了整个系统步调一致,不会混乱。
- 性能: 执行一条简单指令竟需要8个时钟周期!这就是为什么我们需要提高主频(缩短每个周期的时间)和设计流水线(让取指、译码、执行阶段重叠进行,每个时钟周期都能完成一条指令)来提升性能。
b. CPI(Cycles Per Instruction)
表示执行一条指令所需的平均时钟周期数。
若程序中有多种指令类型,则: \(CPI = \frac{\sum_{i=1}^{n} (CPI_i \times I_i)}{I_c}\) 其中:
- \(I_c\) :总指令数
- \(I_i\) :第 i 类指令的数量
- \(CPI_i\) :第 i 类指令所需的周期数
c. 程序执行时间
\[T = I_c \times CPI \times t\]d. MIPS(Million Instructions Per Second)
\[MIPS = \frac{I_c}{T \times 10^6} = \frac{f}{CPI \times 10^6}\]e. MFLOPS(Million Floating Point Operations Per Second)
\[MFLOPS = \frac{N_{floating-point \, op}}{T \times 10^6}\]3. 基准程序(Benchmark)
用于测量系统性能的标准程序集。
算术平均值: \(R_A = \frac{1}{m} \sum_{i=1}^m R_i\)
调和平均值(更适合衡量速率类指标): \(R_H = \frac{m}{\sum_{i=1}^m \frac{1}{R_i}}\)
性能设计的基本原则
1. 大概率事件优先原则
- 对最常见的事件(高频率发生的事件)优先优化,以获得最大的整体性能提升。
2. Amdahl定律
系统性能提升的上限受限于被优化部分在系统中的占比。
公式: \(S = \frac{1}{(1 - f) + \frac{f}{k}}\) 其中:
- \(S\) :系统加速比
- \(f\) :可优化部分所占比例
- \(k\) :该部分性能提升的倍数
含义:即使某部分性能提升极大(\(k \to \infty\)),系统整体加速比也不会超过 \(1−\frac{1}{1 - f}\)。
计算机的顶层视图
计算机工作原理
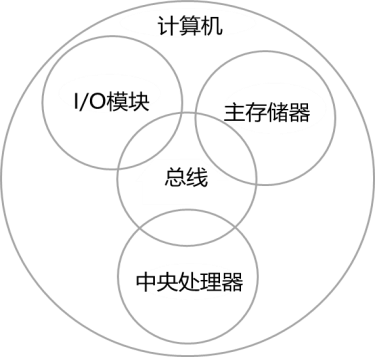
- 指令和数据存储在单个读写存储器中
- 主存中的内容按位置访问,无需考虑其中包含的类型
- CPU从一条指令到下一条指令以顺序方式执行,除非明确修改
- I/O模块与CPU、主存交换计算机系统外部的数据
不成比例扩展效应指的是:在计算机系统中,当某个部件(如CPU)的性能得到显著提升时,其他相关部件(如内存、硬盘、总线)的性能并未以同等比例提升,从而导致系统整体性能的提升幅度远低于该部件自身的提升幅度。
简单来说就是:一条腿跑得快,另一条腿跟不上,整体速度还是被慢腿拖累了。
这个效应是Amdahl定律(阿姆达尔定律) 在硬件层面的一个具体体现和延伸。Amdahl定律指出:系统优化后的整体加速比,受限于被优化部分在原系统计算时间中所占的比例。
例:CPU与内存的速度鸿沟
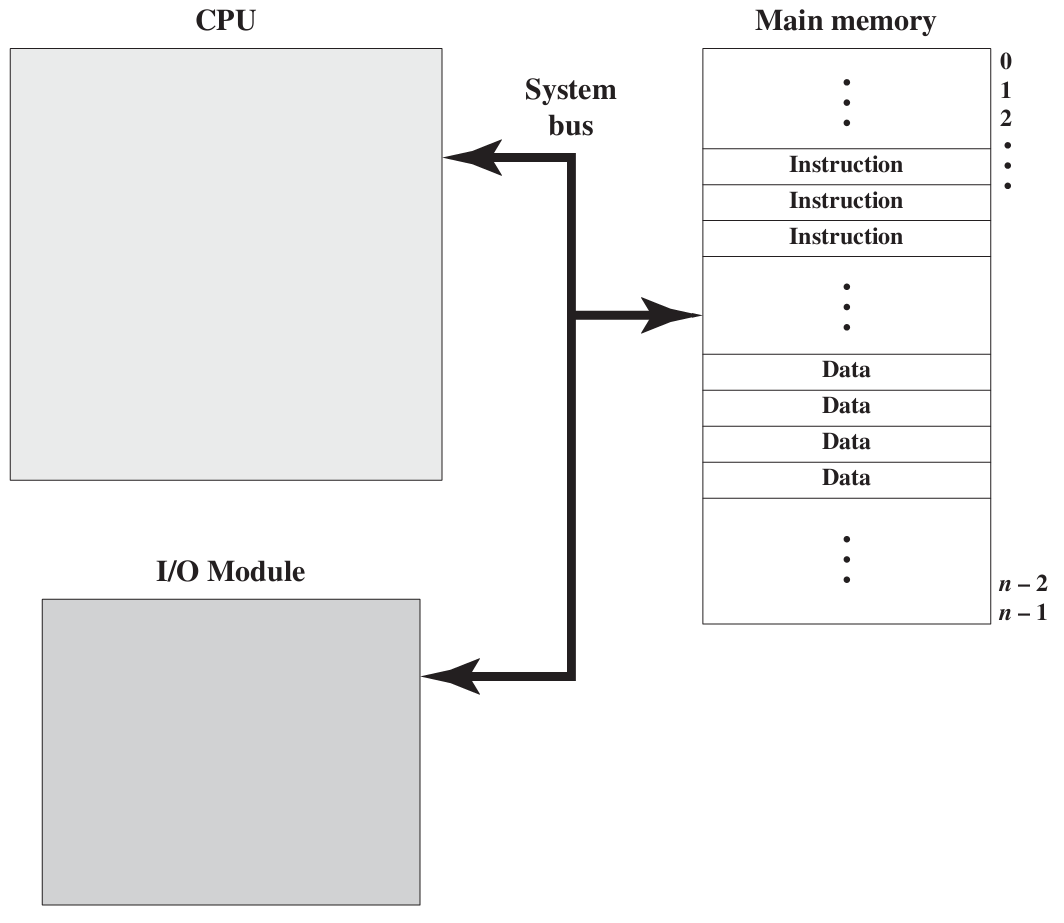
核心问题与解决方案详解
问题1:CPU的频率不能无限提高
- 问题描述:
- 理论限制:晶体管开关、信号传输均需要时间,时钟脉冲必须持续足够长以保证同步。
- 物理限制:芯片面积增大导致连线延迟显著;频率越高,功耗和散热越大(功耗墙)。
- 解决方案:改进CPU芯片结构
- 不再单纯追求提高主频,而是通过改变内部架构来提升效率。
- 关键技术:指令流水线(Instruction Pipelining)、多核(Multi-core)、超标量(Superscalar)等架构技术,旨在在每个时钟周期内完成更多工作,而非无限缩短周期时间。
- 对应章节:第14讲(指令周期和指令流水线)
问题2:内存墙(Memory Wall)的存在
- 问题描述:
- CPU处理速度(逻辑)的增长速度远快于主存(DRAM)访问速度的增长。
- 高速CPU需要花费大量时间“等待”慢速的内存传送数据和指令,性能被严重浪费。
- 解决方案:采用高速缓存(Cache)
- 在CPU和主存之间加入一小块高速静态RAM(SRAM) 作为缓存。
- 原理:利用局部性原理,将CPU近期可能访问的数据副本存放在Cache中。CPU优先访问Cache,大幅减少访问主存的次数。
- 增强措施:增大总线数据宽度,一次传输更多数据。
- 对应章节:第9讲(高速缓冲存储器)
问题3:CPU等待I/O传输数据
- 问题描述:
- I/O设备(如磁盘、键盘)速度极慢,与CPU速度差距巨大。
- 如果采用程序控制I/O( polling),CPU必须不断查询设备状态,导致在等待I/O时保持空闲,效率极低。
- 解决方案:采用中断机制(Interrupt)
- 机制:I/O设备完成工作后,主动向CPU发出中断信号。CPU收到信号后,暂停当前程序,转去执行处理该I/O事件的程序(中断服务例程),处理完毕后再返回原程序继续执行。
- 优势:CPU在I/O操作期间可以执行其他任务,极大地提高了利用率。
- 高级形式:多重中断(处理中断时允许被更高优先级的中断打断)。
- 对应章节:第13讲(指令系统)、第17讲(输入/输出)
问题4:兼顾存储容量、速度和成本
- 问题描述:
- 需求矛盾:需要存储器同时具备大容量、高速度和低成本。
- 技术现实:存储技术存在铁三角关系——访问时间越短(速度越快),每比特成本越高,容量也越难做大。
- 解决方案:层次式存储结构(Memory Hierarchy)
- 思想:不依赖单一存储部件,而是构建一个由多级存储器组成的金字塔形层次体系。
- 组成:
寄存器 → L1 Cache → L2 Cache → L3 Cache → 主存 (DRAM) → 固态硬盘 (SSD) → 机械硬盘 (HDD) → ... - 效果:从CPU角度看,拥有一个容量近似最大、速度近似最快、成本近似最低的存储系统。系统自动将频繁访问的数据放在高层。
- 对应章节:第8讲(内部存储器)、第9讲(Cache)、第10讲(外部存储器)、第12讲(虚拟存储器)
问题5:I/O设备传输速率差异大
- 问题描述:
- 不同I/O设备速度差异巨大(从键盘鼠标到千兆网卡),且都远慢于CPU和内存。
- 解决方案:采用缓冲区和改进I/O操作技术
- 缓冲区(Buffer):在I/O模块或内存中开辟一块临时存储区。数据先成块传入缓冲区,再统一处理,平滑速度差异,避免CPU频繁等待。
- 改进技术:包括程序中断I/O、直接存储器访问(DMA)(I/O设备与主存直接交换数据,无需CPU介入)、专用I/O处理器(通道) 等。
- 对应章节:第17讲(输入输出)
问题6:计算机部件互连复杂
- 问题描述:
- 早期计算机采用专线互连(如IBM 7094),每个部件间都有单独线路,导致系统结构极其复杂、混乱、难以扩展和维护。
- 解决方案:采用总线(Bus)
- 思想:使用一组共享的通信通路来连接所有系统组件。
- 优势:极大地简化了物理布局和控制系统,提高了模块化和可扩展性。
- 总线分类:
- 数据总线:在各模块间传送数据。
- 地址总线:指定数据读写的源或目标地址。
- 控制总线:传送控制信号(读/写、中断、时钟等)。
- 对应章节:第16讲(总线)
补充(基于作业):
【2020 统考真题】下列给出的部件中,其位数(宽度)一定与机器字长相同的是( )。 I.ALU II .指令寄存器 III .通用寄存器 IV .浮点寄存器 A. 仅 I、II B. 仅 I、III C. 仅 II 、III D. 仅 II 、III 、IV
机器字长是指 CPU 内部用于整数运算的数据通路的宽度。 CPU 内部数据通路是指 CPU内部的数据流经的路径及路径上的部件,主要是 CPU 内部进行数据运算、存储和传送的部件,这些部件的宽度基本上要一致才能相互匹配。因此,机器字长等于 CPU 内部用于整数运算的运算器位数和通用寄存器宽度。因此答案是B。
概念解释
机器字长
- 定义:CPU 一次能处理的二进制数据的位数,通常指 整数运算时数据通路的宽度。
- 例如:32 位机器、64 位机器,这里的“位”就是指机器字长。
- 它决定了 CPU 内部 整数 ALU、通用寄存器、数据总线(CPU 内部) 的宽度。
对各部件的分析
I. ALU(算术逻辑单元)
- ALU 负责整数算术和逻辑运算。
- 它的输入来自通用寄存器,输出也要存回通用寄存器或暂存器。
- 为了匹配通用寄存器的宽度,ALU 的位数(指整数 ALU)一般等于机器字长。
- 注意:现代 CPU 可能还有专门用于地址运算的加法器、向量 ALU 等,但 通常说 ALU 指整数运算核心部件,宽度与机器字长相同。
结论:I 与机器字长相同。
II. 指令寄存器
- 存放当前正在执行的指令的寄存器。
- 其长度取决于 指令格式的长度,不一定等于机器字长。
- 例如:32 位机器上,一条指令可能是 16 位、32 位、甚至 64 位(RISC-V 等有变长指令集),指令寄存器要能存放最长的指令,不一定等于机器字长。
- 在很多 RISC 中,指令长度固定(如 32 位),但机器字长可能是 64 位,此时指令寄存器位数 ≠ 机器字长。
结论:II 不一定与机器字长相同。
III. 通用寄存器
- 用于存放数据和地址,CPU 整数运算时直接使用的寄存器。
- 其宽度与机器字长相同,因为它们是整数运算的数据存放单元。
- 例如:x86 中 EAX(32 位)、RAX(64 位)的宽度就是机器字长。
结论:III 与机器字长相同。
IV. 浮点寄存器
- 专门用于浮点数计算。
- 其宽度遵循浮点数标准(IEEE 754),例如单精度 32 位、双精度 64 位,不与机器字长绑定。
- 例如:32 位 CPU 上可以有 64 位双精度浮点寄存器;64 位 CPU 上浮点寄存器可以是 80 位(x87)。
结论:IV 不一定与机器字长相同。