线程
REVIEW:进程
首先,我们为什么需要“进程”
这是个老生常谈的问题,古早的计算机,一次只跑一个程序。程序从头跑到尾,独占所有内存和 CPU。这会带来两个问题:
问题 1:资源浪费。程序在等磁盘、等网络的时候,CPU 完全空闲。
问题 2:不安全。两个程序同时跑,一个写坏了内存,另一个也跟着崩。
所以这就引到了我们最熟悉的那句话:给每个程序一个”幻觉”——让它以为自己独占整台机器。这个幻觉的载体,就是进程。
所以进程并不仅仅是”运行中的程序”这么简单。它是操作系统构建的一个隔离容器,里面装着程序运行所需的全部资源视图。
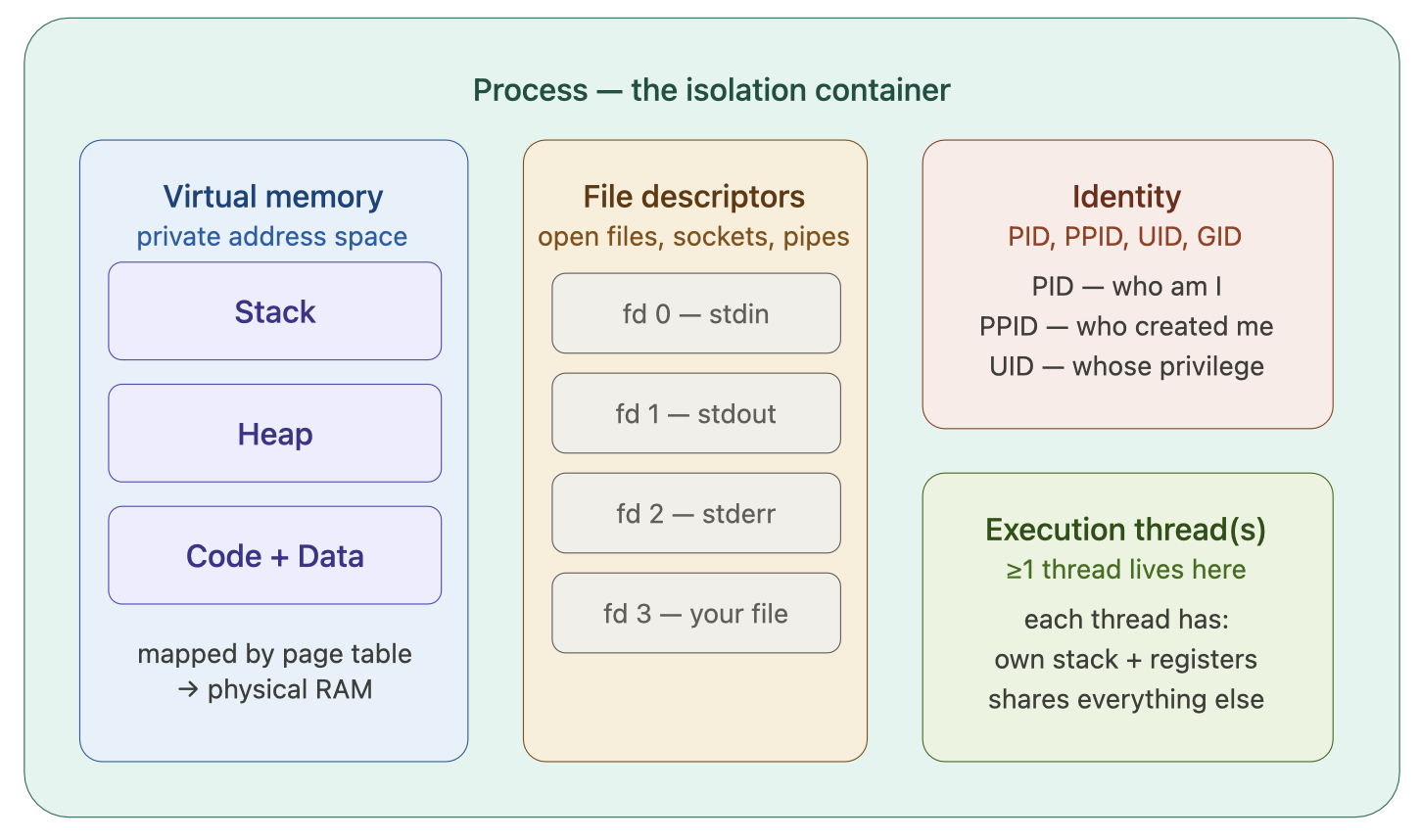
注意我们的措辞:进程是资源的所有者,但是进程本身不跑!真正跑起来的是进程里的线程!
线程
进程解决了隔离问题,但是我们去思考一个问题:假设有一个下载器,如果主界面需要相应用户点击,同时后台在下载文件,那下载的时候,界面就会卡死!
朴素解法:fork()
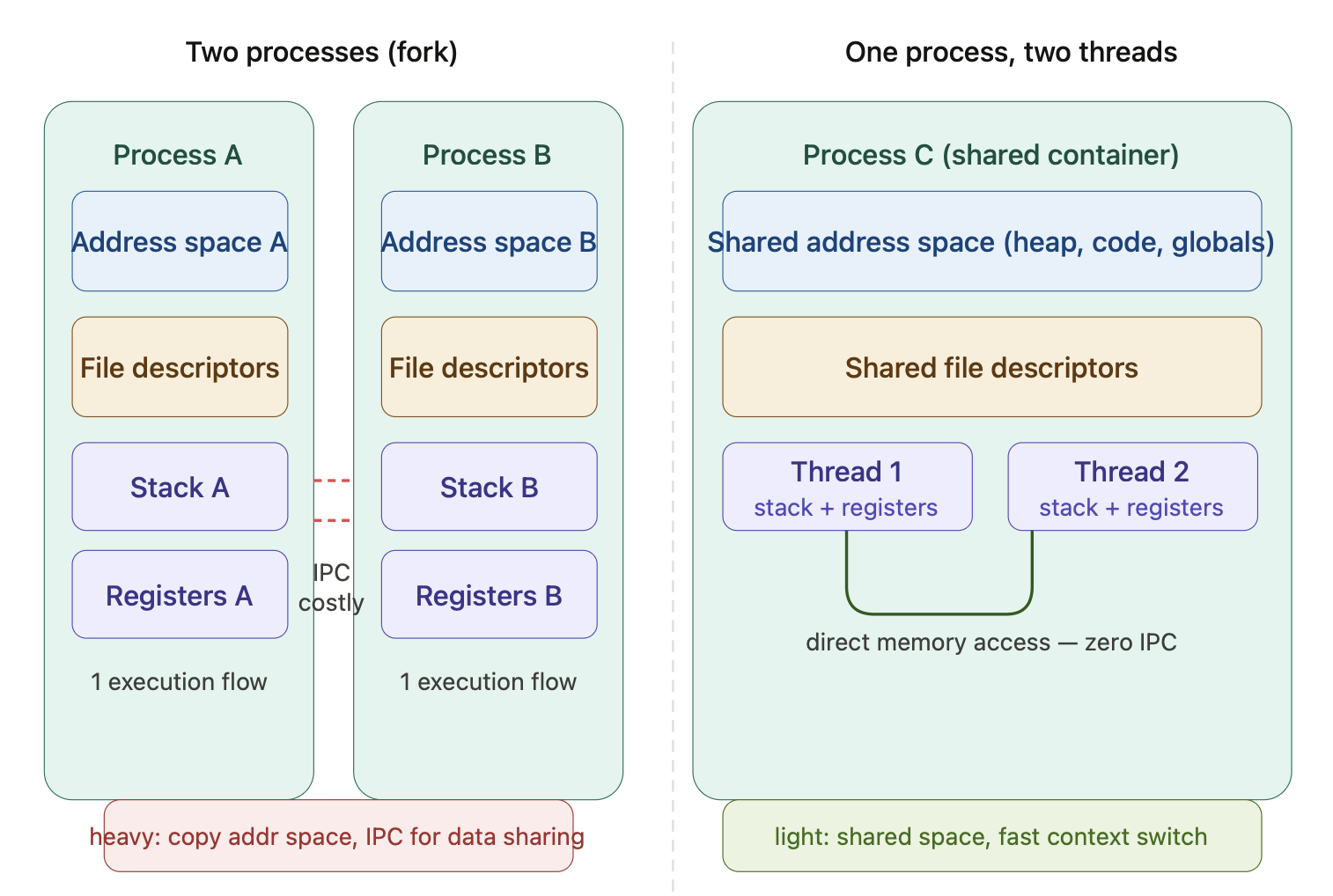
但是太朴素了,因为:fork() 会复制父进程的整个地址空间(虚拟内存映射、文件描述符表……),这个操作很重。更糟的是,两个进程想共享数据很难——它们的地址空间是隔离的,通信必须走 IPC(管道、共享内存、socket 等),又慢又复杂。
线程的关键思想:在同一个进程内,开多条执行流,让它们共享地址空间和资源,但各自有独立的栈和寄存器状态。
task_struct
Linux 没有在内核里分别实现”进程管理”和”线程管理”两套系统。它问了一个更深的问题:
进程和线程本质上有什么共同点?
答:它们都是可被调度的执行流,只是共享资源的程度不同。
于是 Linux 的设计是:用同一个数据结构 task_struct 描述一切,用 clone() 的参数控制”共享多少”。
1
2
3
4
5
6
7
8
9
// 创建"进程":几乎不共享任何东西
fork()
// 等价于:
clone(SIGCHLD, ...)
// 创建"线程":共享地址空间、文件、信号等
pthread_create()
// 等价于:
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, ...)
CLONE_VM 这个 flag 的含义就是:新 task 和父 task 共用同一个 mm_struct(虚拟地址空间),而不是复制一份新的。
这个设计的深层含义:进程和线程的区别,只存在于用户的概念里。在内核调度器眼中,它只看到一个个 task_struct,平等地放进 run queue,平等地被调度。
线程私有什么,共享什么?
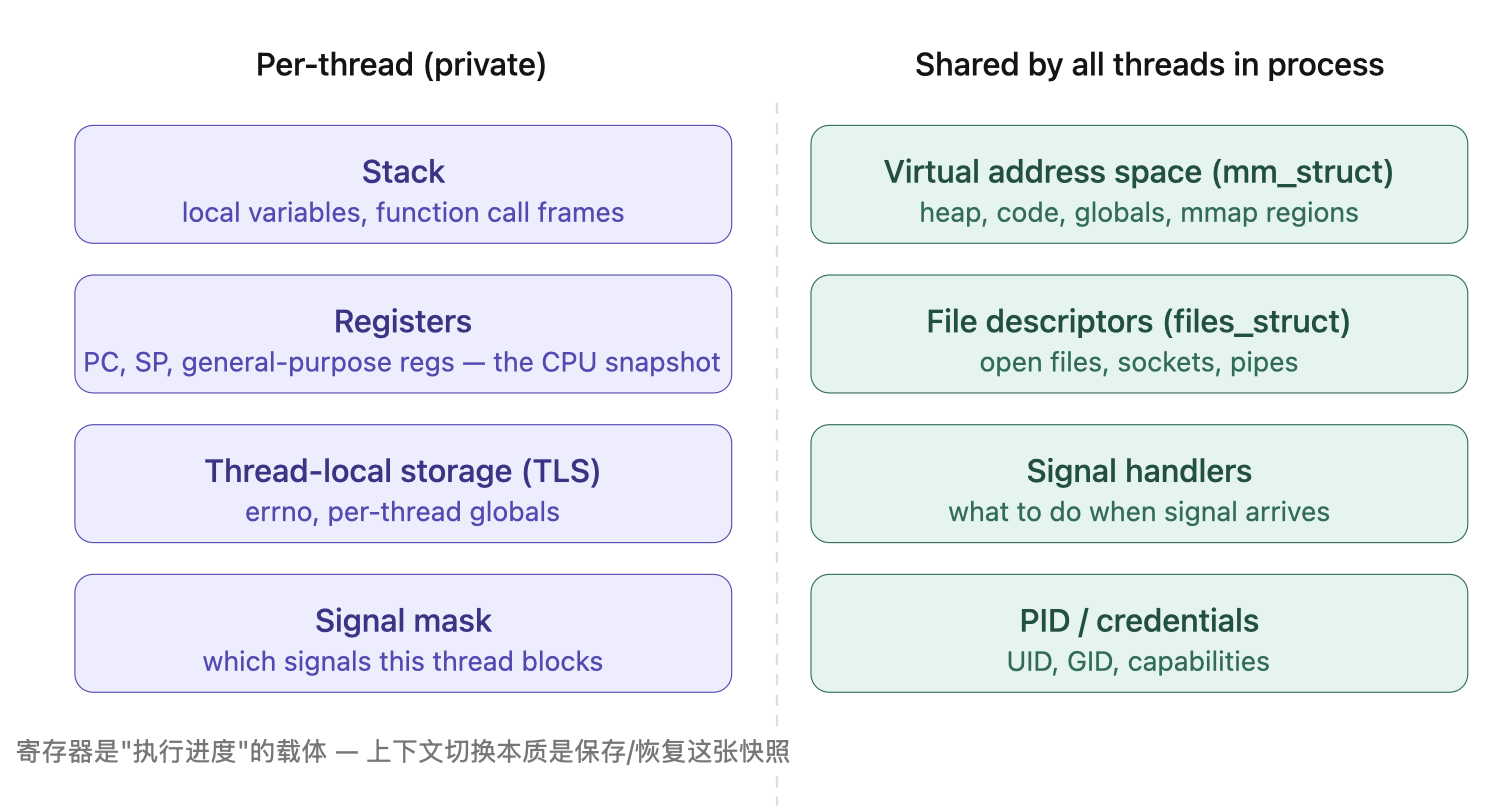
为什么寄存器必须是私有的?
寄存器保存的是”当前执行到哪里了”——程序计数器 PC 指向下一条要执行的指令,栈指针 SP 指向当前栈顶。如果两个线程共享寄存器,它们根本没法同时存在于不同的执行位置。寄存器的私有性,是并发执行成为可能的前提。
上下文切换的本质
1
2
3
4
5
6
7
8
Thread A 正在跑
↓ 时间片到 / 发生中断
1. 把 A 的所有寄存器状态保存到 A 的 task_struct->thread_struct
2. 从 B 的 task_struct->thread_struct 恢复 B 的寄存器
3. 如果 A 和 B 属于不同进程:还要切换 mm_struct(刷 TLB,这很贵!)
4. 如果 A 和 B 属于同一进程(即线程切换):跳过步骤 3
↓
Thread B 开始跑,从它上次停下的地方继续
这就是线程切换比进程切换快的根本原因:同进程内的线程切换不需要切换地址空间,省掉了 TLB 刷新(TLB 是 CPU 缓存页表映射的硬件,刷掉意味着之后的内存访问都要重新查页表,代价很大)。
共享带来便利,也带来危险。
线程的代价:
共享地址空间意味着一个线程可以踩坏另一个线程的数据,而两个进程之间做不到这一点(地址空间隔离保护了它们)。所以多线程编程需要锁、原子操作、内存屏障……这是一整套复杂的并发控制体系。
一个常被忽视的点:
Linux 的线程在内核里没有”线程 ID”这个概念——它有的是
pid(内核调度用)和tgid(thread group ID,等于进程的 PID)。ps命令默认显示的 PID 对应的是tgid,这就是为什么你用ps看一个多线程进程,只看到一行,但用ps -L才能看到所有线程。
| 维度 | 进程 | 线程 |
|---|---|---|
| 内核数据结构 | task_struct | task_struct(完全相同) |
| 创建方式 | fork() / clone(少量flags) | clone(CLONE_VM, ...) |
| 地址空间 | 独立(mm_struct 复制) | 共享(同一个 mm_struct) |
| 切换代价 | 高(需刷 TLB) | 低(无需切换地址空间) |
| 通信方式 | IPC(管道、共享内存等) | 直接读写共享内存 |
| 隔离性 | 强(崩溃不互相影响) | 弱(一个崩全进程崩) |
| 调度器视角 | 一个 task | 一个 task(无区别) |
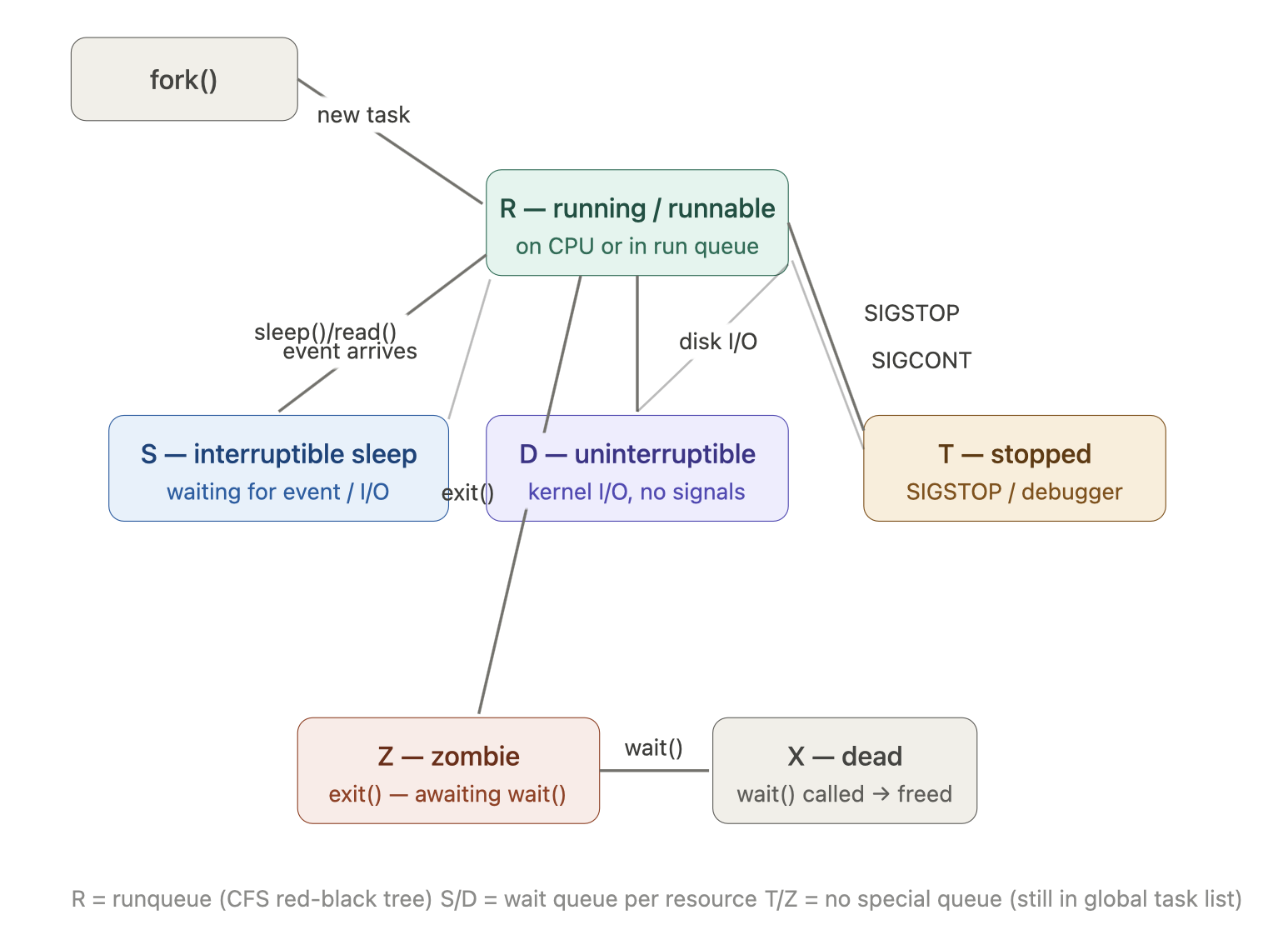
进程状态机
❌ “状态是进程的感受,进程’决定’进入某个状态”
✅ 状态是
task_struct->state字段的当前值,由内核在特定事件发生时修改你永远不会看到用户代码写
my_state = SLEEPING。状态转换是内核行为,用户代码只能通过系统调用间接触发它。
运行态 R:有资格使用 CPU
调度器需要知道:现在哪些 task 可以被放上 CPU? R 状态就是这个问题的答案——所有 R 状态的 task 构成”候选池”。
R 状态实际上包含两种情况,内核用同一个值表示:
1
2
3
4
R = TASK_RUNNING = 0
情况1:正在某个 CPU 核上执行 → "running"(运行态)
情况2:在 run queue 里等待被调度 → "runnable"(就绪态)
为什么合并成一个状态? 因为从调度器的角度,这两种情况没有本质区别——task 随时可以被放上 CPU,不需要等待任何外部事件。区分它们需要额外的每核数据结构,收益很低。
R 状态 task 住在哪里?
每个 CPU 核有一个独立的 run queue(struct rq)。普通进程用 CFS 调度器,内部是一棵以 vruntime(虚拟运行时间)为键的红黑树,vruntime 最小的 task 最先被调度。
1
2
3
4
5
CPU 0 的 run queue
├── 红黑树(CFS,普通进程)
│ 左子树 vruntime 小 → 优先调度
└── 优先级数组(RT,实时进程)
100个优先级链表,严格按优先级
关键设计:每个 CPU 独立维护 run queue,避免多核竞争同一把锁。这是性能优先的工程选择。
睡眠态 S/D:等待某个事件
它解决什么问题?
进程经常需要等待——等磁盘读完、等网络包到达、等用户输入。如果等待时仍然占着 R 状态,调度器就会不停地把它放上 CPU,然后发现没数据,再换下来——这叫忙等待(busy waiting),纯粹浪费 CPU。
睡眠态的设计是:把 task 从 run queue 里摘出去,等事件发生时再放回来。
S 和 D 的区别:能不能被信号打断
这是一个有意的设计选择,不是技术限制。
1
2
S = TASK_INTERRUPTIBLE 可中断睡眠
D = TASK_UNINTERRUPTIBLE 不可中断睡眠
D 状态最容易被误解的地方:SIGKILL 也杀不掉 D 状态的进程,这让很多人以为是 bug。实际上这是内核的一个正确性保证。想象进程正在向磁盘写一个数据库事务的中间状态,如果这时强制中断,文件系统可能损坏。D 状态告诉你:”等我把这件事做完,再来处理信号。”
D 状态持续太久怎么办? 通常意味着硬件问题(磁盘挂了、NFS 服务器无响应)。这时 ps 里会出现大量 D 状态进程,系统负载飙高,但 CPU 使用率接近 0——这是经典的 I/O 卡死现象。
睡眠态 task 住在哪里?
这是一个常见误区:
❌ “内核有一个全局的睡眠队列”
✅ 睡眠 task 挂在具体资源/事件的等待队列上
1
2
3
等待 socket 数据 → 挂在该 socket 的 wait_queue 上
等待某个锁 → 挂在该锁的 wait_queue 上
等待磁盘块 → 挂在该块设备的 wait_queue 上
设计动机:如果所有睡眠进程都在一个全局队列里,每次任何事件发生都要线性扫描整个队列——O(n) 的唤醒代价。把等待队列绑定在资源上,唤醒时只通知等待这个资源的那些 task,精准高效。