第一講:一堂課搞懂生成式人工智慧的技術突破與未來發展
第一講:一堂課搞懂生成式人工智慧的技術突破與未來發展
生成式人工智能基本原理:输入一个x,输出一个y
通过有限的选择组合出近乎无穷的可能
基本单位叫token
基本策略:每次只生成一个token yi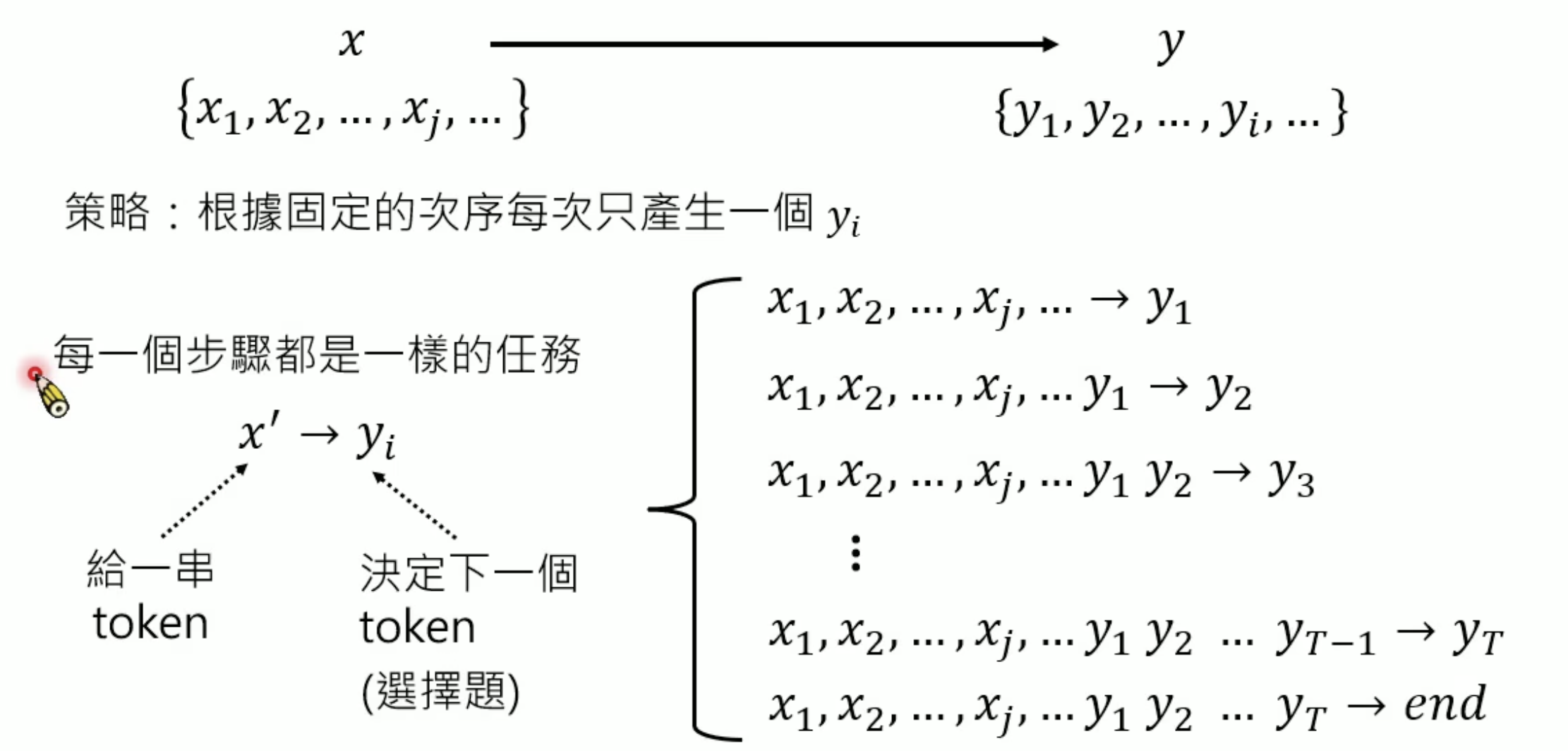 \(\{ z_1, z_2, z_3, \dots, z_{t-1} \} \rightarrow z_t\)
\(\{ z_1, z_2, z_3, \dots, z_{t-1} \} \rightarrow z_t\)
类神经网络:本质上是一个function,产生的是一个token的概率分布,给每一个token一个分数
把一个函数分成多个串联的layer—“深度”的含义
把一个问题拆成多个步骤是有用的—复杂问题简单化
让机器思考是有用的—困难的问题需要很多步,layer是有限的—“深度不够,长度来凑”—Testing Time Scaling
残暴的控制输出长度的方法:每一次语言模型产生end的时候,就直接换成wait
ALBERT
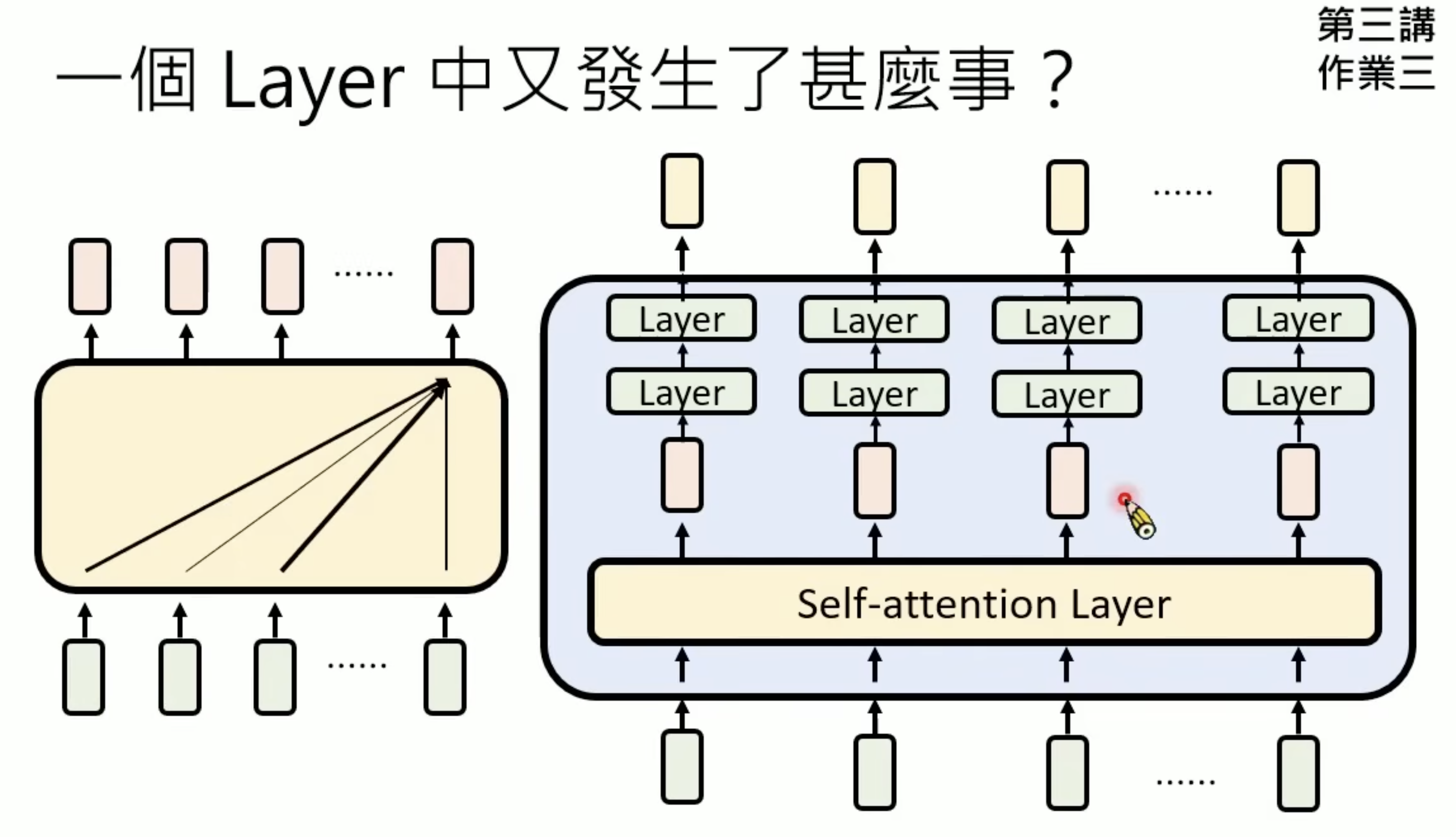
self-attention layer:考虑全部输入再产生输出
只针对单点作深入的思考
Transformer很难处理很长长度的输入
这些运作机制是怎么产生出来的?
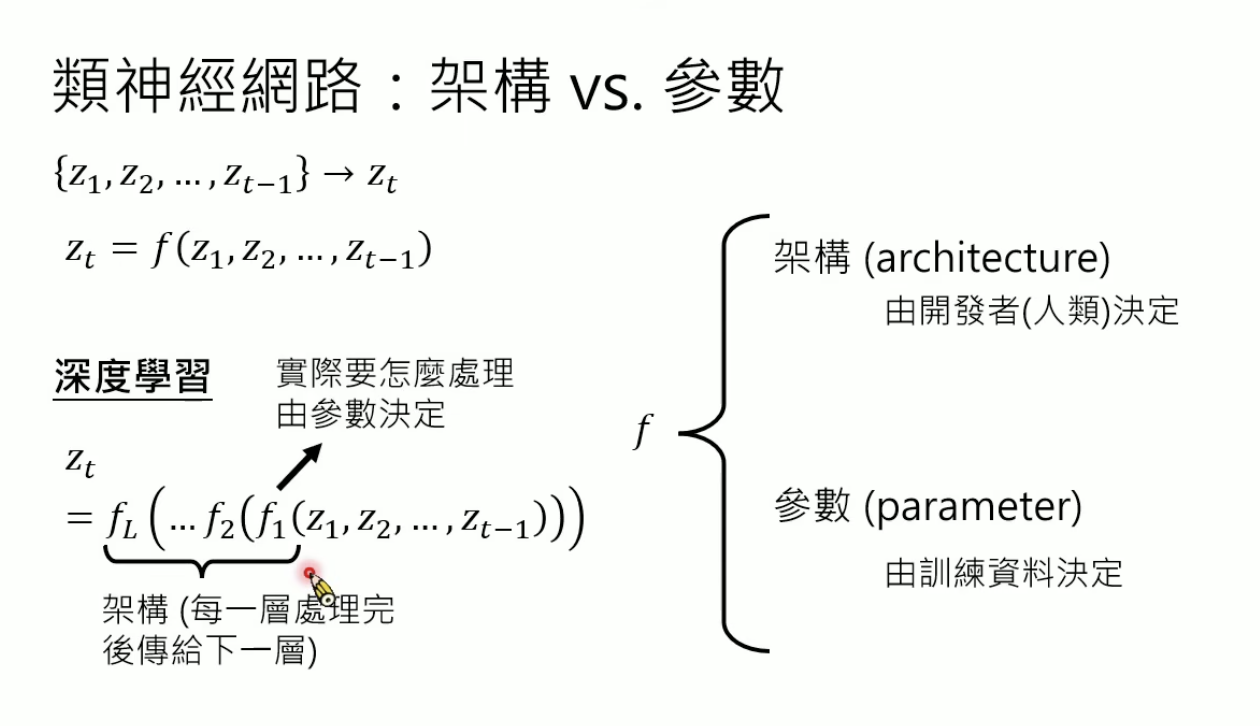
架构是“天资”,如Transformer就是一种架构,也被称为“超参数” hyperparameter
7b,70b模型,指的是参数的数量,b是billion,在f里用下标theta表示
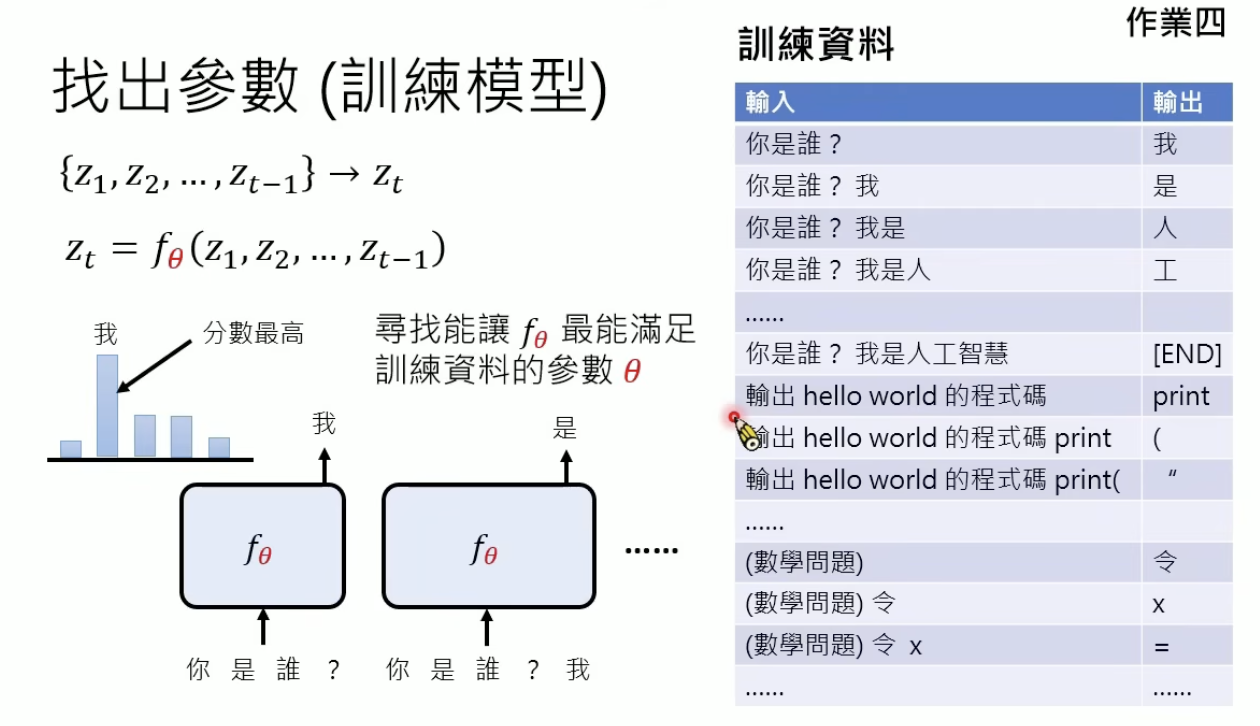
参数数量是架构的一部分,参数数值需要通过训练资料学习
不同语言可以共用模型吗?—通用翻译,先变成“内部语言”,再翻译成另一种语言,可能会自己会从来没见过的语言对
不同任务可以共用模型吗?—给“任务说明”即可,经历三个阶段的发展:特化模型、微调参数、不用管直接用
This post is licensed under CC BY 4.0 by the author.