程序与进程,fork()、execve()、_exit()
程序与进程
程序描述了“配方”“步骤”“指令”,它本身就是一串字节序列,当它真正运行起来,就变成了进程process
一个程序可以有多个进程
当程序运行起来,操作系统就会给它分配一些资源
也就是说:程序是语义 (状态机) 的静态描述
- 描述了初始状态和迁移规则
- 程序运行起来,就成了进程 (进行中的状态机实例)
- (同一个程序可以同时运行多份)
程序通过两种主要方式获取信息:
- 直接通过系统调用(如getpid、prctl…)
- 读取/proc/self/虚拟文件系统中的信息
进程管理API
在操作系统初始化时,会创造“一号进程”process#1(假设我们叫它init,pid=1),而这个“一号进程”孵化出了所有东西
操作系统 = 状态机的管理者
进程管理 = 状态机管理
创建状态机:spawn(path, argv)
操作系统内部会多出一个新的进程,pid=2,ppid=1
unix的答案:fork()
把状态机的状态原封不动地复制一份(内存、寄存器现场)
1
2
3
4
5
原始状态机
|
fork()
/ \
父状态机 子状态机
我们看个简单的例子🌰:
1
2
3
4
5
6
7
8
9
int x = 1;
pid_t pid = fork();
if (pid == 0) {
x = 2;
printf("子进程 x=%d\n", x);
} else {
x = 3;
printf("父进程 x=%d\n", x);
}
输出可能就是:
1
2
父进程 x=3
子进程 x=2
也就是说,对于fork()创建的进程,
- 内存是独立的(COW 机制优化前是完整拷贝,现代 Linux 使用 Copy-On-Write)
- 父子进程各自修改自己的变量,不影响对方
- 栈与寄存器独立
- 父子进程执行到 fork() 后的下一条指令同时存在两个独立的执行路径
两条路之后各自运行,但共享部分资源(文件、信号等)会影响对方。
立即复制状态机
- 包括所有状态的完整拷贝
- 寄存器 & 每一个字节的内存
- Caveat: 进程在操作系统里也有状态: ppid, 文件, 信号, …
- 复制失败返回 -1
如何区分两个状态机?
- 新创建进程返回 0,父进程返回“子进程 PID”(大于 0)
- 执行 fork 的进程返回子进程的进程号——“父子关系”
进程树 — 孤儿进程
进程的创建关系形成了进程树
- A → B → C,如果 B 终止了……C 的 ppid 是什么?
B 退出时:
- 内核会检查 B 的子进程(这里是 C)
- C 不会失去父进程,而是被 init 或类似的守护进程收养
- 在现代 Linux 上,这个进程是
systemd - 在传统 Unix 上,这个进程是
init(PID 1)
- 在现代 Linux 上,这个进程是
C 的 ppid 被改写为 1(init):
- 也就是所谓“孤儿进程被收养”
- 内核保证 C 不会成为无主进程
SIGCHLD 信号的角度
- 父进程(B)退出之前,内核会给 B 发送 SIGCHLD 信号,以通知它的子进程状态变化
- 但是 B 已经终止,信号无法送达
- 所以,如果简单地“往上提”到 A,是不对的:
- SIGCHLD 只发送给直接父进程,不会沿着祖父链自动转发
fork()的用处
Fork Bomb
核弹链式反应!
1
2
3
while (1) {
fork();
}
fork()的全量内存快照:应用
共享信息预处理
- 计算 prime_table,然后 fork 进程分段处理
- 更酷的例子:Android Zygote Process,完成 “冷启动”
并行搜索
- Depth-first search 中,为每个分支创建一个进程
沙箱隔离
- 定期做一个 checkpoint,如果程序 crash 了就从 checkpoint 恢复
fork-based DFS:我们使用深度优先搜索,总是需要维护当前的 “搜索状态”。通常这是通过将状态作为参数传递实现的 (当然,也可以用维护全局状态的方式实现)。借助 fork(),我们可以在每个搜索分支创建一个当前状态的快照,实现并行搜索。
1
2
3
4
for (int i = 0; i < 2; i++) {
fork();
printf("Hello\n");
}
会打印出6次Hello
我们展开程序,把程序看成状态机:
- i = 0
- fork()
- printf()
- i = 1
- fork()
- printf()
- i = 2
我们说,fork()是一个进程完整的状态复制,所以,我们可以来看看下面这个状态图
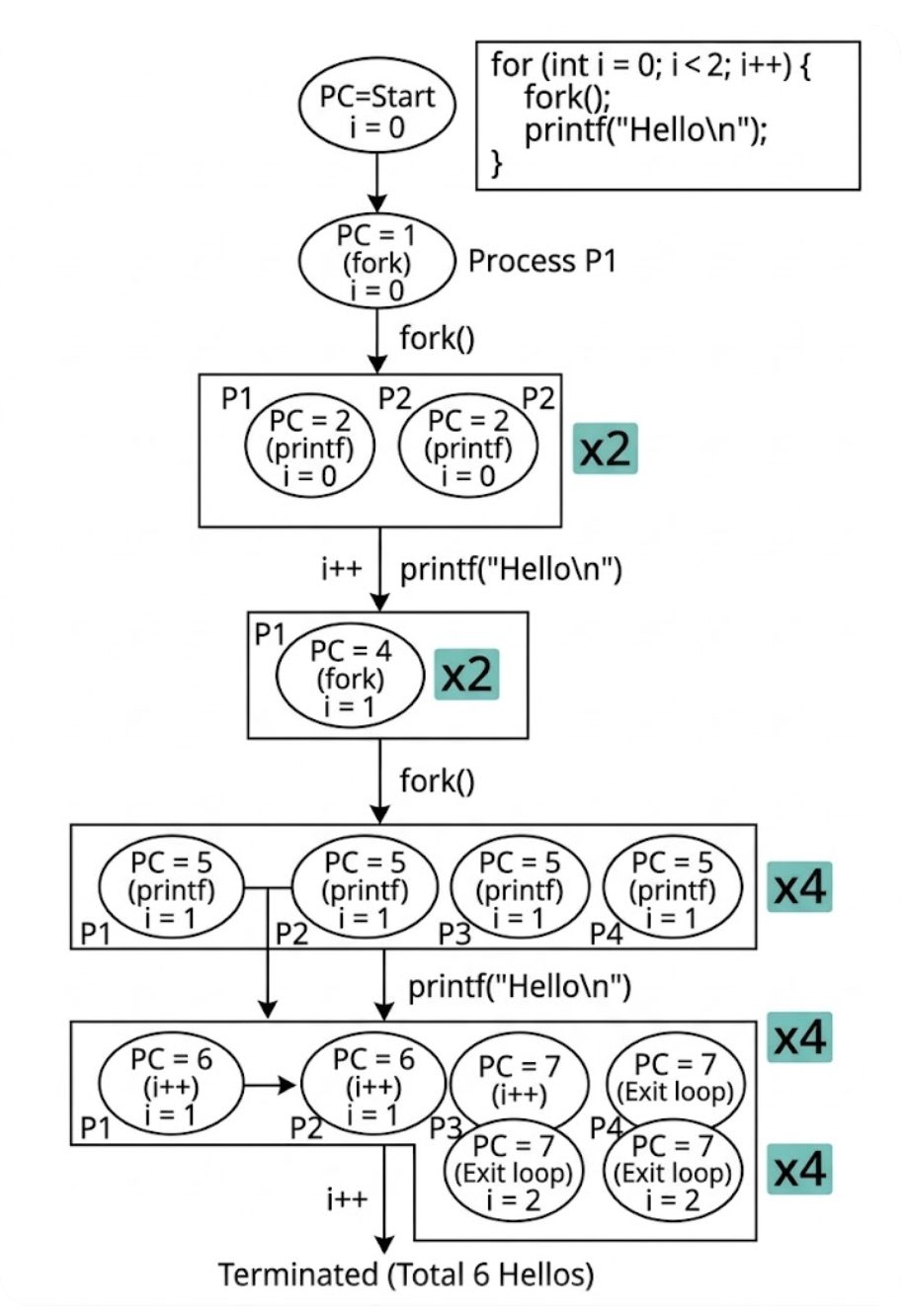
甚至我还运行了这个程序,以证明我的正确性。可是!这个8是…我瞎了吗?

我们一步一步来拆解原理!
在write()和printf()之间,还有一层库函数:
1
printf → libc缓冲区 → write系统调用 → 内核 → 终端/文件
我们来看这样一个例子:
1
2
3
4
5
6
7
#include <stdio.h>
#include <unistd.h>
int main() {
printf("Hello\n");
*((int*)0) = 1;
}
显然,会输出一个Hello,然后再报段错误,对吧?
1
2
3
heyween@heyiwendeMacBook-Pro code % gcc hello.c && ./a.out
Hello
zsh: segmentation fault ./a.out
当然!
但是,如果我只改一点点…
1
printf("Hello");
改成这样,你会发现

“哥们,我的Hello被你吃掉了吗?!”
这是因为libc里有一个缓冲区,默认是line buffer,一旦看到换行,就会执行write系统调用,把缓冲区里的东西写出去;但是如果标准输出是一个文件、管道…它会更aggressive地缓冲,直到缓冲区有足够多等待输出的,这样输出次数更少,性能更高。
所以!所以!fork() 不仅复制变量,还会复制 libc 的缓冲区!
回到这个例子,当我执行./a.out | wc -l的时候,stdout就变成了管道pipe,libc的策略也就变了!
1
stdout → 全缓冲(block buffered)
即使有\n,也不会立刻flush!
这样的后果,就是buffer被fork复制了!父子进程都带着一份 "Hello\n" 在缓冲区里!只有程序运行到结束的时候,4个进程会带着"Hello\nHello\n",通通flush!
execve()
1
2
int execve(const char *filename,
char * const argv[], char * const envp[]);
UNIX 选择只给一个复位状态机的 API
- 将当前进程重置成一个可执行文件描述状态机的初始状态
- 操作系统维护的状态不变:进程号、目录、打开的文件……
execve 是唯一能够 “执行程序” 的系统调用
- 因此也是一切进程 strace 的第一个系统调用
execve做了什么事情呢?
假设执行完fork()后,有A和A’,我们对A’执行execve(),他就会做两件事情:
- 让旧程序完全消失
- 让新程序从main()开始执行
当我执行:
1
./a.out hello world
实际上,内核在 execve 时做了:
1
2
3
4
在新进程的栈上布置:
argc = 3
argv = ["./a.out", "hello", "world", NULL]
envp = [...]
然后才把控制权交给用户态入口
envp: 环境变量
- 使用 env 命令查看
- PATH, PWD, HOME, DISPLAY, PS1, …
- export: 告诉 shell 在创建子进程时设置环境变量
而C程序运行的真实流程是:
1
2
3
4
5
_start(程序真正入口)--> _start是用户态入口
↓
libc 初始化(栈、环境、构造函数等)
↓
调用 main(argc, argv, envp) --> libc调用main,并且传递argc、argc、envp参数
也就是说,程序的初始状态并不是 main,而是 execve 创建的新进程状态。argc 和 argv 在这个状态中已经由内核构造好,main 只是接收这个状态并开始执行。
_exit()
1
void _exit(int status);
- 立即摧毁状态机,允许有一个返回值
- 返回值可以被父进程获取
【不过有了线程以后,就有了两种退出方式 (exit, exit_group)】