整数运算
算术逻辑单元ALU

算术逻辑单元(ALU) 是计算机实际完成数据算术逻辑运算的部件
数据由寄存器(Registers) 提交给ALU,运算结果也存于寄存器
ALU可能根据运算结果设置一些标志(Flags),标志值也保存在处理器内的寄存器中
控制器(Control unit) 提供控制ALU操作和数据传入送出ALU的信号
全加器
注意:加法器实现的是模 2n 无符号整数加法运算
三个输入,两个输出
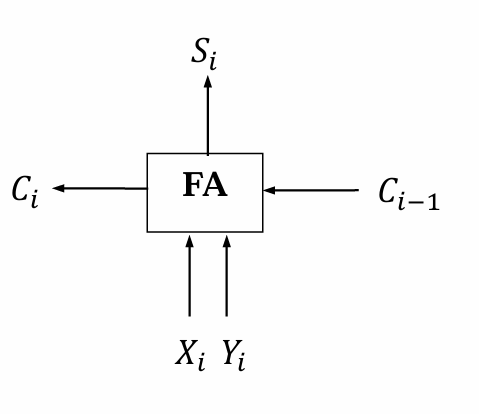
计算方法:
\[S_i = X_i ⊕Y_i ⊕C_{i-1}\] \[C_i = X_iY_i~ + X_iC_{i-1} +Y_iC_{i-1}\][!NOTE]
与门延迟:1级门延迟(1ty)
或门延迟:1级门延迟(1ty)
异或门延迟:3级门延迟(3ty)
注意:下一级X和Y的异或运算可以在上一级还没结束时就开始进行!
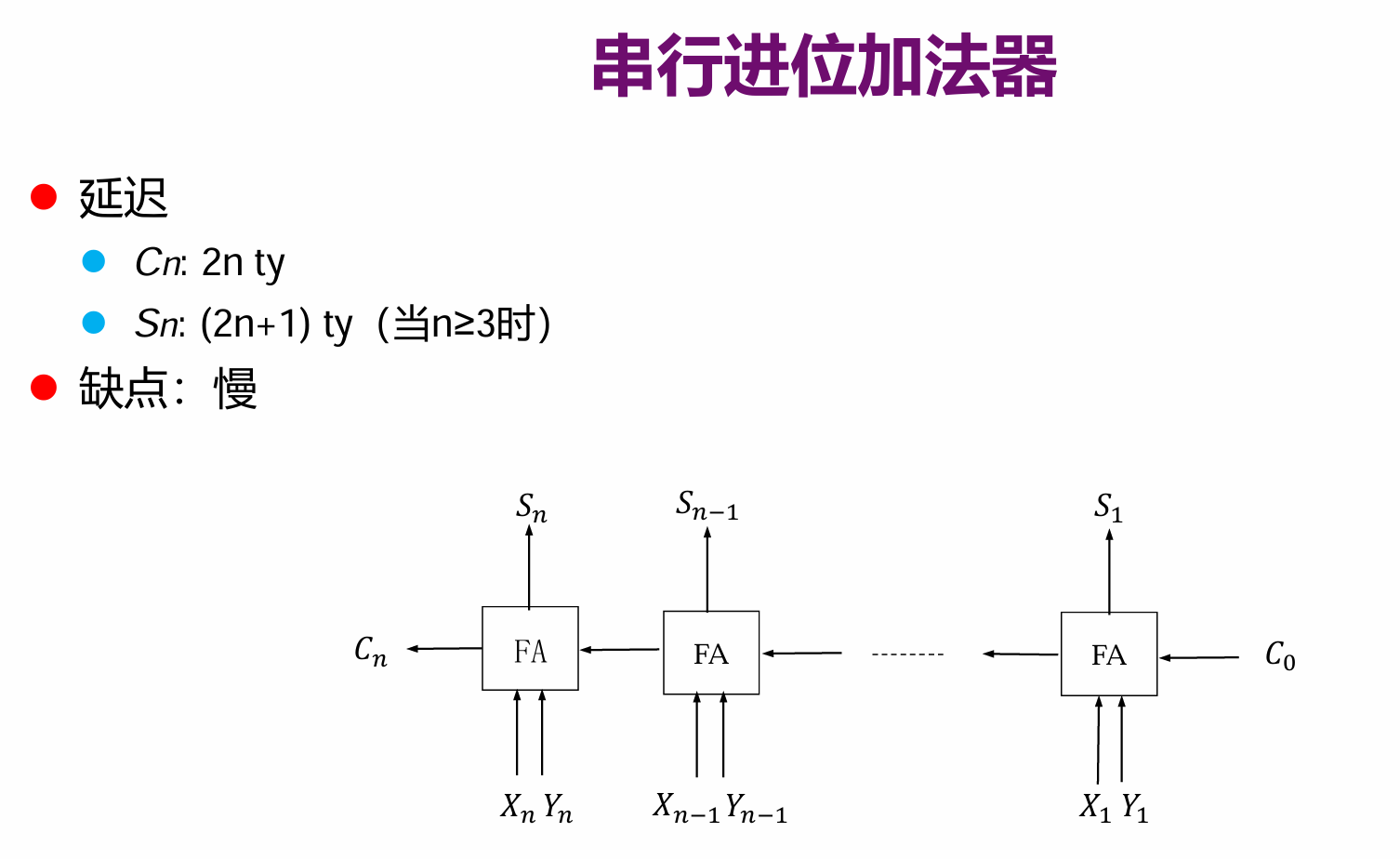
可是,64位的电脑比32位的在进行加法时会慢一倍!这是不可容忍的!
全先行进位加法器
把所有的\(C_i\)先行求出来,这样就不会有那么高的延迟了

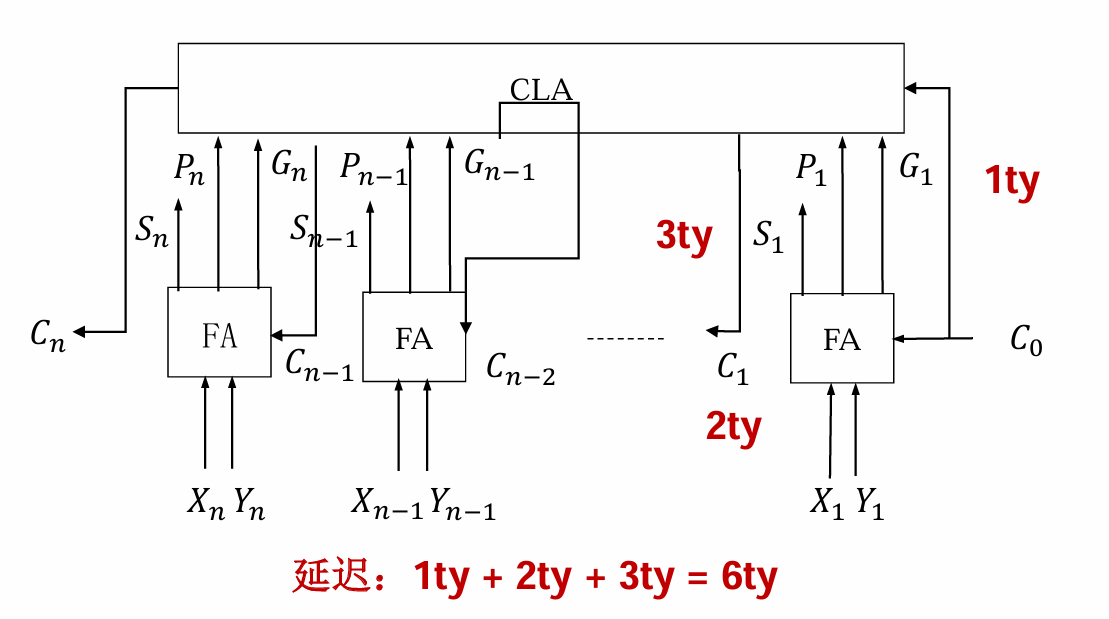
缺点:复杂
部分先行进位加法器
采用多个CLA并将其串联,取得计算时间和硬件复杂度之间的权衡
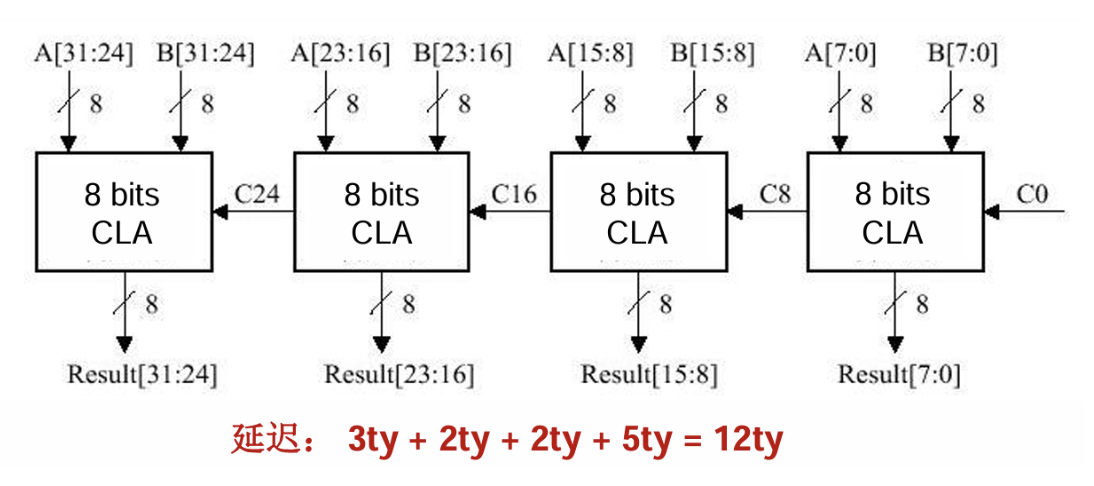
- 8n位加法,串联n个8-bit的CLA
- 第一个计算出给下一个的C8需要:1+2=3 ty,Si不与后续元件相关,时间忽略
- 此后每一个的Gi,Pi都预先算好,计算出给下一个的C8i需要2 ty
- 最后一个计算出C8n需要2 ty,S8n需要3 ty
- 因此共需2n+4 ty
- 例如32位就是12 ty
此部分引用来源:南软佛脚玩乐指南
加法

解释:
方法1:两个负数相加是负数/两个负数相加是正数!
方法2:实际上是方法1经过化简得到的,也可以通过列表法得到
| 情况 | Xn | Yn | Cn−1 | Cn | Sn | 结果解释 | 溢出? |
|---|---|---|---|---|---|---|---|
| 1 | 0 (正) | 0 (正) | 0 | 0 | 0 | 正+正=正 | 无 |
| 2 | 0 (正) | 0 (正) | 1 | 0 | 1 | 正+正=负 | 有 |
| 3 | 1 (负) | 1 (负) | 0 | 1 | 0 | 负+负=正 | 有 |
| 4 | 1 (负) | 1 (负) | 1 | 1 | 1 | 负+负=负 | 无 |
| 5 | 0/1 | 1/0 | 0/1 | - |
减法
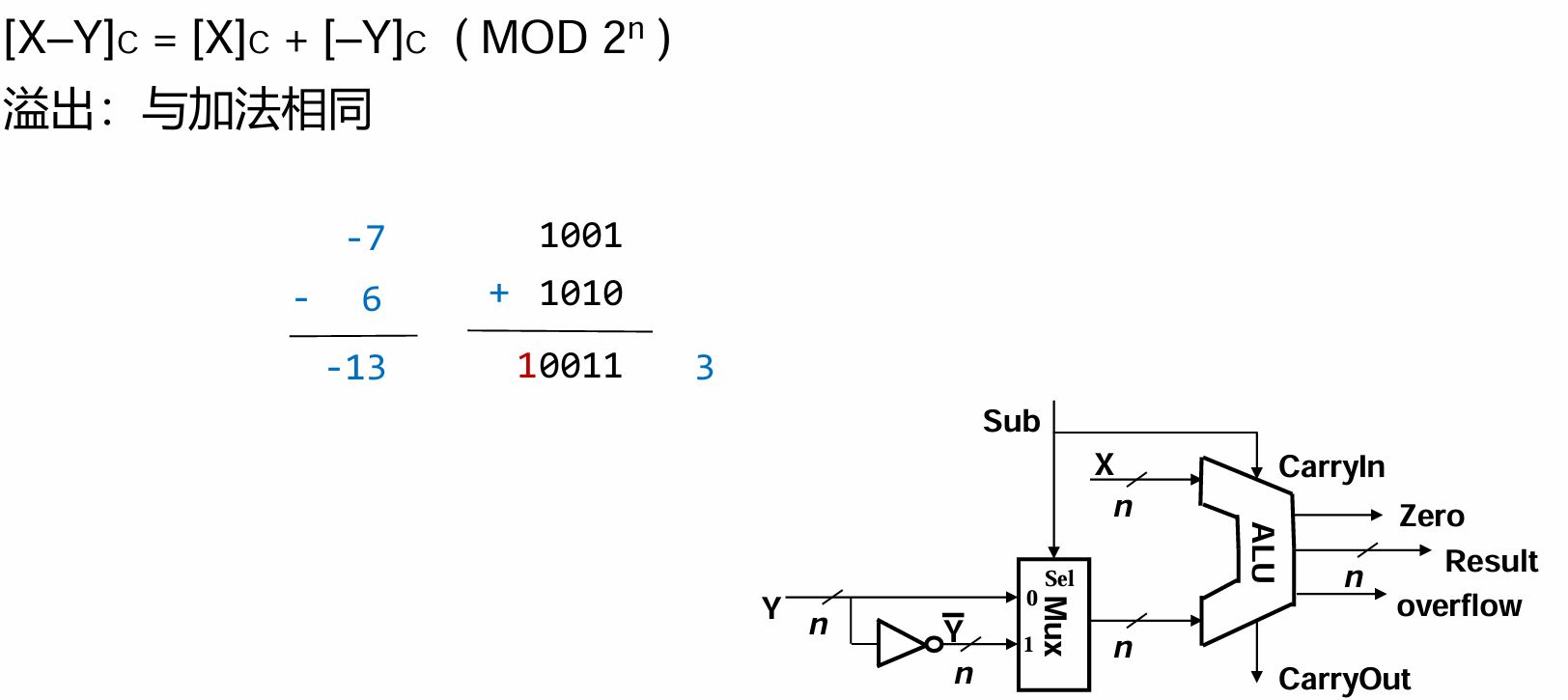
将Y进行非运算,再搞一个“1”进来,不就完成了减法操作吗?!
那么“1”怎么搞进来呢?—那个看似毫无存在感的C0!将它设置成1就可以了!
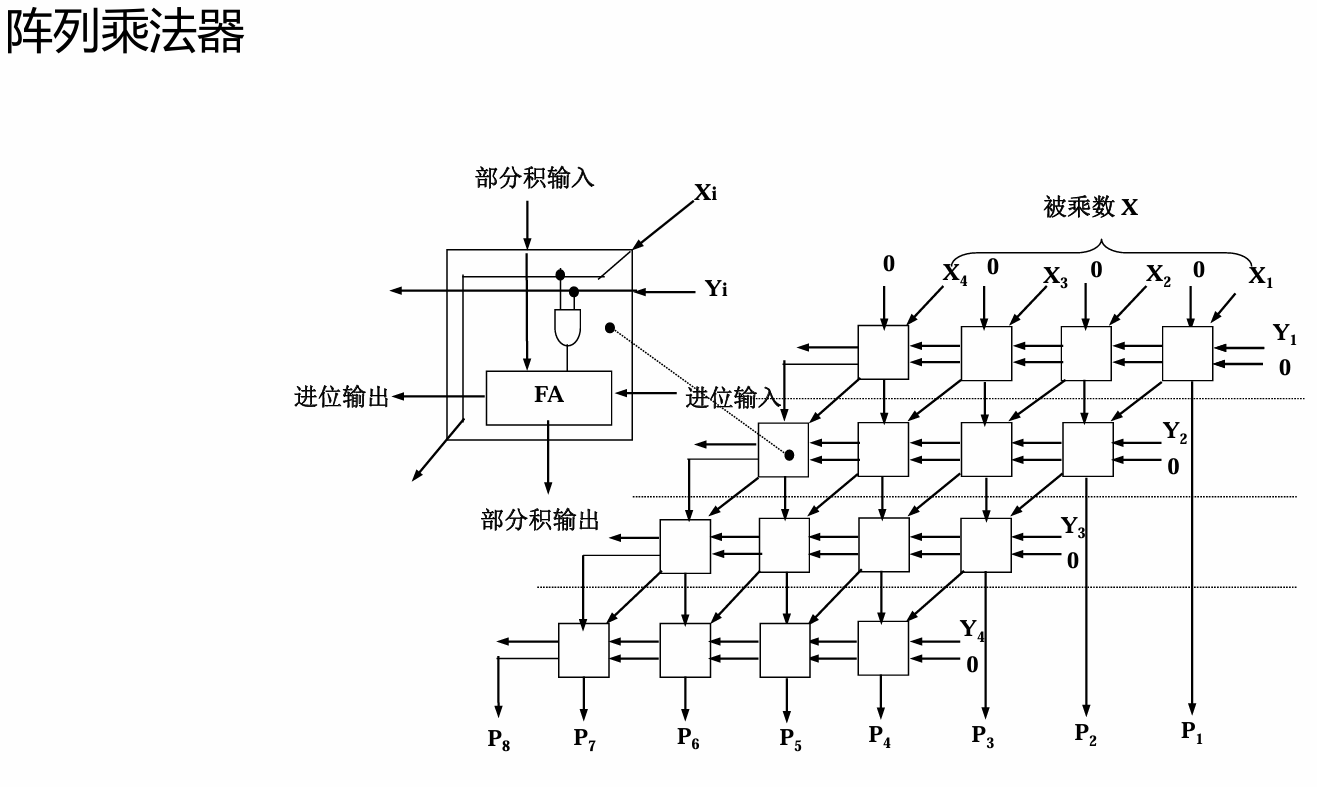
乘法
无符号数:
31次的32位相加!
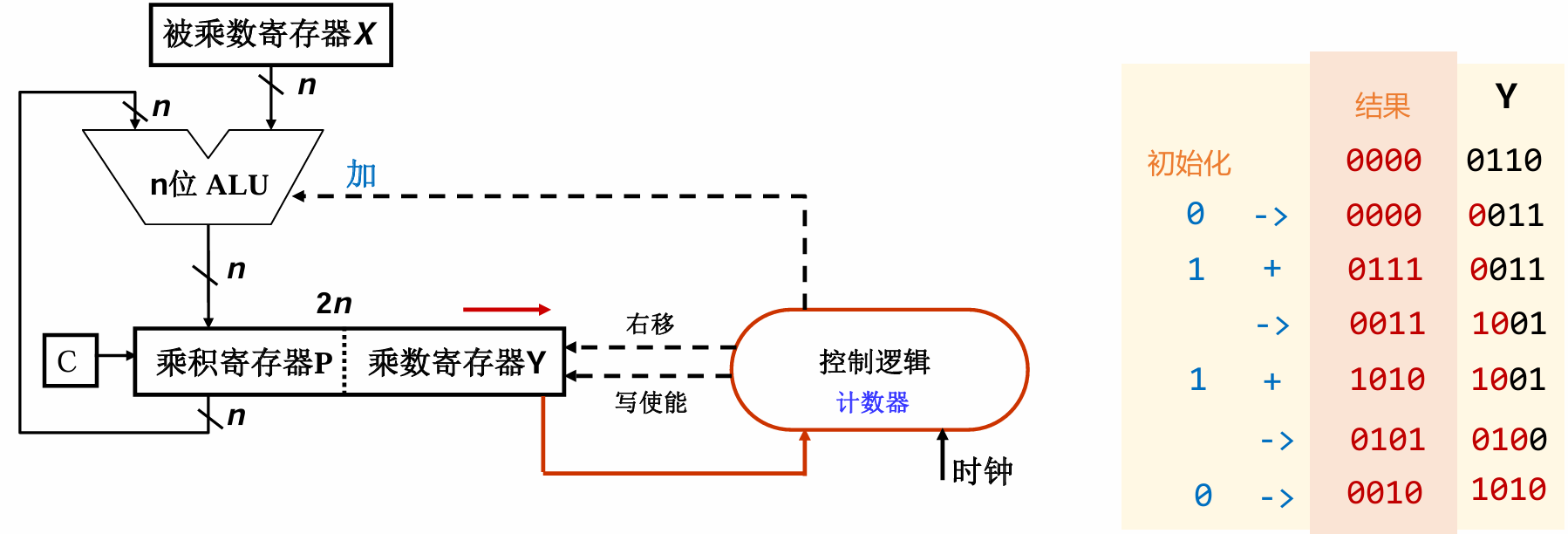
如果是0,直接右移;如果是1,加上被乘数再右移
补码:
两个数的和的补码=两个数的补码的和,但是对于乘法不适用,可以试试(-7)*(-6)
为什么呢?因为补码的本质是“模运算下的负数表示”。乘法操作会“放大”这个表示系统在符号位上的不对称性,而简单的“补码相乘”无法自动完成模调整,因此会出错。
设 M=2n。
- 如果 A 是负数,则 Acomp=M+A。
- 如果 B 是负数,则 Bcomp=M+B。
现在,我们用补码表示的值相乘:
Acomp×Bcomp=(M+A)×(M+B)(当A, B均为负时)=M^2^+M(A+B)+A×B
我们想要的结果是 (A×B)在 2n位模世界(模 M^2^) 中的正确表示。
- 如果 A×B 是正数,其补码就是它本身。
- 如果 A×B 是负数,其补码是 M^2^+(A×B)。
现在看我们的错误计算结果 M^2^+M(A+B)+A×B。
它比我们想要的结果 M^2^+(A×B)多出了一项 M(A+B)!
直接使用补码表示(即模世界里的无符号值)进行乘法,相当于引入了一个“扭曲”的坐标系。计算结果是在这个扭曲坐标系下的产物,而不是在目标坐标系(乘积的补码表示)下的正确值。
布斯算法
布斯算法要解决的核心问题是“有符号数”(包括正数和负数)的统一、高效乘法问题
- 增加Y0= 0
- 根据Yi+1Yi, 决定是否增加+X, -X, +0
- 右移部分积
- 重复步骤2和步骤3共n 次,得到最终结果
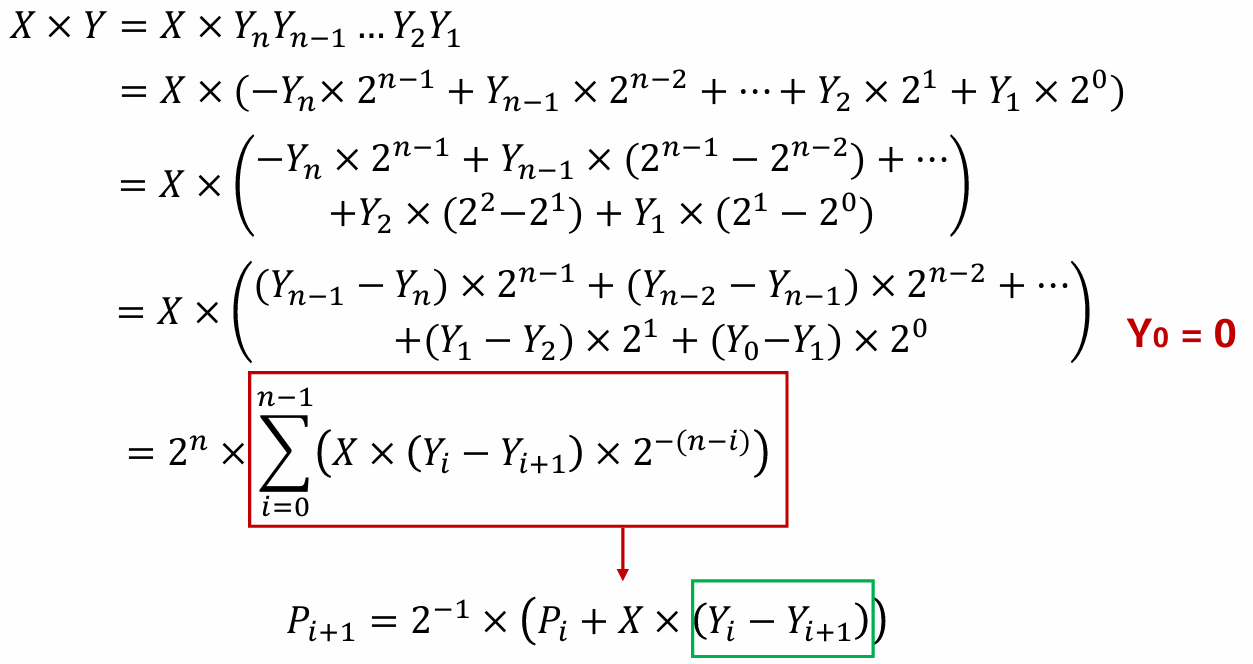
使用布斯算法右移的时候,为什么会算错?(-7)*(-6)会算成106!
因为诸如1101右移不应该变成0100,而是1100!哪有负数右移变成正数的!

个人认为更简单的操作步骤:
- A 寄存器(被乘数寄存器):存放被乘数(Multiplicand)。
- Q 寄存器(乘数寄存器):初始时存放乘数(Multiplier)。
- Q₋₁ 寄存器(辅助位):一个单独的位,初始为0。
- 在算法执行过程中,A 寄存器和 Q 寄存器在物理上是连接在一起的。
- 它们可以共同进行算术右移操作。
- 这个“A寄存器 + Q寄存器”的组合体,就被称为乘积寄存器。
为什么要把它们看成一个整体?
因为最终的乘积结果的位数,是原始操作数(被乘数和乘数)位数的两倍。
- 例如,两个4位的数相乘,会得到一个8位的结果。
A寄存器是4位,Q寄存器也是4位。将它们连接起来,正好是8位(A是结果的高4位,Q是结果的低4位)。操作规则(根据 Q₀ 和 Q₋₁ 的值判断):
Q₀(当前位) Q₋₁(前一位) 操作说明 0 0 连续0:仅进行算术右移 0 1 01序列:A = A + M,然后算术右移 1 0 10序列:A = A - M,然后算术右移 1 1 连续1:仅进行算术右移
- 循环次数 n = 乘数 Q 的位数。
- 而这个共同的位数 n 的选择标准是:它必须大于等于能表示被乘数 M 和乘数 Q 各自所需的最小位宽中的较大者。
除法
不同情形的处理
- 若被除数为0,除数不为0:商为0
- 若被除数不为0,除数为0:发生“除数为0”异常
- 若被除数、除数均为0:发生“除法错”异常
- 若被除数、除数均不为0:进行进一步除法运算
先问一个问题:(-7)/3的答案是-2余-1还是-3余2?
前者!!!!计算机的视角里,做除法是让被除数的绝对值不断变小的过程,余数必须和被除数符号一样!!!
读者可以利用C语言自己试试
注意,编程语言亦有区别!
- 向零取整 (Truncate toward zero):让商向零的方向舍入。这是 C、C++、Java 等语言采用的方式。按照这种方式,
(-7) / 3的商是-2,余数是-1。这符合你的第一种想法。- 向下取整 (Floor toward -∞):让商向负无穷的方向舍入。这是 Python、Ruby、Haskell 等语言采用的方式。按照这种方式,
(-7) / 3的商是-3,余数是2。
无符号数
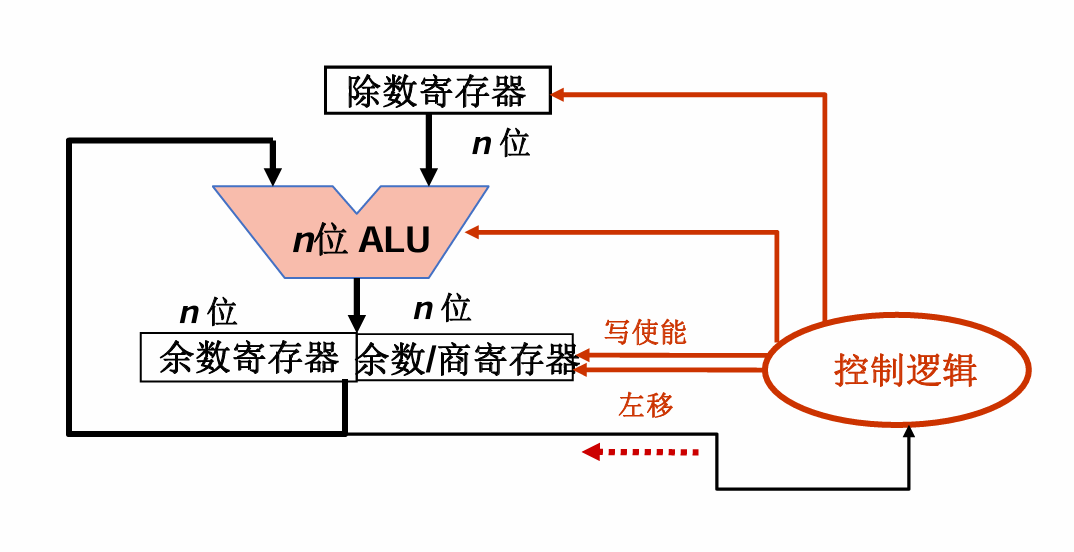

补码
在无符号数的除法中,我们判断“够不够减”很简单:直接比较被除数(或部分余数)和除数的大小。
但在补码有符号数的除法中,问题变复杂了:
- 数字有正有负。
- 部分余数(R)在计算过程中也可能在正负之间摆动。
- 我们不希望在每一步都去做一个复杂的、包含正负号的绝对值比较电路,这很低效。
解决方案是:我们不再关心余数和除数的绝对大小,而是只关心它们的符号关系。 这套规则的设定,就是为了确保我们总能朝着使余数绝对值减小的方向操作。
如何判断“够减”:余数是否足够“大”
如果余数和除数的符号相同:减法 如果余数和除数的符号不同:加法
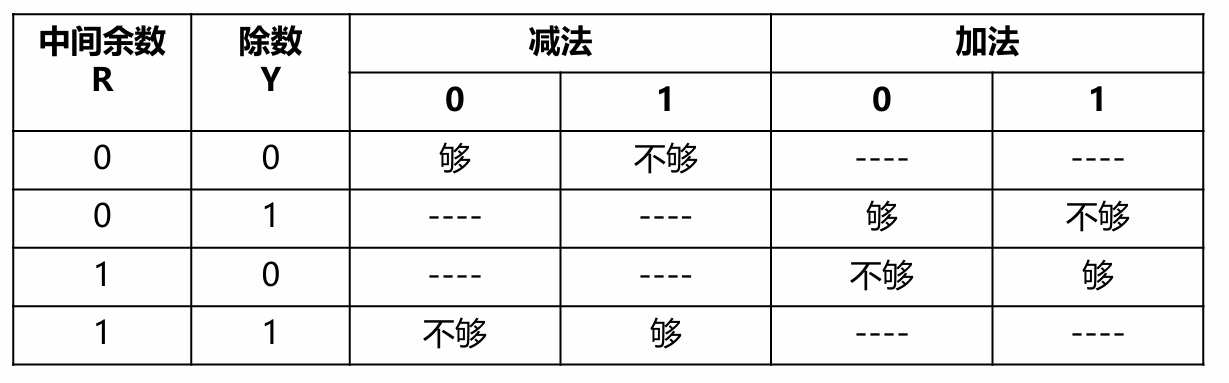
(R在前,Y在后)
步骤过程
通过在前面加n位符号扩展被除数,并存储在余数寄存器和商寄存器中 将余数和商左移,判断是否“够减” • 如果“够”,则做减法(同号)或者加法(异号),并上商为1 • 如果“不够,则上商为0 重复以上步骤 如果除数和被除数不同号,则将商替换为其相反数 余数存在余数寄存器中
恢复余数

不恢复余数
思路:无论够不够减都继续,后一轮执行时根据商的结果进行加/减
- 若上一位“够减”:“减”
- 若上一位“不够减”:“加”(移位后,上一次多减的Y相当于要补2Y,此时加Y等效于恢复余数除法中的−Y
| 项目 | 恢复余数除法 | 不恢复余数除法 |
|---|---|---|
| 原理 | 每次减出负数后恢复 | 负数不恢复,下次用加法修正 |
| 硬件复杂度 | 简单但需要额外一次加法 | 更高效(减少恢复操作) |
| 性能 | 较慢 | 较快 |